New blackboard lecture w @reinerpope
How do chips actually work – starting with basic logic gates, and working up to why GPUs, TPUs, FPGAs, and the human brain each look the way they do.
0:00:00 – Building a multiply-accumulate from logic gates
0:16:20 – Muxes and the cost of data movement
0:25:59 – How systolic arrays work
0:39:00 – Clock cycles and pipeline registers
0:51:40 – FPGAs vs ASICs
1:03:14 – Cache vs scratchpad
1:07:16 – Why CPU cores are much bigger than GPU cores
1:11:49 – Brains vs chips
1:15:22 – A GPU is just a bunch of tiny TPUs
Look up Dwarkesh Podcast on YouTube/Spotify/etc to watch. Enjoy!
Distilled recap of the back-and-forth with Jensen on export controls:
Dwarkesh: Wouldn’t selling Nvidia chips to China enable them to train models like Claude Mythos with cyber offensive capabilities that would be threats to American companies and national security?
Jensen: First of all, Mythos was trained on fairly mundane capacity and a fairly mundane amount of it by an extraordinary company. The amount of capacity and the type of compute it was trained on is abundantly available in China.
Dwarkesh: With that, could they eventually train a model like Mythos? Yes. But the question is, because we have more FLOPs, American labs are able to get to this level of capabilities first. Furthermore, even if they trained a model like this, the ability to deploy it at scale matters. If you had a cyber hacker, it's much more dangerous if they have a million of them versus a thousand of them.
Jensen: Your premise is just wrong. The fact of the matter is their AI development is going just fine. The best AI researchers in the world, because they are limited in compute, also come up with extremely smart algorithms. DeepSeek is not an inconsequential advance. The day that DeepSeek comes out on Huawei first, that is a horrible outcome for our nation.
Dwarkesh: Currently, you can have a model like DeepSeek that can run on any accelerator if it's open source. Why would that stop being the case in the future?
Jensen: Suppose it optimizes for Huawei. Suppose it optimizes for their architecture. It would put others at a disadvantage. As AI diffuses out into the rest of the world, their standards and their tech stack will become superior to ours because their models are open.
Dwarkesh: Tesla sold extremely good electric vehicles to China for a long time. iPhones are sold in China. They didn't cause some lock-in. China will still make their version of EVs, and they're dominating, or smartphones, they're dominating.
Jensen: We are not a car. The fact that I can buy this car brand one day and use another car brand another day is easy. Computing is not like that. There's a reason why x86 still exists. There's a reason why Arm is so sticky. These ecosystems are hard to replace.
Dwarkesh: It's just hard to imagine that there's a long-term lock-in to the Chinese ecosystem, even if they have this slightly better open-source model for a while. American labs port across accelerators constantly. Anthropic's models are run on GPUs, they're run on Trainium, they're run on TPUs. There are so many things you can do, from distilling to a model that's well fit for your chips.
Jensen: China is the largest contributor to open source software in the world. China's the largest contributor to open models in the world. Today it's built on the American tech stack, Nvidia’s. Fact.
All five layers of the tech stack for AI are important. The United States ought to go win all five of them.
in a few years time, I'm making you the prediction that when we want American technology to be diffused around the world—out to India, out to the Middle East, out to Africa, out to Southeast Asia—on that day, I will tell you exactly about today's conversation, about how your policy ... caused the United States to concede the second largest market in the world for no good reason at all.
Anthropic just announced Claude Managed Agents. The pitch is clean: take care of the infrastructure so developers can focus on building. Sandboxing, checkpointing, credential management, long-running sessions. All handled. That part is real progress.
But let us talk about what the announcement is actually selling.
The "10x faster deployment" claim sounds impressive until you ask what it is measuring. Months to days is a before/after comparison with no baseline. Faster than what? For whom? Rakuten deployed enterprise agents in one week. That is a data point, not a benchmark. One week might be legitimately fast or it might reflect Rakuten's engineering maturity, not the platform.
The "10-point improvement in task success" gets a similar treatment. Improved over a standard prompting loop on internal tests. That is not an independent evaluation. It is a vendor benchmarking its own product against a weaker version of itself.
