People are increasingly worried that AI tools make us overreliant.
But how do we actually measure this? We introduce Offloading Score, a measure of reliance based on the fraction of cognitive effort offloaded to AI while completing a task.
In a controlled user study, Offloading Score detects increased reliance under time pressure, while several common alternatives do not.
(1/9)
New paper! LLM memory keeps improving, but this makes them *worse* as user sims. If we want to build models that can, e.g., simulate realistic students to train chatbots to be better teachers, then these models need to be able to forget like humans do
📄: https://t.co/1GpOfwcsat
New paper! Have you or a loved one been harmed by a bad multiple-choice benchmark? 😔
You may be entitled to a more reliable evaluation 🩺
At #ACL2026, we'll present BenchMarker: a toolkit to diagnose common flaws in MCQA benchmarks, inspired by best practices in education 🧑🏫🧵
🚨 New Paper! 🚨
One of my first Ph.D. papers found that LLMs can answer multiple-choice questions without seeing the question 🤔
At #ACL2026, I'm presenting a follow-up showing that current reasoning LLMs can still do this! And quite similarly to a clever test-taker 🧑🎓🧵
🚀 New paper: FlexSQL — a Text-to-SQL agent that lets gpt-oss reach 65.4% on Spider2, outperforming agents built with large models like DeepSeek-R1 and o3.
The key: just let agent explore flexibly. Don’t collapse a complex query into one schema, one interpretation, and one SQL program too early. FlexSQL keeps multiple grounded solution paths alive, then executes them with the tools/language each path needs.
🧵
Can LLMs generate diverse outputs for open-ended questions? Is it helpful if we ensemble outputs from multiple models? We study 18 LLMs on 4 datasets and find that no single model is best at generating diverse outputs 👇/ 🧵
How should we effectively aggregate long-horizon agent trajectories? 🧐
Unlike CoT reasoning, agentic tasks pose unique challenges: they are long, multi-turn, and tool-augmented.
Introducing 👉🏻 AggAgent 👈🏻 — which treats parallel trajectories as an environment to interact with.
Excited to share MyScholarQA - a personalized deep research tool that learns from your papers and lets you customize reports! 🧑🔬🖌️
Our #ACL2026 paper built and evaluated it, showing simulated users (LLMs) couldn't mimic what real users wanted 🙅
Spicy results + a live demo 👇🧵
Your AI Agent just formed a hypothesis. 💭 How does it validate it?
Not by trying to prove itself wrong. Rather, it selectively seeks evidence that confirms what it already believes, often ending up with the wrong answer!
Confirmation bias isn’t just human. We measure it in LLMs, and we show how to fix it! 🧵
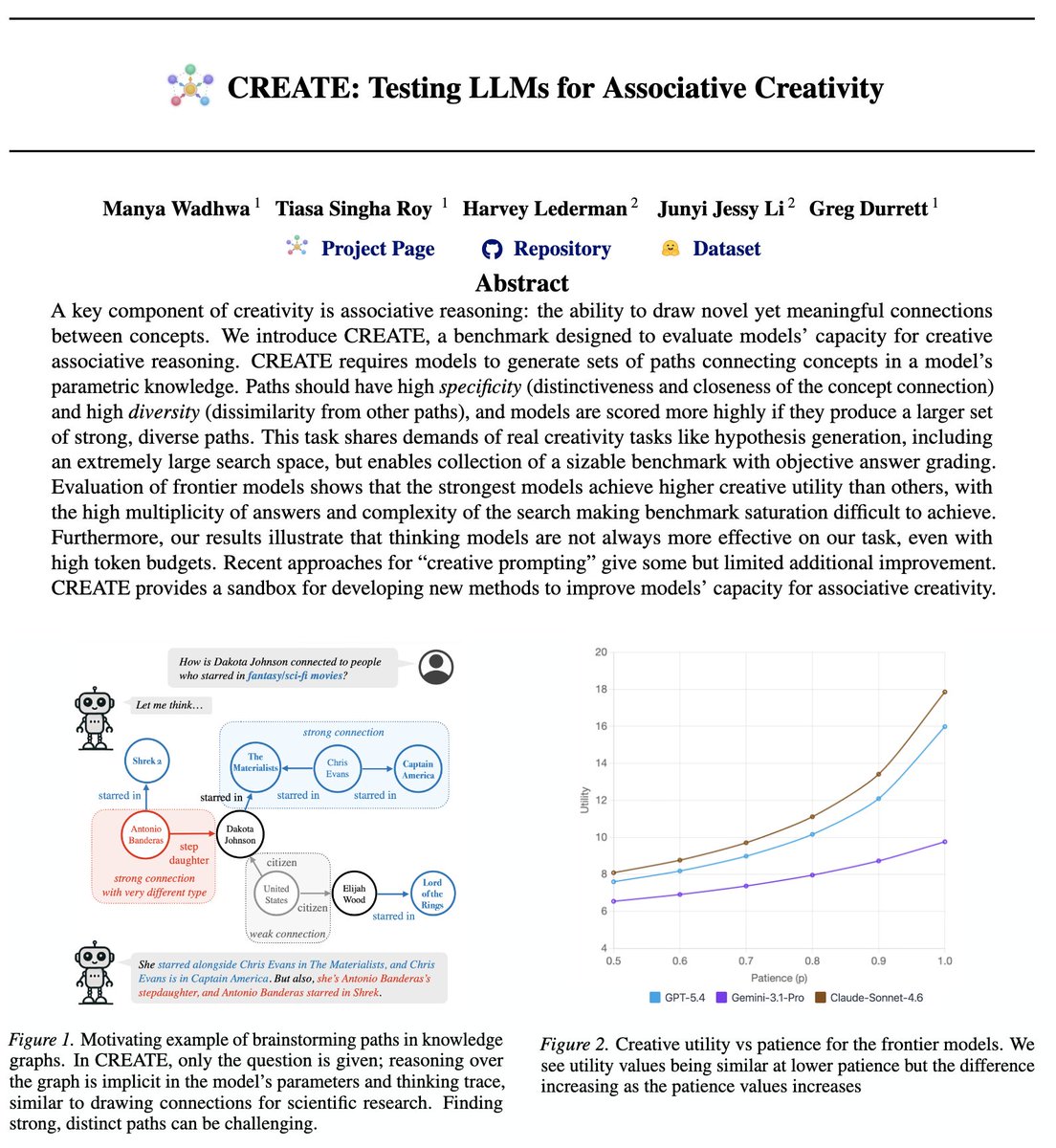
⚛️ Introducing CREATE, a benchmark for creative associative reasoning in LLMs.
