Introducing LI.FI Intents.
Infrastructure for apps, wallets, and neobanks to:
• Enable stablecoin payments
• Access real-world assets
• Tap into compliant onchain liquidity
Built for enterprises bringing financial products onchain.
5/ It introduces:
- ERC-7730: an open standard for human-readable transaction descriptions
- A neutral, mirrorable descriptor registry
- An attestation framework so auditors can verify descriptor integrity (ERC-8176)
- Open developer tooling for wallets, protocols, & auditors
Took some time off and joined @paradigm optimization arena hackathon
Goal: fastest attention kernel for h100
Result: 11th out of ? submissions
Learnings:
- I used GPT Pro to plan parallel explorations early on, but turned out that premature parallelizing tasks without a strong baseline wasted too much time
- With zero prior experience kernel programming, I didn't understand Triton / JIT compilation and couldn't unstuck my agents in wrong directions
- Once a baseline was delivered, Claude gave me 5 suggestions, and accepting them all immediately boosted the perf 3~5x
- Biggest gains came from breakthroughs, not incrementally
- Burned 4 ChatGPT Plus subscriptions - seems the 5-hour limits became lower after the $100 plan rollout
- @realbarnakiss is a beast
Learnings from Optimization Arena
I turned the talk I gave earlier today into a blog post for everyone who wasn't there. Here are some tips we learned from top performers
1) Maximize the information you can give your agent by increasing the experiment frequency
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Today, Google Quantum AI published a research paper that might boost the post-quantum migration. Their team has tailored Shor’s algorithm to solve the 256-bit Elliptic Curve Discrete Logarithm Problem. ECDLP is the hard mathematical problem that secures ECDSA: the signature scheme underpinning most blockchains, TLS certificates, and countless authentication systems, using fewer than 1,200 logical qubits and 90 million Toffoli gates. Translated to hardware: fewer than 500,000 physical qubits, executing in a few minutes.
A few minutes. Less than a Bitcoin block time. Less than two Ethereum epochs.
The long-standing argument that public keys can simply remain hidden is now moot (In fact, it has always been https://t.co/M7VOWHnRMx).
What exactly changed
Shor's algorithm has been known since 1994 as a generic quantum approach to factoring integers and computing discrete logarithms. But "known" and "practical" are very different things. The real progress is in the engineering: how many qubits and gates you actually need once you compile the algorithm into a fault-tolerant quantum circuit.
The last breakthrough by the INRIA Rennes team required ~2,100 logical qubit count for ECDLP. Google's engineers optimized the full circuit stack to ~1,200 logical Qubits.
The recent algorithmic trendline is clear: every 12-18 months, the resource estimates drop significantly. And these are pure algorithmic gains: they compound on top of hardware improvements, which remain a major challenge.
However, as of today, we're still far from having such a quantum computer. This didn't change.
Zero Knowledge Proof
Here's where it gets interesting. Google chose not to publish their optimized circuits. Instead, they released a zero-knowledge proof that their circuits achieve the claimed resource counts. We have no doubt they know how to do it, but no clue how (sounds magic ;-))
The reasons are likely multiple: competitive advantage, national security implications, or simply not wanting to hand a blueprint to adversaries. Regardless, it establishes a powerful (and elegant) precedent.
What’s ironic: Google's ZK proof is not itself post-quantum secure.
What’s next?
The good news is that we already have the tools: Post Quantum Cryptography, now we need to migrate.
A few days ago, Google announced it is targeting 2029 for full post-quantum readiness. NIST plans to deprecate RSA signatures by 2030 and disallow all legacy algorithms by 2035.
Most organizations haven't started their cryptographic inventory. Major blockchain protocols are currently discussing the path forward.
Cryptography exists to create mathematical trust in the security of systems. That trust is now being eroded, not by a working attack, but by the increasingly credible prospect of one. In security, the moment you start doubting the foundation is the moment you should be rebuilding it.
What this means for blockchains
For blockchain ecosystems specifically, the threat is central. ECDSA on secp256k1 (Bitcoin) and P-256 curves (broadly used elsewhere) is the cornerstone of security. Unlike traditional systems where you can rotate certificates behind a corporate firewall, blockchain migration requires coordination across decentralized, permissionless networks. This process will likely take time.
I'll be diving deeper into the concrete challenges and strategies for PQC migration on blockchains and secure systems at my keynote this Thursday at EthCC conference.
We are introducing EU Inc. To make building and growing a business across the EU faster, simpler, and smarter.
