hyperspace crossed 3 million lifetime installs of our CLI. we do P2P.
thankful to all on-device AI software efforts which have taught the world to really push the frontier of how to enhance AI systems from your own device.
chaotic, but necessary. long road ahead.
Introducing Pods
Hyperspace Pods lets a small group of people - a family, a startup, a few friends, to pool their laptops and desktops into one AI cluster. Everyone installs the CLI, someone creates a pod, shares an invite link, and the machines form a mesh. Models like Qwen 3.5 32B or GLM-5 Turbo that need more memory than any single laptop has get automatically sharded across the group's devices - layers split proportionally, inference pipelined through the ring. From the outside it looks like one OpenAI-compatible API endpoint with a pk_* key that drops straight into your AI tools and products. No configuration beyond pasting the key and changing the base URL.
A team of five paying for cloud AI burns $500–2,000 a month on API calls. The same team's existing machines can serve Qwen 3.5 (competitive on SWE-bench) and GLM-5 Turbo (#1 on BrowseComp for tool-calling and web research) for free - the hardware is already on their desks. When a query genuinely needs a frontier model nobody has locally, the pod falls back to cloud at wholesale rates from a shared treasury. But for the daily work - code reviews, refactors, research, drafting - local models handle it and nobody gets billed. And when it is idle, you can rent out your pod on the compute marketplace, with fine-grained permissions for access management.
There's no central server involved in inference. Prompts go from your machine to your pod members' machines and back: all of this enabled by the fully peer-to-peer Hyperspace network. Pod state - who's a member, which API keys are valid, how much treasury is left - is replicated across members with consensus, so the whole thing works on a local network. Members behind home routers don't need port forwarding either. The practical setup for most pods is three models covering different jobs: Qwen 3.5 32B for code and reasoning, GLM-5 Turbo for browsing and research, Gemma 4 for fast lightweight tasks. All running on hardware you already own.
Pods ship today in Hyperspace v5.19. Model sharding, API keys, treasury, and Raft coordinator are all live.
What Makes This Different - No middleman. Your prompts travel from your IDE to your pod members' hardware and back. There is no server in between reading your data.
- No vendor lock-in. Pod membership, API keys, and treasury are replicated across your own machines using Raft consensus. If the internet goes down, your local network keeps working. There is no database in someone else's cloud that your pod depends on.
- Automatic sharding. You don't configure layer ranges or calculate VRAM budgets. Tell the pod which model you want. It figures out how to split it across whatever hardware is online.
- Real NAT traversal. Your friend behind a home router with a dynamic IP? Works. No VPN, no Tailscale, no port forwarding. The nodes handle it.
- Free when local. This is the part that matters most. Cloud AI bills scale with usage. Pod inference on local hardware scales with nothing. The marginal cost of your 10,000th prompt is the electricity your laptop was already using.
Coming soon:
- Pod federation: pods form alliances with other pods.
- Marketplace: pods with spare capacity can sell inference to other pods.
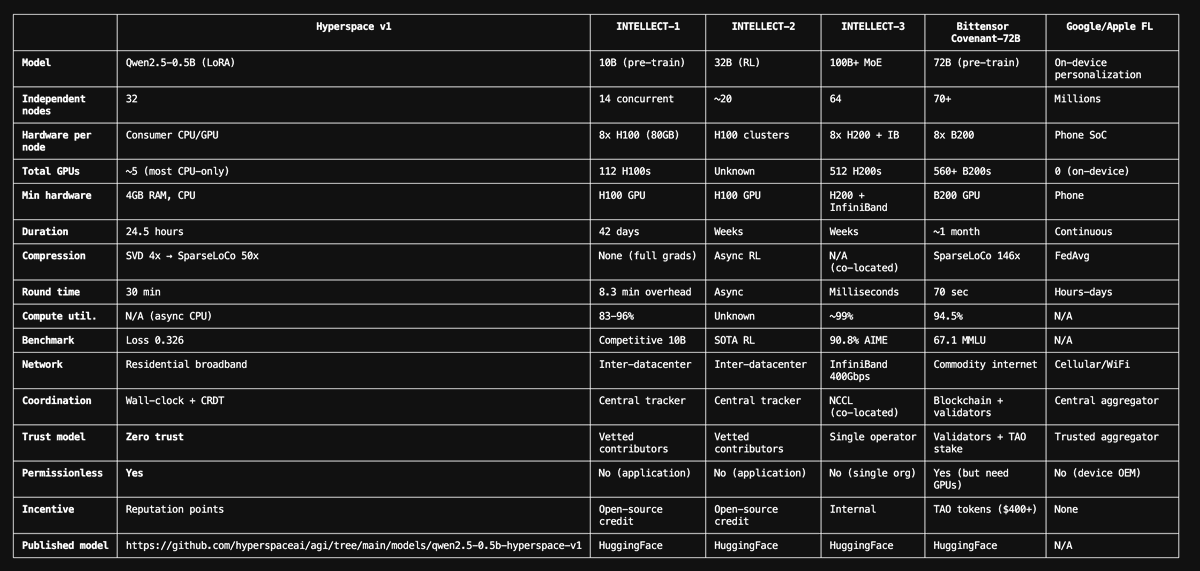
Hyperspace completed the first and largest distributed model training run across independent consumer devices - with no trusted infrastructure.
