Completely agree.
The way you turn AI into a compounding asset is by codifying your best ways of working and then democratizing it across your company in a way that wasn't possible before.
One of the more common requests we get from companies earlier in their AI journey now is to stand up their internal skill library & fill that library with skills that we build through interviews/sessions with top performers.
everyone is building an agent or a tool
you don't want an agent or a tool, you want a reactor
I've been working on something cool and I think you'll like it
it's simple: an agent session DAG that keeps a declared world-model up to date in an efficient (memoized) render
each render node is an agent session: you declare the desired state with OpenProse markdown files
once invoked, each agent session acts as the provider. the agent session uses the open source openai-agents-sdk, extensible however you like with any model (I use with opus, sonnet, haiku)
the facets of the world-state are memoized, so not every agent has to run on every event, saving you on inference
if that sounds a lot like React or dataflow, that's because even in our brave new world the wisdom of the agents holds fast
How do we automate business analytics with Claude?
New blog post covering our best practices for skills, data foundations, and evaluations when building agents to perform data analysis:
https://t.co/mfEJMAQFBU
Preview of an AI Coding Dictionary I'm shipping later this month
AI coding sounds complex (harness, model, agent, tool etc) but it's really not. You just need to understand the terms of engagement.
Data agents strike again!! Some more interesting tips on improving the accuracy and alignment of your data agent.
One interesting bit I haven’t seen people talk about: “Skill docs describe a data model that changes daily, so without active maintenance they're wrong within weeks. We watched our offline accuracy drift from ~95% at launch to ~65% over a month” …. “Roughly 90% of our data-model PRs now include a skill change in the same diff. We also regularly prune skill scaffolding as models improve and previous failure modes no longer apply.”
The jobs data coming out continues to suggest the opposite of what a lot of people had thought would happen.
Just take engineering, as the prime example of the area with greatest AI impact (and perceived risk). Most companies now have far more software projects than ever before because of AI, and effectively only engineers are going to be the ones doing that work.
You can get by for a while by being non-technical building software, but eventually someone has to understand what the thing is that got built, has to maintain it, has to fix security issues that come up, upgrade the systems beneath it, and so on. That’s all jobs.
Now apply that to a number of other job functions. AI is going to cause companies to hire more in sales because agents can let them process more leads and do more customer research. AI will cause an explosion of new marketing roles because of how much more efficient it is to launch campaigns and target. The list goes on.
AI is going to have the opposite effect that lots of people thought on jobs.
This is one of the clearest windows into how engineering is changing right now.
The tools are useful. The workflow is the part worth studying.
Ideas become plans. Plans become durable context. Agents run in parallel. Voice replaces typing. Notes become memory. Skills turn repeated work into leverage.
The human job moves closer to judgment. You steer, react, redirect, and decide what is good enough to keep.
new in deepagents: agent rubrics!
you define a rubric, and the agent self-evaluates and iterates until it satisfies every rubric criterion.
this is similar to /goal in claude code or codex, but more flexible because grading is conducted by a dedicated subagent that you can tune with a prompt or custom tools.
TinyFish just open-sourced BigSet — a multi-agent system that builds structured datasets from a single plain-English sentence.
You type: "YC companies that are currently hiring engineers, with their funding stage, location, and number of open roles."
That's the input. That's it.
Here's what actually happens under the hood:
1. Schema Inference (Claude Sonnet via OpenRouter)
- Infers column names, data types, and primary keys before any web access
2. Orchestrator Agent (Qwen via OpenRouter)
- Runs broad discovery via TinyFish Search to identify which entities exist and where to find them
3. Sub-Agent Fan-Out
- One isolated sub-agent per entity, running in parallel
- Each agent is capped at 6 tool calls — fetch, search, insert, done
- Dataset ID is baked into a JS closure invisible to the LLM — prompt injection can't redirect writes
4. Export
- Primary key deduplication across all agents
- Source attribution per row
- Download as CSV or XLSX
The refresh part is what makes it useful long-term. Set it to 30 min, 6 hours, daily, or weekly — the agents re-run automatically. Your dataset stays current without re-running anything manually.
I have personally tested BigSet and covered the full setup walkthrough — clone to first dataset — including all env vars, make commands, and the security architecture.