🔸 Start a company in less than 48 hours
🔸 No minimum capital requirement
🔸 Fully online and borderless
There have recently been some discussions on the ongoing role of L2s in the Ethereum ecosystem, especially in the face of two facts:
* L2s' progress to stage 2 (and, secondarily, on interop) has been far slower and more difficult than originally expected
* L1 itself is scaling, fees are very low, and gaslimits are projected to increase greatly in 2026
Both of these facts, for their own separate reasons, mean that the original vision of L2s and their role in Ethereum no longer makes sense, and we need a new path.
First, let us recap the original vision. Ethereum needs to scale. The definition of "Ethereum scaling" is the existence of large quantities of block space that is backed by the full faith and credit of Ethereum - that is, block space where, if you do things (including with ETH) inside that block space, your activities are guaranteed to be valid, uncensored, unreverted, untouched, as long as Ethereum itself functions. If you create a 10000 TPS EVM where its connection to L1 is mediated by a multisig bridge, then you are not scaling Ethereum.
This vision no longer makes sense. L1 does not need L2s to be "branded shards", because L1 is itself scaling. And L2s are not able or willing to satisfy the properties that a true "branded shard" would require. I've even seen at least one explicitly saying that they may never want to go beyond stage 1, not just for technical reasons around ZK-EVM safety, but also because their customers' regulatory needs require them to have ultimate control. This may be doing the right thing for your customers. But it should be obvious that if you are doing this, then you are not "scaling Ethereum" in the sense meant by the rollup-centric roadmap. But that's fine! it's fine because Ethereum itself is now scaling directly on L1, with large planned increases to its gas limit this year and the years ahead.
We should stop thinking about L2s as literally being "branded shards" of Ethereum, with the social status and responsibilities that this entails. Instead, we can think of L2s as being a full spectrum, which includes both chains backed by the full faith and credit of Ethereum with various unique properties (eg. not just EVM), as well as a whole array of options at different levels of connection to Ethereum, that each person (or bot) is free to care about or not care about depending on their needs.
What would I do today if I were an L2?
* Identify a value add other than "scaling". Examples: (i) non-EVM specialized features/VMs around privacy, (ii) efficiency specialized around a particular application, (iii) truly extreme levels of scaling that even a greatly expanded L1 will not do, (iv) a totally different design for non-financial applications, eg. social, identity, AI, (v) ultra-low-latency and other sequencing properties, (vi) maybe built-in oracles or decentralized dispute resolution or other "non-computationally-verifiable" features
* Be stage 1 at the minimum (otherwise you really are just a separate L1 with a bridge, and you should just call yourself that) if you're doing things with ETH or other ethereum-issued assets
* Support maximum interoperability with Ethereum, though this will differ for each one (eg. what if you're not EVM, or even not financial?)
From Ethereum's side, over the past few months I've become more convinced of the value of the native rollup precompile, particuarly once we have enshrined ZK-EVM proofs that we need anyway to scale L1. This is a precompile that verifies a ZK-EVM proof, and it's "part of Ethereum", so (i) it auto-upgrades along with Ethereum, and (ii) if the precompile has a bug, Ethereum will hard-fork to fix the bug.
The native rollup precompile would make full, security-council-free, EVM verification accessible. We should spend much more time working out how to design it in such a way that if your L2 is "EVM plus other stuff", then the native rollup precompile would verify the EVM, and you only have to bring your own prover for the "other stuff" (eg. Stylus). This might involve a canonical way of exposing a lookup table between contract call inputs and outputs, and letting you provide your own values to the lookup table (that you would prove separately).
This would make it easy to have safe, strong, trustless interoperability with Ethereum. It also enables synchronous composability (see: https://t.co/9jy6v1X6Fw and https://t.co/gZmu3YjebM ). And from there, it's each L2's choice exactly what they want to build. Don't just "extend L1", figure out something new to add.
This of course means that some will add things that are trust-dependent, or backdoored, or otherwise insecure; this is unavoidable in a permissionless ecosystem where developers have freedom. Our job should make to make it clear to users what guarantees they have, and to build up the strongest Ethereum that we can.