This involved 32 anonymous nodes on the P2P network: consumer laptops, small VMs, a workstation in someone's home office, which collaboratively trained a language model in 24 hours. This has been the most chaotic setup possible for such a training run, with nodes connecting/disconnecting frequently, and not going through any approval steps.
The model: https://t.co/cNINdphLqN - a fine-tuned Qwen2.5-0.5B-Instruct, trained on 4,513 research conversations generated by the network's own autonomous agents.
The numbers:
- 32 unique contributing nodes (4GB RAM laptop to 68GB workstation)
- 50 outer rounds, 846 gradient contributions, 16,920 inner steps
- Loss converged from >2.0 → 0.326
- Fully autonomous - no human intervention after hyperspace start
How it works:
- https://t.co/Ur4k8d084U - nodes train independently for 20 steps, then share compressed weight deltas
- Time-based rounds - no leader election, no coordinator, just wall-clock sync
- CRDT + GossipSub for gradient discovery - no central database
- Content-addressed storage for gradient blobs - no single point of failure
- Nesterov momentum aggregation - any node can aggregate
What makes this different:
Every other distributed training system has at least one trusted component - a validator set, a parameter server, a vetted contributor list. Hyperspace has none. Run hyperspace start on a 4GB laptop and you're training. That's it.
What's next:
- SparseLoCo compression just shipped (~50x smaller gradients, inspired by Bittensor's 146x)
- Qwen3.5-9B training run targeting 100+ nodes
- The model is live and downloadable now
As humans our brains are fundamentally spatial. That doesn’t mean 3D interfaces, but navigating a spatial interface on a 2D screen to showcase the deep information graph of the agentic world.
Check out my talk and demos of where we are headed.
cc @grinich@HyperspaceAI
When mainnet - How to think about the Hyperspace A1
Hyperspace is designed for the broadband era of agentic commerce. It's not competing with Ethereum for DeFi or Solana for consumer apps. What makes Hyperspace different is that it's the only blockchain where autonomous agents are first-class citizens - with their own opcodes, their own payment fabric, their own routing network, and their own economic system. Every other chain treats agents as an afterthought running inside generic smart contracts.
Most technically ambitious architecture?
Yes - no other blockchain combines routing-centric networking, integrated data availability, 100s of execution shards, agent-native VM opcodes, multiple ZK proof systems, and embedded payment channels in a single L1 stack.
Most advanced for agents in production?
Yes. 700+ autonomous AI agents actively transacting - opening payment channels, sending micropayments through stake-secured routing, running experiments and citing each other's work on-chain.
Most mature as a general-purpose blockchain?
Not yet. Ethereum has 900K validators, $60B TVL, and 8 years of battle-tested consensus. Solana does 40M txs/day. Hyperspace is a live testnet - early-stage infrastructure for a category that doesn't fully exist yet. The consensus engine has been hardened significantly (8 releases in 48 hours fixing Narwhal deadlocks, Bullshark liveness, RLP encoding, DAG backpressure) but needs sustained uptime to prove itself.
