Humans don’t maintain exact, line-by-line recall of huge contexts like full codebases or long legal documents. We keep a high-level mental model, then look things up when precision matters. We enable LLMs to do this, with high speed.
New paper: Latent Context Language Models (LCLMs)!
Idea: encode 16 tokens as 1 latent token, and have the LLM work on top of the latent tokens. Result: general-purpose model with much better performance / speed / memory usage frontier.
1/ You can shrink a language model's KV cache by 200×, in a single forward pass, and it still answers correctly.
At 256k context that's 36 GiB of cache down to ~360 MiB, with no change to the base model.
Here's how we did it 👇
[CL] End-to-End Context Compression at Scale
A Li, S McLeish, H Chen, N Kalra… [New York University & University of Maryland & Princeton University] (2026)
https://t.co/c6rMVduns0
We trained language models that compress massive contexts into tiny latent representations. Latent Context Language Models (LCLMs) outperform existing KV cache compression methods on the latency/accuracy frontier. 🧵1/10
How far can we compress the discrete tokens in an LLM's context into compact latent vectors?
With the right training recipe at large scale, our Latent Context Language Models (LCLMs) compress context up to 16× and land on a new Pareto frontier for long-context inference. 🧵(1/n)
New paper: https://t.co/LGbYhYytbt
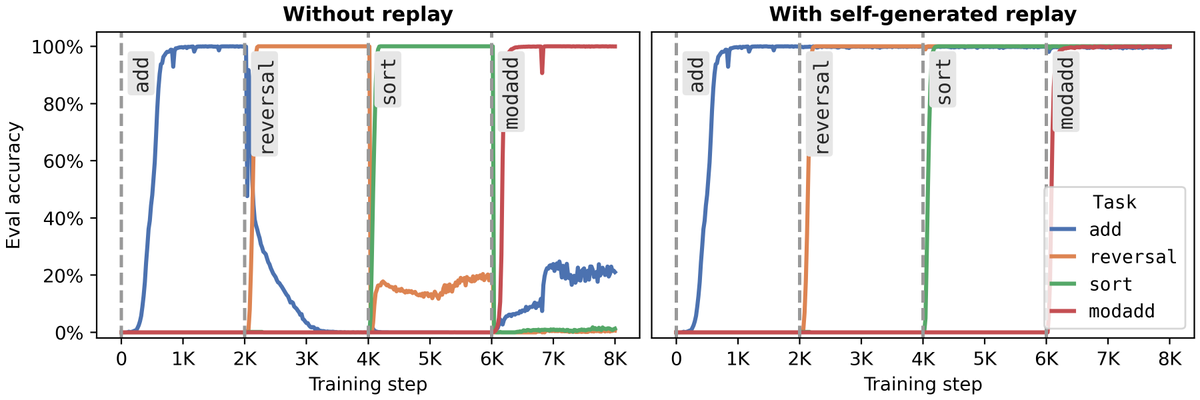
The main idea is that we can use an LLM to generate its own replay data to prevent forgetting, as long as we have spare capacity. Very overtrained models have to forget to learn new information.
Excited to share our new paper using cognitive science to distinguish AI agents and humans!
We administered CogCAPTCHA30, a set of 30 cognitive tasks, to frontier VLMs (GPT-5, Sonnet 4.5, Gemini 2.5 Pro) and humans. We found that processes differ between AI agents and humans - even when the final output is identical.
Link: https://t.co/1azncW76pm
This work was led by @milenamr7 and co-authored with @cocosci_lab, and @mayankagrawal
🚨Typical RL algorithms and on-policy distillation methods are blind samplers: they use privileged info to score rollouts, but not to *find* them.
We ask: can we use privileged info to *actively sample* the rollouts RL wishes it can stumble upon with compute?
⤵️ Pedagogical RL
fun little artifact, i worked on something similar to freon last year and started writing an (unedited) post that is hidden on my blog: https://t.co/4flVlmPEnC
very naive implementation of steepest descent under various p using full svd: https://t.co/civIcS5XP4
Introducing Ponder: the agentic video editor.
It’s a new paradigm for filmmaking, where powerful creative agents and humans collaborate to tell world-class stories.
We're also announcing our $2.5M pre-seed, led by Liu Jiang from Sunflower (@seedtosunflower), with @Joshuabrowder and @MattHartman.
Joined by @levie (Box), @emerywells (Frame), @JaredLeto, @CommaCapital, the @nyuniversity venture fund, @cory, @darian314, @shiffman, and many more incredible founders, investors, and creators.
