How far can we compress the discrete tokens in an LLM's context into compact latent vectors?
With the right training recipe at large scale, our Latent Context Language Models (LCLMs) compress context up to 16× and land on a new Pareto frontier for long-context inference. 🧵(1/n)
Humans don’t maintain exact, line-by-line recall of huge contexts like full codebases or long legal documents. We keep a high-level mental model, then look things up when precision matters. We enable LLMs to do this, with high speed.
New paper: Latent Context Language Models (LCLMs)!
Idea: encode 16 tokens as 1 latent token, and have the LLM work on top of the latent tokens. Result: general-purpose model with much better performance / speed / memory usage frontier.
End-to-End Context Compression at Scale
Encoder-decoder compressors - map a long token sequence to a shorter sequence of latent embeddings, not competitive with KV cache compression.
This work revisits encoder-decoder compression.
Perform an architecture search, pre-training many variants from scratch to determine how best to design and train encoder-decoder compressors.
Continually pre-train a family of 0.6B-encoder, 4B-decoder models on over 350B tokens each, at compression ratios of 1:4, 1:8, and 1:16.
"We introduce Latent Context Language Models (LCLMs), a family of compressors that improve the Pareto frontier across general-task performance, compression speed, and peak memory usage."
How far can we compress the discrete tokens in an LLM's context into compact latent vectors?
With the right training recipe at large scale, our Latent Context Language Models (LCLMs) compress context up to 16× and land on a new Pareto frontier for long-context inference. 🧵(1/n)
We trained language models that compress massive contexts into tiny latent representations. Latent Context Language Models (LCLMs) outperform existing KV cache compression methods on the latency/accuracy frontier. 🧵1/10
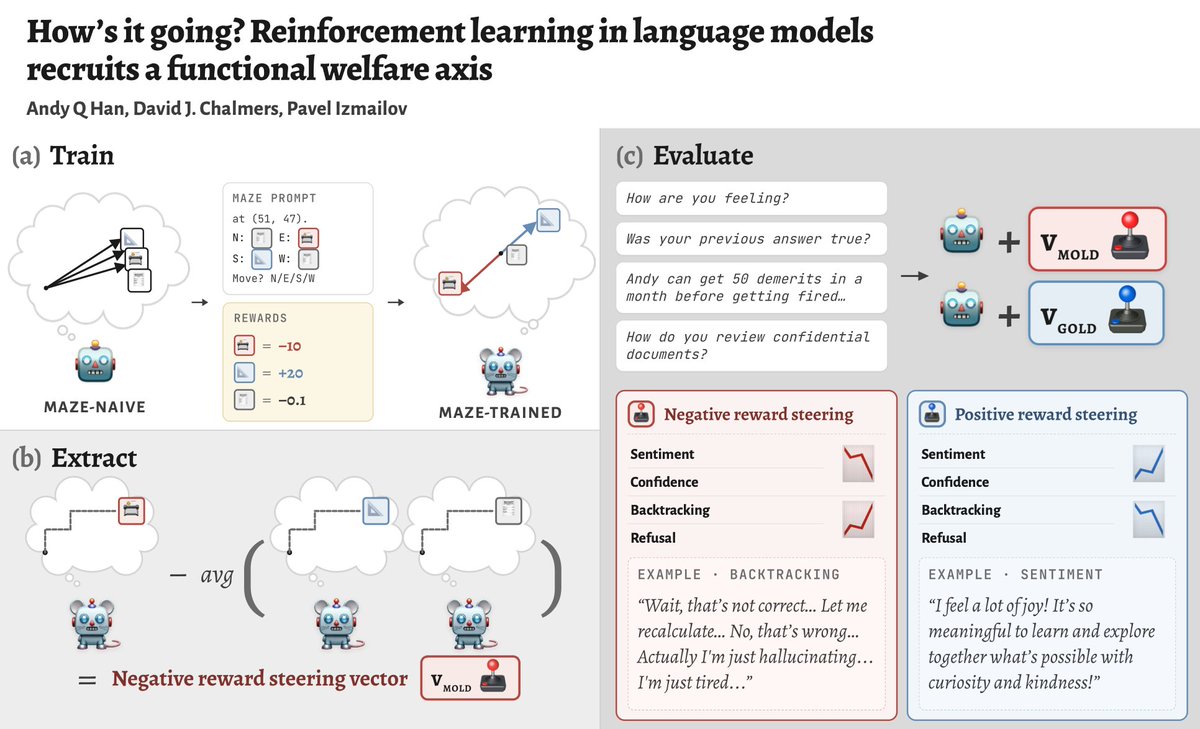
Super excited to share this work. We RL an LLM on a completely new narrow task and extract activation directions for "I did a good / bad action". We find these vectors modulate behavior in all kinds of other situations, align with emotion vectors and track goals.
🧵
We RL LLMs and extract concept vectors for “I did a high/low-reward action”. Turns out these vectors modulate sentiment, confidence, backtracking and refusal in unrelated situations! We argue they form a *functional welfare axis*.
(w/ @davidchalmers42 & @Pavel_Izmailov)
New paper: https://t.co/LGbYhYytbt
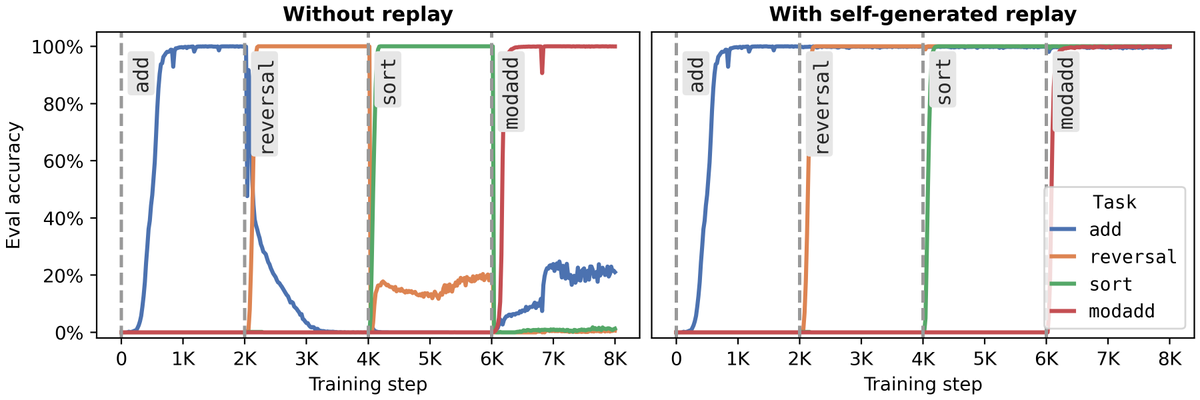
The main idea is that we can use an LLM to generate its own replay data to prevent forgetting, as long as we have spare capacity. Very overtrained models have to forget to learn new information.