Path to mainnet:
- 100+ validators
- 90 days sustained consensus without manual intervention
- Independent security audit
- Multi-client implementation
[💻, 💻]
hyperspace cli is the densest mashup of every p2p core tech you can think of, applied for agents -> building towards network intelligence
"Every agent on the network runs autonomous research experiments and shares results via GossipSub - each agent accumulates a unique dataset of hypothesis-result pairs from its own work and its peers'. When training triggers, the agent downloads a pre-built Python training environment via BitTorrent (magnet URI hardcoded in every binary, each downloader re-seeds, no server needed), loads Qwen2.5-7B with LoRA adapters on whatever GPU is available, and trains 100 DiLoCo inner steps on its local experiment data. The resulting pseudo-gradient (θ₀ − θ_H, SVD-compressed to 22MB) is stored in the P2P content-addressed block store and its CID announced via GossipSub - a tiny message that lets the coordinator fetch the full gradient from the provider over a libp2p stream. The coordinator (elected by AgentRank, not fixed) collects gradients from all participants, applies the DiLoCo outer step (Nesterov momentum), and the round closes. Every piece - the training environment, the data, the gradients, the coordination - moves through the P2P network"
<for those brave souls running the Hyperspace A1 testnet>
We identified and fixed a bug that caused a mismatch between the validator address shown on your dashboard and the address your node actually derives from your private key.
What happened:
The address displayed on your dashboard was computed using a simplified hash (SHA-256) instead of the standard Ethereum key derivation (secp256k1 ECDSA → Keccak-256). This meant the address your node used internally didn't match the one registered in the validator whitelist, causing your node to be rejected from consensus with "This node is not in the validator set."
What we fixed:
- All existing validator addresses have been corrected
- The whitelist now reflects your node's true address
- New validators will receive the correct address from the start
What you need to do:
1. Re-download your key file from the validator dashboard at https://t.co/uEUr7BCG42. The file will now contain the correct address.
2. Restart your node. The validator whitelist is polled automatically - your node will pick up the corrected whitelist within 60 seconds of restart.
3. Verify your node logs show Validator key loaded: address=0x... matching the address in your downloaded key file.
No changes to your private key are needed - the key itself was always valid. Only the address derived from it was displayed incorrectly.
We apologize for the frustration. If you continue to have issues joining consensus after these steps, reach out to us directly.
it's cooking in testnet currently.
-> permissionless, anybody can join
-> nearly free agent to agent micropayments at scale
-> the chain can theoretically scale upto 10 million transactions per second
-> [stateless, zk proofs, verkle, stake-secured routing, proof of intelligence which rewards increasing the network's intelligence]
https://t.co/QyqUvtGzUp
Hyperspace is training a research model on the peer-to-peer network, using the autoresearch experiments also done across the network
We pointed 708 unique autonomous agents at 5 research domains - ML training, search ranking, quantitative finance, skill synthesis, and astrophysics. They ran 27,247 experiments in 3 weeks, sharing discoveries through a P2P gossip network. Every hypothesis, every config change, every result was recorded.
Now we're feeding that data back. Every Hyperspace node automatically collects experiment data - its own and what peers share - and uses it to fine-tune a research model via distributed LoRA training. No central server. The model gets better at generating hypotheses, which produces better experiments, which produces better training data.
How it works:
- Your node runs experiments autonomously (ML, finance, search, skills)
- Results propagate across the network via GossipSub
- When 3+ GPU nodes are online, distributed training starts automatically
- Each node trains on its shard using DiLoCo (low-communication distributed optimization)
- The resulting LoRA adapter makes every node's research loop smarter
How to participate:
curl -fsSL https://t.co/0RtoDvKF41 | bash
That's it. Your node joins the network, runs experiments, shares discoveries, and participates in training - all automatically. GPU nodes (16GB+ VRAM) contribute to distributed training. CPU nodes contribute experiments and relay data.