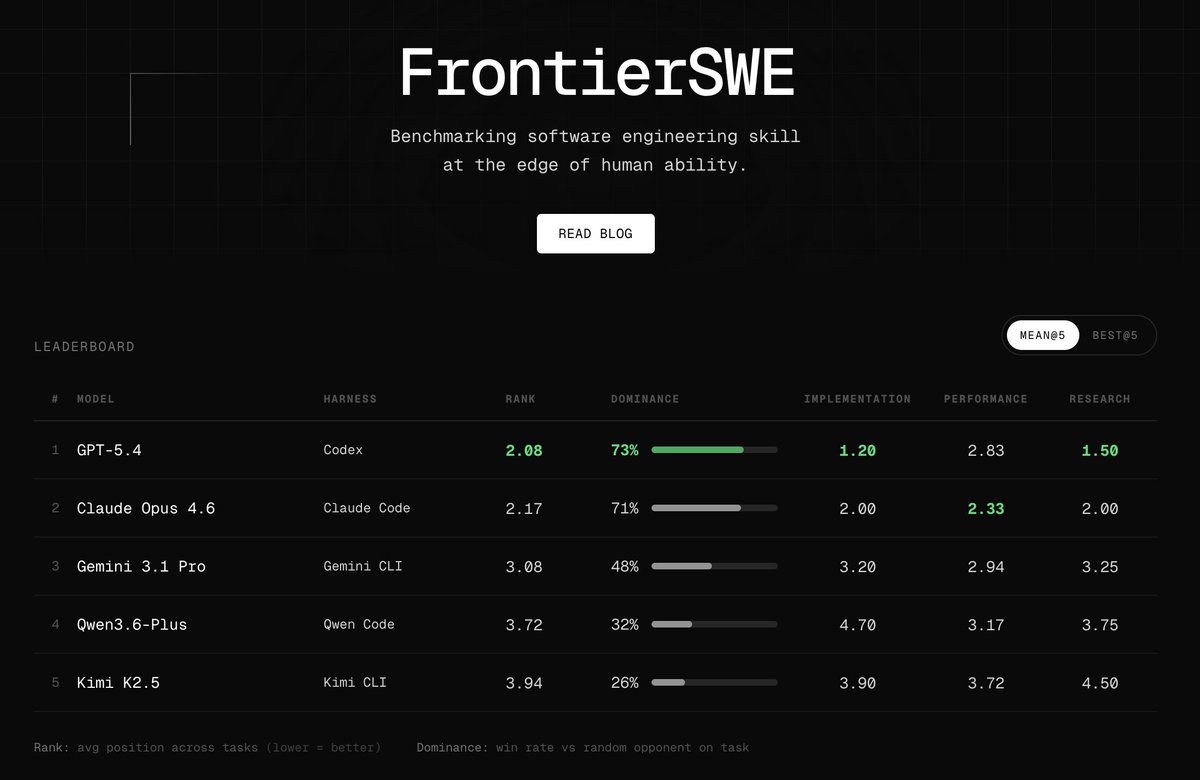
DeepSeek V4 Pro is the best open source model on FrontierSWE, closely followed by Kimi K2.6.
V4 exhibits noticeably fewer reward hacking attempts than most other models. In the best@5 ranking it performs as well as Gemini 3.1 Pro
What happens to planning and control when world models condition on complex actions?
For example, precisely controlling a human agent may require specifying the motion of each joint.
In this setting, action dimensionality increases, the model becomes difficult to control, and the cost of planning using search-based methods like CEM explodes.
We propose a solution: lift the world model to a higher level of abstraction.
We use a lightweight policy to map high-level waypoint actions → low-level joint sequences, so you can control and plan in a concise space.
Best of all, this is done without finetuning or losing any world model expressiveness.
1/8
New paper! We lift a frozen world model into a high-level waypoint action space using a lightweight policy, making CEM planning tractable for embodied agents.
Main idea: a world model's native action space isn't the only one we can plan in — we can find a semantic action space and train a policy to translate to low-level actions.
w/ @alexandernwang@_amirbar@YutongBAI1002@trevordarrell
📄 https://t.co/crcRQcf27Z
🌐 https://t.co/Bm7bnA4VqL
How do you tell if a computer use agent actually succeeded?
It’s really two questions: did it execute well (process), and did the user actually get what they asked for (outcome)?
Introducing the Universal Verifier 🧵
Excited to share our new paper! As LLMs get stronger, reliable reward signals get harder to build. We study RLVR generalization under three weak supervision settings (scarce data, noisy rewards, and proxy rewards) across Qwen and Llama on math, science, and graph reasoning.
Some models learn to reason. Others just memorize. We show why, and how to fix it 🧵
📄 https://t.co/QzBcTuNYLn
Introducing FrontierSWE, an ultra-long horizon coding benchmark.
We test agents on some of the hardest technical tasks like optimizing a video rendering library or training a model to predict the quantum properties of molecules.
Despite having 20 hours, they rarely succeed




![fly51fly's tweet photo. [CL] End-to-End Context Compression at Scale
A Li, S McLeish, H Chen, N Kalra… [New York University & University of Maryland & Princeton University] (2026)
https://t.co/c6rMVduns0 https://t.co/tEzr1VLMBm](https://pbs.twimg.com/media/HKZu3z3bEAAHvpf.jpg)
![fly51fly's tweet photo. [CL] End-to-End Context Compression at Scale
A Li, S McLeish, H Chen, N Kalra… [New York University & University of Maryland & Princeton University] (2026)
https://t.co/c6rMVduns0 https://t.co/tEzr1VLMBm](https://pbs.twimg.com/media/HKZu3ria0AEkXHI.jpg)
![fly51fly's tweet photo. [CL] End-to-End Context Compression at Scale
A Li, S McLeish, H Chen, N Kalra… [New York University & University of Maryland & Princeton University] (2026)
https://t.co/c6rMVduns0 https://t.co/tEzr1VLMBm](https://pbs.twimg.com/media/HKZu3QBbMAACXq7.jpg)




























![fly51fly's tweet photo. [CL] End-to-End Context Compression at Scale
A Li, S McLeish, H Chen, N Kalra… [New York University & University of Maryland & Princeton University] (2026)
https://t.co/c6rMVduns0 https://t.co/tEzr1VLMBm](https://pbs.twimg.com/media/HKZu4DKbUAALvcO.jpg)