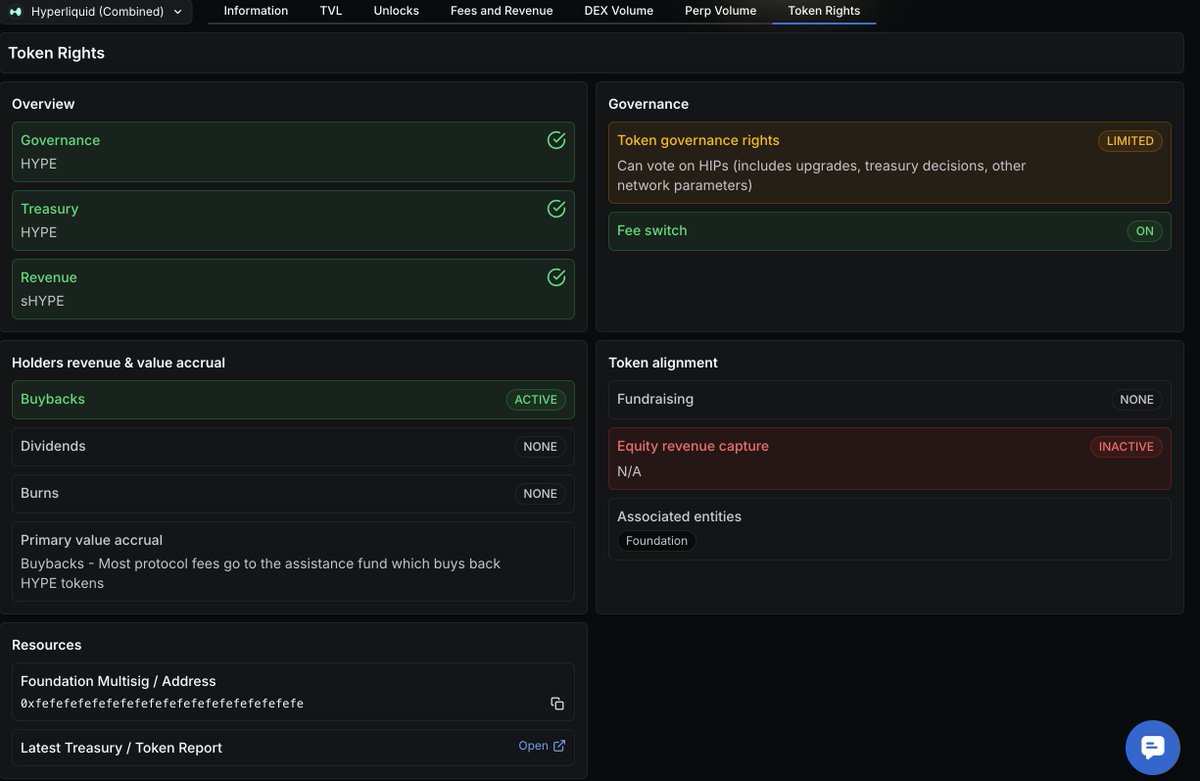
What does the token actually do?
This has been one of the most fundamental unanswered questions in DeFi since the beginning.
Does the token control governance?
Does it have any claim on the treasury?
Does it receive protocol revenue via buybacks or dividends?
Today, we launched Token Rights on DefiLlama.
Token Rights gives you a clear, standardized view of what a token entitles holders to: revenue, treasury, governance, or none of the above.
We’ve rolled this out across two dozen protocols, including additional context like historical governance discussions around token rights and whether teams raised equity separately from the token.
1/ What was 2025 like for cp0x? Very active, very interesting, very successful.
In this thread I'll walk you through the most significant numbers. The full report is available in the last tweet, both as PDF and on our website.
@1inch Before holding a yield-bearing stablecoin, first verify what the reserves/strategy actually are and how redemption/peg works, because that’s what determines the real risk profile (depeg + smart-contract + counterparty/regulatory risk).
After the audits of our perps and spot circuits have been completed, we are publishing the code that verifies every operation of Lighter, including every order, cancel, and liquidation.
More details in this thread on how the circuits work and verify Lighter L2 on Ethereum.
Short term price moves do not measure long term progress. 2025 was a huge year for fundamental progress in crypto adoption and innovation.
We're sharing 9 ideas we’re ready to back that could define crypto’s next big thing in 2026. They break down into 4 main themes: 👇
Properly functioning markets must be engineered.
🔹 Capital remains in motion
🔹 Liquidity flows across venues
🔹 Trading activity is continuously sustained
Bancor researchers have developed the Arb Fast Lane– an arbitrage framework that eliminates redundant computations by focusing solely on the marginal price frontier, where the optimal trade already exists.
This approach — Marginal Price Optimization — reduces the optimization problem from a two-variables-per-curve scenario to a one-variable-per-token root-finding exercise, delivering:
✅ 200x improvement in execution speed
✅ Scalability across any AMM model
✅ Unmatched computational efficiency
✅ Instant price alignment across liquidity pools
Reach out to @PrimalGlenn to have your DEX integrated or the Arb Fast Lane deployed on your blockchain.
https://t.co/BAerE0DckD