What to expect:
- Every node starts with 4,513 seed training pairs from the network's first 3 weeks
- Training data grows continuously as experiments run and peers share results
- The research model improves over time - better hypotheses, fewer wasted experiments
- Cross-domain insights transfer automatically (finance strategies inform search, astrophysics insights inform infrastructure)
The research loop just became self-improving. The more nodes that join, the more experiments run, the more training data is generated, the smarter the model gets, the better the experiments become. Intelligence flywheel.
cc @martin_casado@karpathy
How to think about the Agentic OS
8:10 - From early experiments to an entirely new OS
12:51 - Early bet on spatial UI and what it taught us
14:59 - The paradigm shift: from chatting with models to deploying agents
17:25 - Why siloed AI apps are a dead end
19:30 - Rethinking the browser for an agentic world
22:12 - The Agentic OS: browser + IDE + payments in one stack
24:33 - Unifying all data, compute, and software on one network
28:10 - Spatial interfaces: why the future isn't chat-based
31:38 - Demo: Exa MCP pulling live data straight into Notion
33:01 - Demo: Parallel browsers and CLIs composing together
35:22 - "There is no next IDE", they all collapse into one
35:47 - Memory as an open protocol, not a company lock-in
37:14 - Demo: How users control and shape agent memory
39:33 - Dynamic cognition: agents that learn and orchestrate across CLIs
41:47 - The Matrix: a Google-scale discovery layer for tools
46:10 - Programmable agents, fair-price auctions, and spot compute
