Interested in 4D parallelism but feeling overwhelmed by Megatron-LM codebase? We are currently cooking something with @Haojun_Zhao14 and @xariusrke 😉
In the meantime, here is a self-contained script that implements Pipeline Parallelism (AFAB + 1F1B) in 200 LOC 🧵👇
Introducing Carbon 🧬 a family of open generative DNA foundation models. Carbon-3B matches Evo2-7B while running 250x faster at inference. It can generate new DNA sequences and score the functional impact of mutations, zero-shot.
We borrowed a lot from how modern LLMs are trained, but DNA isn't language. Genomes are noisy, redundant, and shaped by evolution rather than communication. So we adjusted the recipe:
Tokenizer. Most genomic models tokenize at the nucleotide/character level, which blows up sequence length. BPE is the obvious LLM-style fix, but it doesn't behave well on DNA. We use deterministic 6-mer tokens (one token = 6 nucleotides): 6× shorter sequences and cheaper attention.
Training loss. With 6-mer tokens, cross-entropy scores a prediction that gets 5/6 nucleotides right the same as one that's completely wrong. This gets brittle late in training and produces loss spikes. We switch mid-training to a more flexible factorized loss (FNS).
Data. Genomes are mostly sparse, repetitive background. We curate down to a staged functional DNA + mRNA mixture, with every ratio chosen by ablation, like mixing a web corpus, but for biology.
We're releasing the models, training data, training code, evaluation suite, and a demo to play with.
More details in the technical report: https://t.co/RMzFmTAhhT
Demo to play with the model, with a biology primer for our ML friends ;) https://t.co/IcOQq7GKF4
Anyone interested in a CUDA deep dive that makes your workload 25% faster? 🧐
Just published a new blog post on asynchronous CPU / GPU inference: 100% insight, zero slop 😊
To learn how to remove all CPU overhead and use your GPU to the max, just read it 🔥
The DiLoCo team at Google DeepMind and Google Research is proud to release Decoupled DiLoCo, the next frontier for resilient AI pre-training.
Decoupled DiLoCo enables training with datacenters across the world, using heterogeneous hardware, and never halting the system despite hardware failures.
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
Next steps:
- enable the 50,000 models available in inference providers
- enable the 3,000,000 models available on HF
- local free fast inference with llama.cpp
- train and bring your own model!
We don't want a world where you're forced to choose between two or three lookalike models with the same biases, limitations, forced to pay fortunes in tokens even for small tasks and send all your data to the cloud.
We want a world where you have real model choice, options and freedom for your agents. Cloud, local, small, big, specialized, general, English or French, fast or slow, from six months ago or from six seconds ago, from third party or your own!
Let's go!
I trained models across MacBooks using Apple's AirDrop protocol.
grove is a distributed training library for Apple Silicon. Devices discover each other over AWDL, a direct radio link. If there's a shared WiFi network it upgrades to that for speed, otherwise everything goes over the direct link. No router, no cloud, no setup.
grove start <script> -n 4
grove join
You can now pretrain LLMs entirely on the HF Hub 💥
Last week, @OpenAI launched a competition to see who can pretrain the best LLM in under 10 minutes. So over the weekend, I made a little demo to automate this end-to-end using the Hub as the infra layer:
- Jobs to scale compute
- Buckets to store all experiments
- Trackio to log all the metrics
The cool thing here is that everything is launched locally: no ssh shenanigans into a cluster or fighting with colleagues over storage and GPUs ⚔️
All that's left is coming up with new ideas, but luckily Codex can automate that part too 😁
Can I have a job now please @reach_vb 🙏?
A small step for mankind, a massive leap for decentralised training... for agency.
In the space of 9 months, @tplr_ai went from 1.2B -> 72B.
It's never been easy, and has broken everyone on the team multiple times. But I speak for all of us when I say it is the most rewarding thing we have ever done.
We have a fraction of the resources. We don't have the PhDs. But Bittensor shows you it doesn't matter. Innovation happens at the edge. We innovate through scarcity.
The ones who rewrite the rules are never the ones with the most. They're the ones who refuse to accept the limits they were handed.
Bittensor is prophecy. Subnets (@covenant_ai and others) are the tools through which that prophecy is manifested.
Next stop: TRILLIONS.
We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3.
72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely.