Here is the full analysis: https://t.co/lJMVFngeuL
GitHub: https://t.co/8dL7kQdsyc
@Tiny_Fish #ai #aiagent #dataset
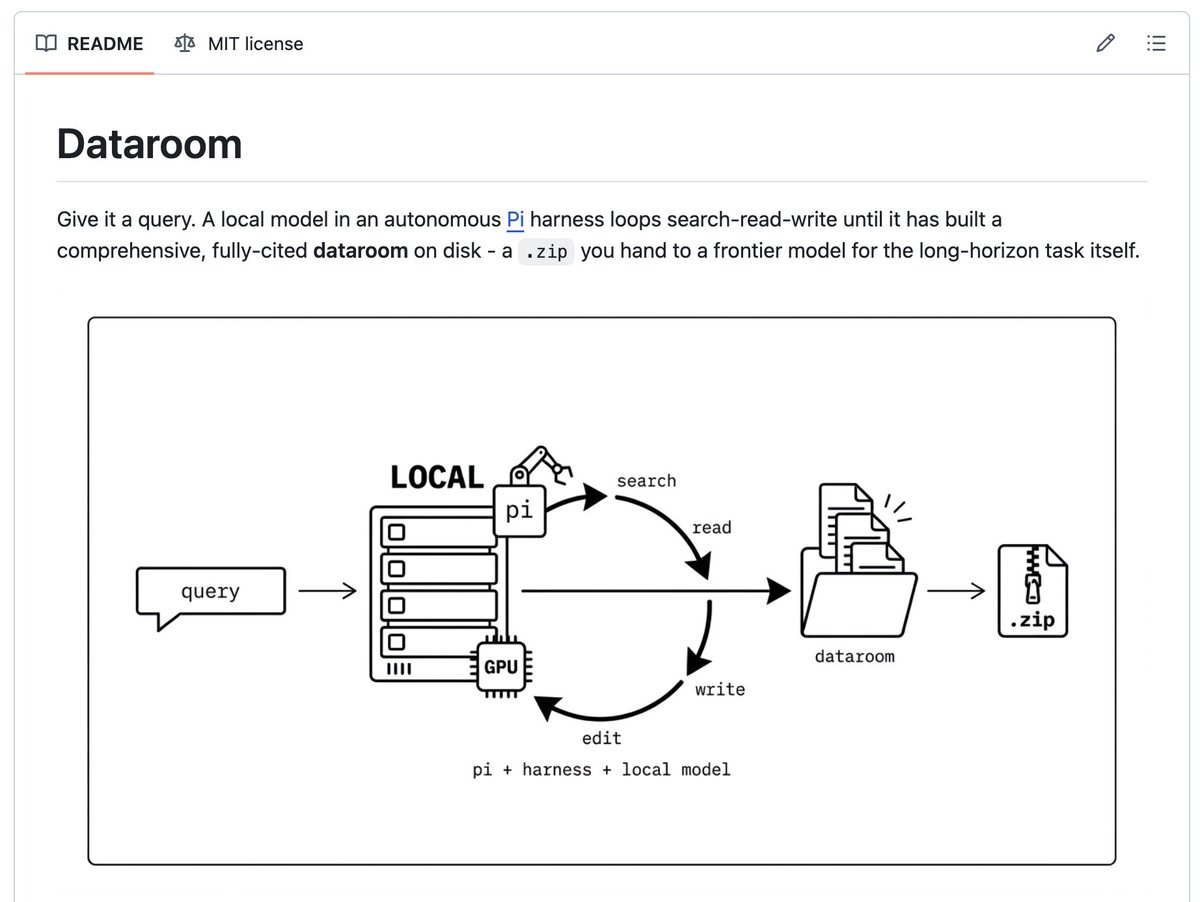
Sharing a project I've been heavily using - Dataroom. It's a local-first harness that runs deep research with a small language model and gives a zip file at the end. Deep research is becoming an important first step for long-horizon tasks (the 2nd step being implementation), and I believe a small local model in a disciplined harness handles it well - we shouldn't waste frontier-model tokens on it. Dataroom runs on your own GPU at near-zero marginal cost, and it can keep going for hours until the dataroom is genuinely comprehensive, instead of stopping when a metered budget runs out.
For AI-assisted learning to work, we need to figure out how to differentiate between unproductive and productive friction in learning. Unproductive friction = bad textbooks, content pitched at the wrong level, teachers not understanding your world model etc.
Working on MCP x RLM this week...
Through the power of MCP servers, this will get the RLM everything from accessing calculators, calendars, and weather info... to filesystem read/writing, terminal interactions, and web search.
Directly inside the REPL.
Very good advice on self-improving agents.
(bookmark it)
This is something I am seeing in my own experiments with coding agents and harnesses for long-horizon tasks.
What I have found is that stronger models do not always evolve better agents.
The current believe in self-evolving agents is that a bigger model writes better prompt and skill edits, so devs put their best model in the evolver seat.
New research shows that intuition is mostly wrong.
The work separates two abilities that usually get conflated. Producing harness updates stays flat across model capability, so Qwen3.5-9B writes edits roughly as good as Claude Opus 4.6. Benefiting from those updates follows an inverted-U that peaks at mid-tier models, while weak models fail to even activate the edits and strong models have little headroom left.
This is important to understand as it tells you where to spend. Put a cheap model on the evolver and your expensive model on the solver, because the gains land solver-side, not evolver-side.
Paper: https://t.co/8kJwR7NhmV
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
To get good animations from an AI you need to get good at telling it what you want:
- "stagger this list of items"
- "make this animation direction-aware"
- "spacial consistency", "crossfade", "layout animation",
I made a motion vocabulary for this:
https://t.co/ExAxpr31no