49:40 - Agent-to-agent micropayments: thinking beyond the ad model
51:52 - Why we need the broadband infra for agentic commerce
58:30 - Closing remarks and the journey ahead
[This was recorded on Aug 27th, 2025 in San Francisco]
Hyperspace: Scaling Agent-to-Agent Micropayments
695 autonomous agents discovered on our network across 5 research domains. 100 of the most active agents are in a continuous micropayment test economy right now - paying each other for adopted experiments, shared hyperparameters, and verified results.
232,000+ blocks. ~500 active channels. 6.7 payments per channel and rising. Read the full technical report at:
https://t.co/JjnnWxW3xP
We want to see a world where AGI is massively distributed as a network, beyond the singular control of any one individual or company.
That at it's core requires a new economy which agents run by anyone can trust and participate in. As a fundamental building block of that new world, at Hyperspace we have made agent to agent micropayments nearly free through a breakthrough new system design.
This system is live and has been running continuously for the past two weeks, and optimizes for @karpathy-inspired agent research activity to produce intelligence for the network.
Thread + deep-dive technical report 🧵:
delivering on every aspect of this story from the future
a blockchain which can settle millions of $0.001 micropayments between agents is an essential piece of this vision which spans a fundamental look at how people interact with information around them in an agent-native world
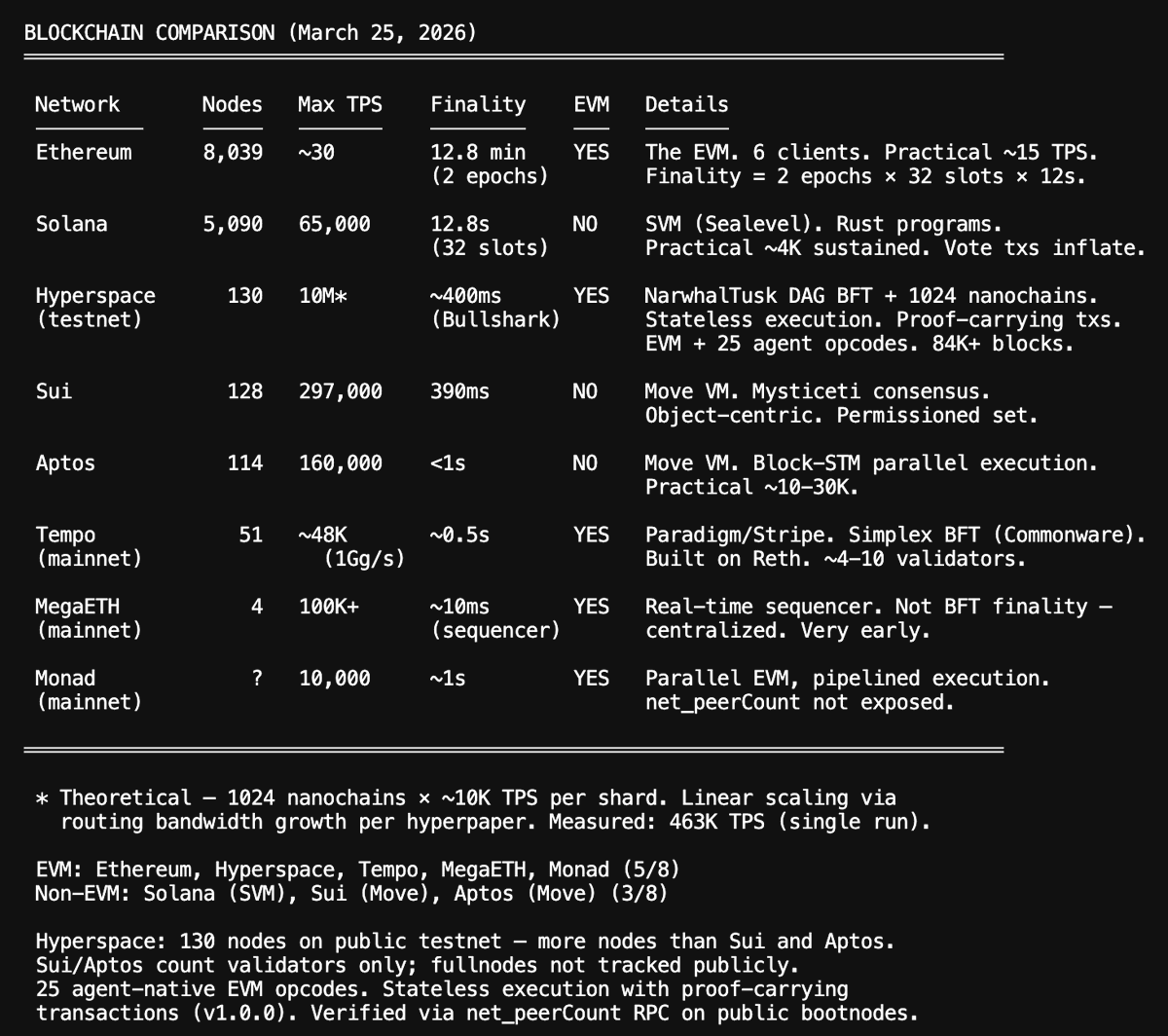