1/n
🪣 We just shipped Storage Buckets: S3-like mutable storage, cheaper & faster
Git falls short for everything on high-throughput side of AI (checkpoints, processed data, agent traces, logs etc)
Buckets fixes that: fast writes, overwrites, directory sync 💨
All powered by Xet dedup so successive checkpoints skip the bytes that already exist ➡️
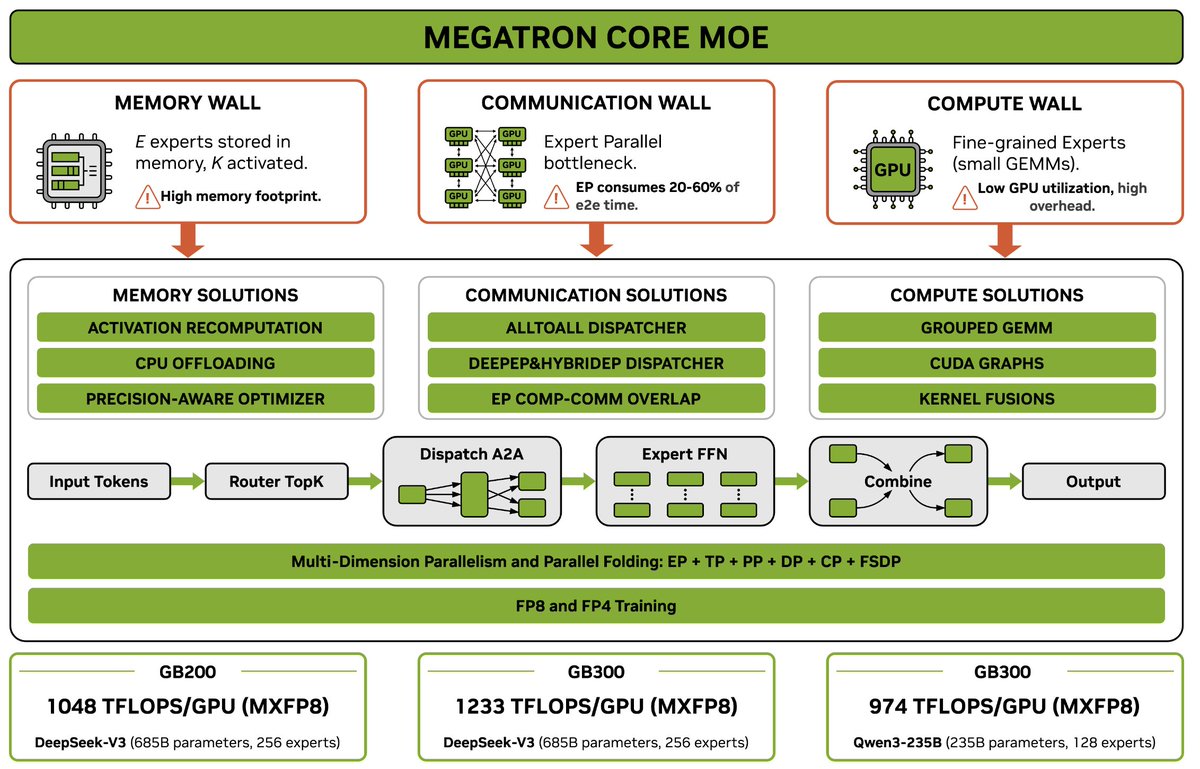
My last open-source project before joining xAI is just out today. Megatron Core MoE is probably the best open framework out there to seriously train mixture of experts at scale. It achieves 1233 TFLOPS/GPU for DeepSeek-V3-685B. https://t.co/QA1KRGu2Nc
there is a game called "data center" on steam which let's you build and manage your own data center.
this is lowkey genius, the best way to educate people on a new trait. hyperscalers should learn a thing or two from "edutainment".
Breaking the Synchronization Bottleneck in Distributed Training with AsyncMesh.
Communication overhead in synchronous data and pipeline parallelism restricts distributed training of large language models to co-located clusters with high-bandwidth interconnects. Our recent work from @Pluralis introduces AsyncMesh, which enables fully asynchronous optimization across both parallelism axes. By eliminating blocking communication, this avoids idle time, improves throughput, and enables efficient utilization of heterogeneous hardware.
Asynchrony, however, introduces optimization challenges due to staleness between PP stages and DP replicas. For PP, we use our prior Nesterov-style weight look-ahead method to compensate for stage-dependent gradient delay. For DP, we introduce asynchronous sparse averaging, communicating only a small subset of parameters, and correcting delay via an EMA-based staleness estimator. We observe that sparse averaging is inherently robust to weight inconsistencies (e.g., staleness and quantization noise), making it well-suited for asynchronous settings while also substantially reducing data transfer between replicas.
Empirically, we observed no performance degradation compared to fully synchronous training across a range of LLM training configurations, while significantly reducing communication overhead. More broadly, AsyncMesh makes distributed training feasible beyond co-located, high-speed clusters, facilitating large-scale collaborative training over the internet.
The attached video illustrates the key concepts of the method and the paper can be found here: https://t.co/1nSUS0y9ri.
Fully Asynchronous Pipeline Parallel + Async SPARTA on the DP axis. Microatches constantly move through through the system, no pipeline bubble or pause while you do an expensive all-reduce. Straightforward to implement. Walltime goes down a lot.
The next session of the @Cambridge_Uni ML Systems Seminar Series (@CaMLSys Lab) is coming up on Monday, Feb 16 at 2:30pm. We are pleased to host @FerdinandMom from @huggingface presenting "Bringing distributed training natively to Transformers library". The seminar will take place in LT1 @Cambridge_CL.
Ferdinand Mom is a Research Engineer at Hugging Face with a background in large-scale pretraining and efficient deep learning systems. He is a contributor to the Hugging Face Transformers library: https://t.co/6swjLSuEQ8 -- and co-author of the Ultra-Scale Playbook: https://t.co/zPlTx5D5tJ. Ferdinand is a leading voice and experimentalist in distributed and decentralized training, pushing the limits of scalable open-source AI.
talks @ cam link: https://t.co/A4lzB3BkI3