Thrilled to see Reachy Mini take center stage at @nvidia CES Keynote! 🤩
Paired with DGX Spark, it's the ultimate toolkit to build personal, private agents that are useful in the real world. 🤖
@NaderLikeLadder and @alecqfong created this incredible demo showing how Brev can tie together model APIs with private computing to make agents that listen to you and get your dog off the couch! 🐶
Link to the demo in thread to build it yourself - even if you don't have your Reachy Mini or DGX Spark yet
@jedisct1 Yep, CPU and network heavy workloads like Xet file reconstruction at @huggingface proved to perform poorly as WebAssembly workloads compared to containers.
🧵(2/2) With inference-benchmarker you can:
🧪 Simulate real workloads (chat, code-gen...)
📊 Measure throughput, time-to-first-token, inter-token latency
⚙️ Compare performance across backends & infra
👉 Check it out: https://t.co/TJSY4BPmYu
🧠 LLM inference isn’t just about latency — it’s about consistency under load. Different workloads, configs, and hardware = very different real-world performances.
At Hugging Face 🤗 we built inference-benchmarker — a simple tool to stress-test LLM inference servers.
🧵 (1/2)
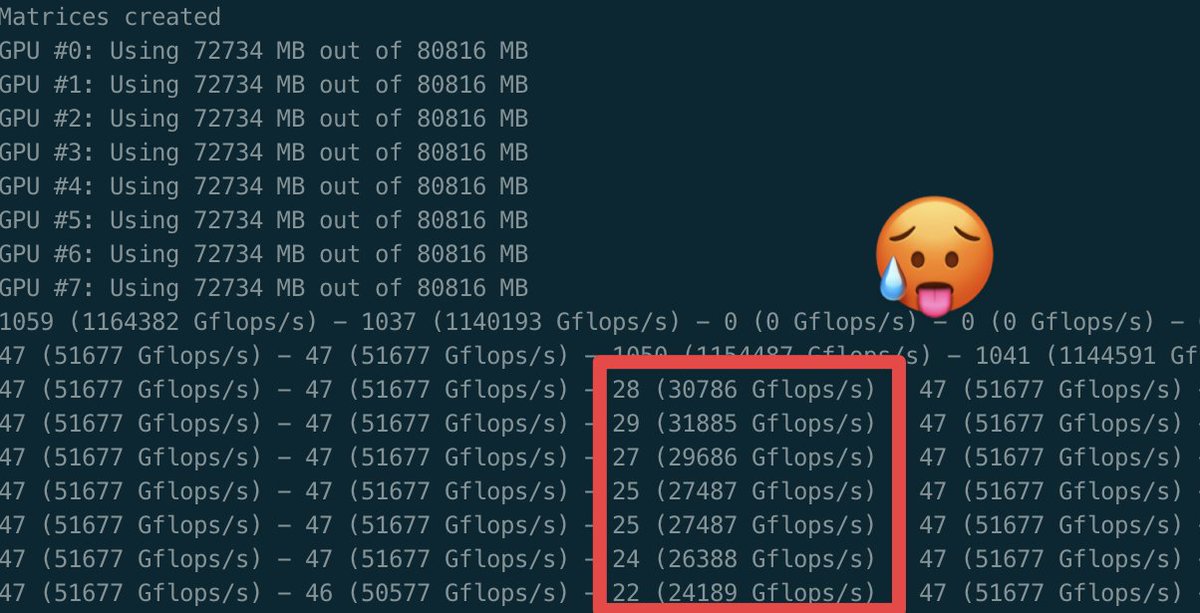
At @huggingface we rely on GPU-fryer 🍳 to load-test our 768 H100 GPU cluster. It runs matrix multiplications and monitors TFLOPs outliers to catch any software or hardware throttling — often a sign of cooling issues that need a hardware fix ❄️🔧.
🧵 1/2
@huggingface GPU-fryer helps us detect silent throttling failures: one GPU slows down and every other unit ends up waiting, creating a bottleneck 🚦.
Check it out: https://t.co/hRDyZ9LaxB
This first step will very soon be followed by the integration of new backends (TRT-LLM, llama.cpp, vLLM, Neuron and TPU).
We are polishing the TensorRT-LLM backend which achieves impressive performances on NVIDIA GPUs, stay tuned 🤗 !
https://t.co/eGpEvqVM8L
We are introducing multi-backend support in @huggingface Text Generation Inference!
With new TGI architecture we are now able to plug new modeling backends to get best performances according to selected model and available hardware.
Just 10 days after o1's public debut, we’re thrilled to unveil the open-source version of the groundbreaking technique behind its success: scaling test-time compute 🧠💡
By giving models more "time to think," LLaMA 1B outperforms LLaMA 8B in math—beating a model 8x its size. The full recipe is open-source🤯
This is the power of open science and open-source AI! 🌍✨
We're turning @huggingface Hub's files into content-defined chunks to speed up your workflows!⚡️
This means:
- 🧠We store your file as deduplicated chunks
- ⏩ You only upload changed chunks when iterating!
- 🚀 Pulling changes? Only download changed chunks!
Interested in 4D parallelism but feeling overwhelmed by Megatron-LM codebase? We are currently cooking something with @Haojun_Zhao14 and @xariusrke 😉
In the meantime, here is a self-contained script that implements Pipeline Parallelism (AFAB + 1F1B) in 200 LOC 🧵👇