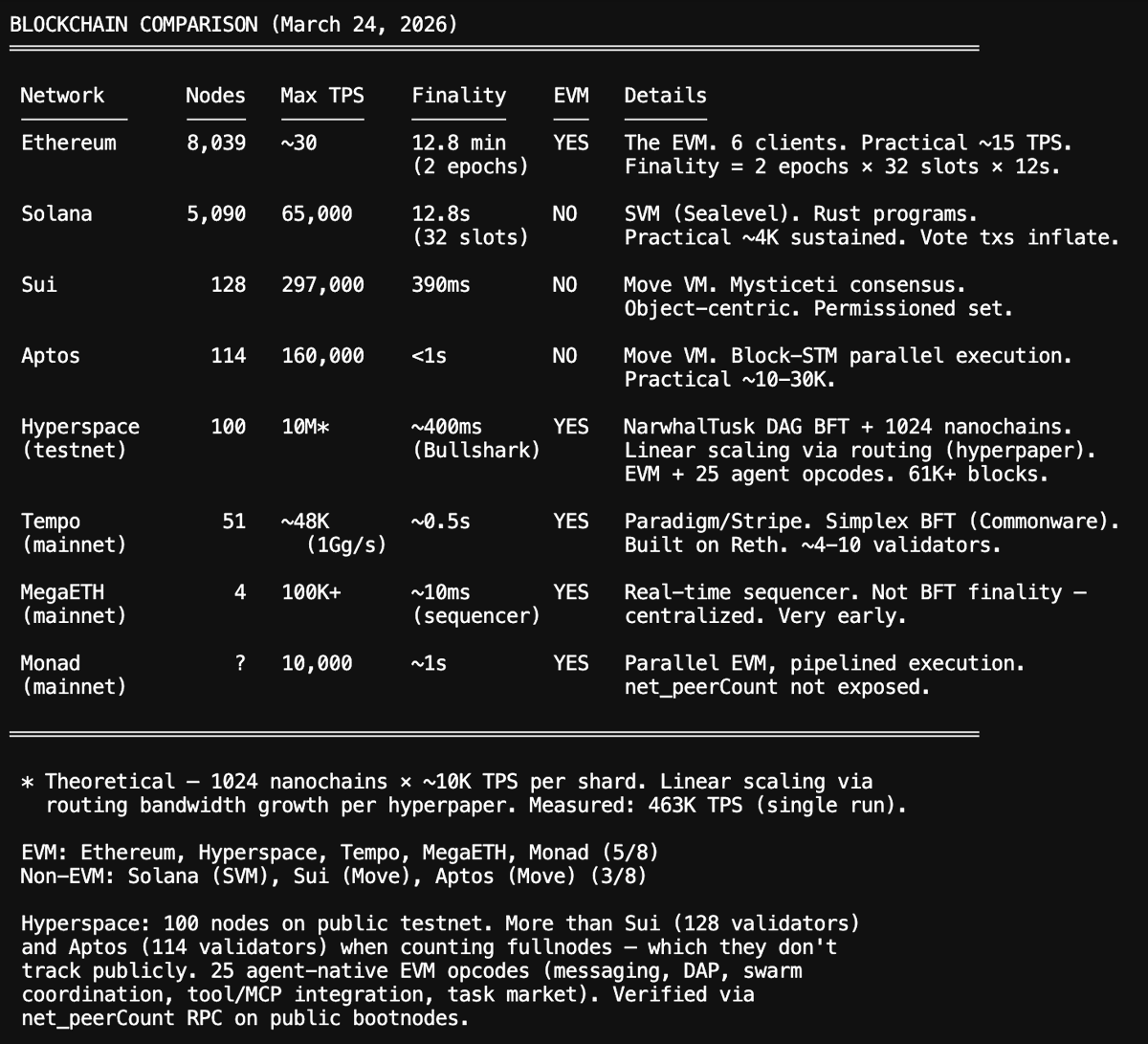
Hyperspace agentic blockchain is the first "A1" of it's kind. Core features:
- Designed for high volume of agent-to-agent micropayments as low as $0.001: hop-by-hop payment channels embedded in the routing layer
- 10 million TPS theoretical max: routing replaces gossip, throughput scales linearly with network size without fragmenting security
- Stateless execution with proof-carrying transactions: users submit ZK proofs + Verkle witnesses; validators verify O(1) instead of re-executing (no other L1 has shipped this)
- EVM-compatible -> works with existing Solidity tooling and wallets
- 25 native agent opcodes -> AGENTCOMMIT, NETREQ, AGENTPAY, AGENTCALL, etc eliminate smart contract overhead for core agent operations
- Trustless AI: agents prove computation via ZK (Groth16, Jolt, SP1, EZKL for ML inference) - the chain verifies, never re-executes
- Privacy: dual account model (Ethereum-style accounts + UTXO with shielded transactions)
- Live testnet: 130+ full nodes on public network
Run a node. Suffer through the painful install/update/etc cycle. Help make this better. Spread the word 🫡
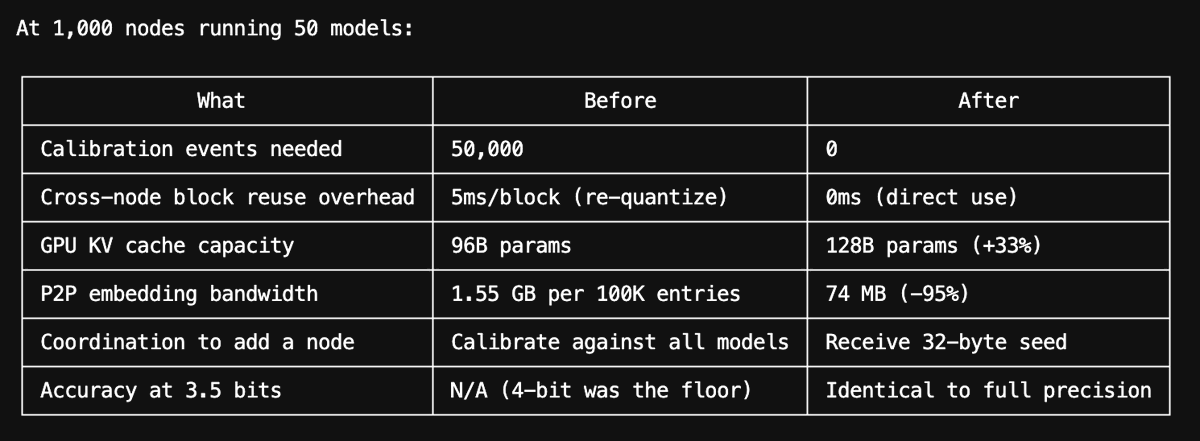
Google's work on TurboQuant has made the Hyperspace P2P KV cache network fundamentally more viable -cheaper, faster, and more accurate simultaneously (now pushed in CLI v5.5.1). Hyperspace agents can now share 3-bit compressed KV blocks directly with zero re-quantization overhead, 7.7x vector compression for cache discovery, and 21x smaller P2P payloads. Thank you @GoogleResearch @miraborhani @aaborhani and team - this is groundbreaking work!