Making novel, meaningful connections is key for scientific & creative works.
We objectively measure how well LLMs can do this. 🧵👇
A lot of useful training data can't be shared due to privacy. How do we create synthetic training data without data owners ever sharing their content?
🚀 Introducing 𝐃𝐏-𝐑𝐅𝐓: using RL to train LLMs to generate high-fidelity domain data without seeing a single private sample.
RVR: Retrieve-Verify-Retrieve for Comprehensive Question Answering
@denq1an et al. use an LLM verifier to identify high-quality documents and conditions subsequent retrieval on verified results to maximize answer coverage.
📝 https://t.co/WtoqzHQqLJ
👨🏽💻 https://t.co/mg4b7UXDZg
It was nice collaborating with @denq1an on this project!
Comprehensively retrieving all answers is hard for agentic approaches that are optimized to cover a single answer.
We propose a iterative framework that uncovers new answers based on previously retrieved information.
🚨NEW PAPER🚨
How can we comprehensively retrieve all relevant docs for multi-answer QA? Agentic search doesn't help.
Introducing RVR, an iterative framework that conditions on prior docs to maximize answer coverage.
📈10% answer recall gain on QAMPARI
w/@hungting_chen@eunsolc
Agents interact with environments to gather information. But exploration can be expensive.
Tool use, retrieval, and user interaction carry latency or monetary cost.
Calibrate-Then-Act allows LLM agents to balance exploration with cost:
📐 Estimate uncertainty about the environment
💭 Reason about cost-uncertainty tradeoffs
⚙️ Act accordingly
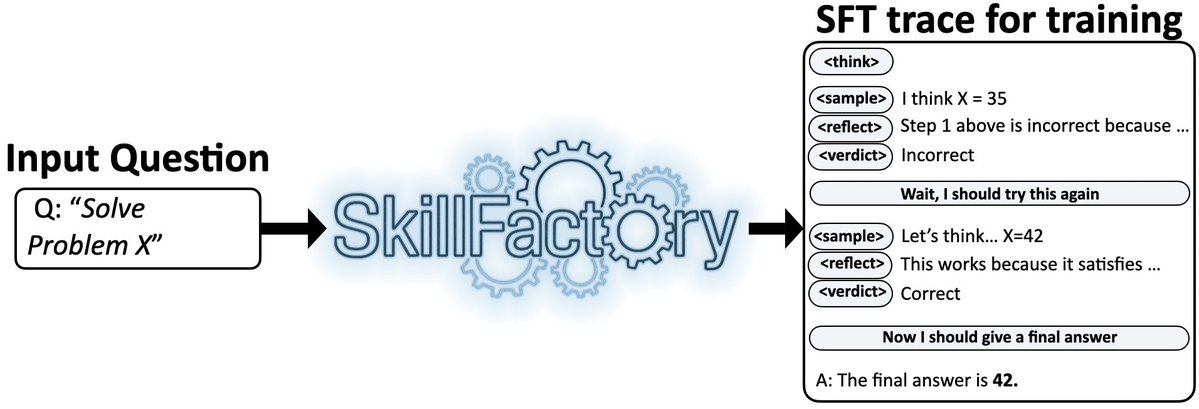
RL amplifies existing behaviors. Let’s prime models w/ good behaviors for better RL!
Introducing SkillFactory:
✂️Rearrange model traces on a problem to demo verification + retry
⚙️SFT on those traces
🦾RL
Result: Learn robust explicit verification + retry across domains 🧵
Can LLMs accurately aggregate information over long, information-dense texts? Not yet…
We introduce Oolong, a dataset of simple-to-verify information aggregation questions over long inputs. No model achieves >50% accuracy at 128K on Oolong!