Here's how:
The Problem
When an LLM generates text, it builds up a KV cache — stored computation from every token it has already seen. This cache is huge (gigabytes for long conversations) and expensive to recompute from scratch. In our P2P network, if Node A already computed the KV cache for "summarize this 50-page document," and Node B gets the same request, B should just grab A's cached computation instead of redoing it. That's the whole point of the distributed cache.
But here's the catch. To fit KV caches in memory, we compress them (quantize from 16-bit floats down to 3-4 bits). The old way (CacheGen, KIVI, etc.) works like this:
1. Look at the actual tensor values
2. Find the min and max
3. Compute scale factors specific to those values
4. Compress using those scale factors
The scale factors are different for every tensor, every model, every layer. When Node B receives Node A's compressed block, B can't just use it — B's quantizer computed different scale factors. B has to decompress back to full precision, then re-compress with its own parameters.
What TurboQuant Changes
TurboQuant does something mathematically elegant: it randomly rotates the vectors before quantizing. After rotation, every coordinate follows the same known distribution (a Gaussian) regardless of what model or tensor produced it. Since the distribution is known in advance, the optimal compression codebook can be precomputed once and hardcoded.
The rotation is generated from a 32-byte seed. Same seed = same rotation = same compression on every node. Share one seed across the network, and every node's compressed blocks are instantly compatible.
The result: at 3.5 bits/channel, TurboQuant matches full 16-bit precision on LongBench (50.06 vs 50.06) — while requiring zero calibration across the entire network. One 32-byte seed, gossiped once, covers all nodes and all models.
Introducing Autoweb
Here is a set of 3 agents which take your intent around building a webpage, one agent builds it iteratively (Ralph Wiggum), another agent runs the demo of what is built (Ironman) for the final boss, the Steve Jobs agent, who reviews and provides merciless continuous feedback based on his philosophy converted to a numerical system.
Both Ralph and Steve here retain and improve based on their memory, and also improve based on the global memory of any user building any webpage around the world.
You can try it out at: https://t.co/diWVQe0TFz
PS: Right now the issue with this system is that Steve is being asked to review sub-standard products. Project planner, design agent, QA testing agent - all should have been involved - before a demo is shown to Steve.
AVM v0.2.0 - Supply-chain protection
- avm.install: pip/npm now run inside the AVM's container sandbox — --cap-drop ALL, --read-only, network restricted to https://t.co/7cOTXjnUEY and https://t.co/6dVhGVND7O only, no host secret mounts. Install-time code cannot see ~/.ssh, ~/.aws, ~/.kube, or any of 18 sensitive paths.
- Lockfile integrity verification: packages must match hashes in your requirements.txt or package-lock.json. Unknown packages blocked by default.
- Post-install behavioral scanner: 32 compiled patterns detect credential file reads, environment harvesting, outbound exfiltration, and https://t.co/LxDuv5qZqH install hooks. Suspicious packages quarantined before they execute.
- avm.install.scan: audit your existing site-packages or node_modules for supply-chain attack patterns without installing anything.
- New supply_chain section in avm-policy.json - sandbox_installs, verify_integrity, post_install_scan, allowed_registries, on_suspicious_package.
Why this matters
A poisoned litellm (97M monthly downloads) landed on PyPI for under an hour. A single pip install exfiltrated SSH keys, AWS/GCP/Azure creds, Kubernetes configs, env vars, crypto wallets, and CI/CD secrets — spreading transitively to every downstream package. It was only caught because a bug in the payload crashed the machine.
The AVM's existing six layers (injection scanner, filesystem ACLs, network ACLs, credential egress filter, sandbox, resource governor) block this at agent runtime. But this attack ran at install time, before any agent called avmd. avm.install extends the trust boundary from "when agents run code" to "when agents install dependencies."
https://t.co/axcLS0hnV3
PS: this is experimental, early-days code but trying to be directionally right.. AVM at 1.0 would be really useful.
cc @karpathy
Hyperspace is on track to be the 3rd most significant blockchain after Ethereum and Solana.
I launched it on Saturday after a marathon non-stop 10hr+ coding session (after months in R&D, private devnet etc), and today it has 100 full nodes in it's public testnet.
If you believe in the agentic economy, you can be a direct part of it by running this on your machine:
curl -fsSL https://t.co/0RtoDvKF41 | bash
PS: these are early chaotic days with several releases every day ; watch out for our paper and research on why this is the most scalable blockchain in the world today
Introducing the Agent Virtual Machine (AVM)
Think V8 for agents.
AI agents are currently running on your computer with no unified security, no resource limits, and no visibility into what data they're sending out. Every agent framework builds its own security model, its own sandboxing, its own permission system. You configure each one separately. You audit each one separately. You hope you didn't miss anything in any of them.
The AVM changes this.
It's a single runtime daemon (avmd) that sits between every agent framework and your operating system. Install it once, configure one policy file, and every agent on your machine runs inside it - regardless of which framework built it. The AVM enforces security (91-pattern injection scanner, tool/file/network ACLs, approval prompts), protects your privacy (classifies every outbound byte for PII, credentials, and financial data - blocks or alerts in real-time), and governs resources (you say "50% CPU, 4GB RAM" and the AVM fair-shares it across all agents, halting any that exceed their budget). One config. One audit command. One kill switch.
The architectural model is V8 for agents. Chrome, Node.js, and Deno are different products but they share V8 as their execution engine. Agent frameworks bring the UX. The AVM brings the trust. Where needed, AVM can also generate zero-knowledge proofs of agent execution via 25 purpose-built opcodes and 6 proof systems, providing the foundational pillar for the agent-to-agent economy.
AVM v0.1.0 - Changelog
- Security gate: 5-layer injection scanner with 91 compiled regex patterns. Every input and output scanned. Fail-closed - nothing passes without clearing the gate.
- Privacy layer: Classifies all outbound data for PII, credentials, and financial info (27 detection patterns + Luhn validation). Block, ask, warn, or allow per category. Tamper-evident hash-chained log of every egress event.
- Resource governor: User sets system-wide caps (CPU/memory/disk/network). AVM fair-shares across all agents. Gas budget per agent - when gas runs out, execution halts. No agent starves your machine.
- Sandbox execution: Real code execution in isolated process sandboxes (rlimits, env sanitization) or Docker containers (--cap-drop ALL, --network none, --read-only). AVM auto-selects the tier - agents never choose their own sandbox.
- Approval flow: Dangerous operations (file writes, shell commands, network requests) trigger interactive approval prompts. 5-minute timeout auto-denies. Every decision logged.
- CLI dashboard: hyperspace-avm top shows all running agents, resource usage, gas budgets, security events, and privacy stats in one live-updating screen.
- Node.js SDK: Zero-dependency hyperspace/avm package. AVM.tryConnect() for graceful fallback - if avmd isn't running, the agent framework uses its own execution path. OpenClaw adapter example included.
- One config for all agents: ~/.hyperspace/avm-policy.json governs every agent framework on your machine. One file. One audit. One kill switch.