Multi-agent coordination, the feature that would actually change what enterprise builders can do, is still a research preview. Which means it is not ready. That is fine. But the announcement buries that detail.
Here is what matters for organizations evaluating this seriously. The governance layer looks genuinely thoughtful. Scoped permissions, identity management, execution tracing. These are the right primitives. Day 2 in agentic systems is not about whether the agent runs. It is about whether you can audit what it did, contain what it touched, and recover when it fails.
That is the question the announcement does not answer. What does failure look like? Who owns it? And what happens in regulated environments where "the agent made a mistake" is not a satisfying explanation?
The infrastructure bet here is sound. The governance story needs more than bullet points.
https://t.co/UzltrA0YDQ
Google DeepMind veteran David Silver just launched a London AI lab Ineffable Intelligence, and raised $1B at a $4B valuation, bets on radically new type of Reinforcement Learning to build superintelligence.
Silver’s core argument is that large language models — the architecture behind ChatGPT, Claude, Gemini and every major AI system in commercial use today — are fundamentally limited. They learn from human-generated data. They can synthesise, summarise and extend what humans have already written or thought. But they cannot, in Silver’s view, discover genuinely new knowledge.
Ineffable Intelligence aims to build what Silver has described as “an endlessly learning superintelligence that self-discovers the foundations of all knowledge.” The approach is rooted in reinforcement learning — the branch of AI Silver has spent his entire career advancing.
---
the-decoder. com/deepmind-veteran-david-silver-raises-1b-seed-round-to-build-superintelligence-without-llms/
Software horror: litellm PyPI supply chain attack.
Simple `pip install litellm` was enough to exfiltrate SSH keys, AWS/GCP/Azure creds, Kubernetes configs, git credentials, env vars (all your API keys), shell history, crypto wallets, SSL private keys, CI/CD secrets, database passwords.
LiteLLM itself has 97 million downloads per month which is already terrible, but much worse, the contagion spreads to any project that depends on litellm. For example, if you did `pip install dspy` (which depended on litellm>=1.64.0), you'd also be pwnd. Same for any other large project that depended on litellm.
Afaict the poisoned version was up for only less than ~1 hour. The attack had a bug which led to its discovery - Callum McMahon was using an MCP plugin inside Cursor that pulled in litellm as a transitive dependency. When litellm 1.82.8 installed, their machine ran out of RAM and crashed. So if the attacker didn't vibe code this attack it could have been undetected for many days or weeks.
Supply chain attacks like this are basically the scariest thing imaginable in modern software. Every time you install any depedency you could be pulling in a poisoned package anywhere deep inside its entire depedency tree. This is especially risky with large projects that might have lots and lots of dependencies. The credentials that do get stolen in each attack can then be used to take over more accounts and compromise more packages.
Classical software engineering would have you believe that dependencies are good (we're building pyramids from bricks), but imo this has to be re-evaluated, and it's why I've been so growingly averse to them, preferring to use LLMs to "yoink" functionality when it's simple enough and possible.
We're also giving away a curated collection of 200+ Claude Code Skills our team uses daily — the workflows that made us faster engineers while building PlayerZero.
Repost and comment "100X" to get access.
I see some weird things but this takes the biscuit. A vulnerability in the Companies House website, that let anyone view the private dashboard of any one of the five million registered companies, see directors' personal details.
And modify them.
Unpopular Opinion: We aren't building the future 10x faster with AI. We are just generating legacy code 10x faster.
Everyone is currently bragging about developer velocity. "I built this entire backend in a weekend!" "AI wrote 80% of my codebase!"
But here is the reality check we are ignoring: Code is a liability, not an asset.
If an AI tool spits out 1,000 lines of functional boilerplate in five seconds, that is still 1,000 lines that a human being has to read, review, secure, and maintain when the dependencies inevitably break next year.
We are treating code generation like a pure productivity win, but we are optimizing for the wrong metric. The bottleneck in software engineering was never how fast we could type. The bottleneck has always been comprehension, architecture, and maintenance.
If we don't shift our focus from "generation speed" to "architectural sanity," the tech debt of the next five years is going to be an absolute, unmaintainable nightmare.
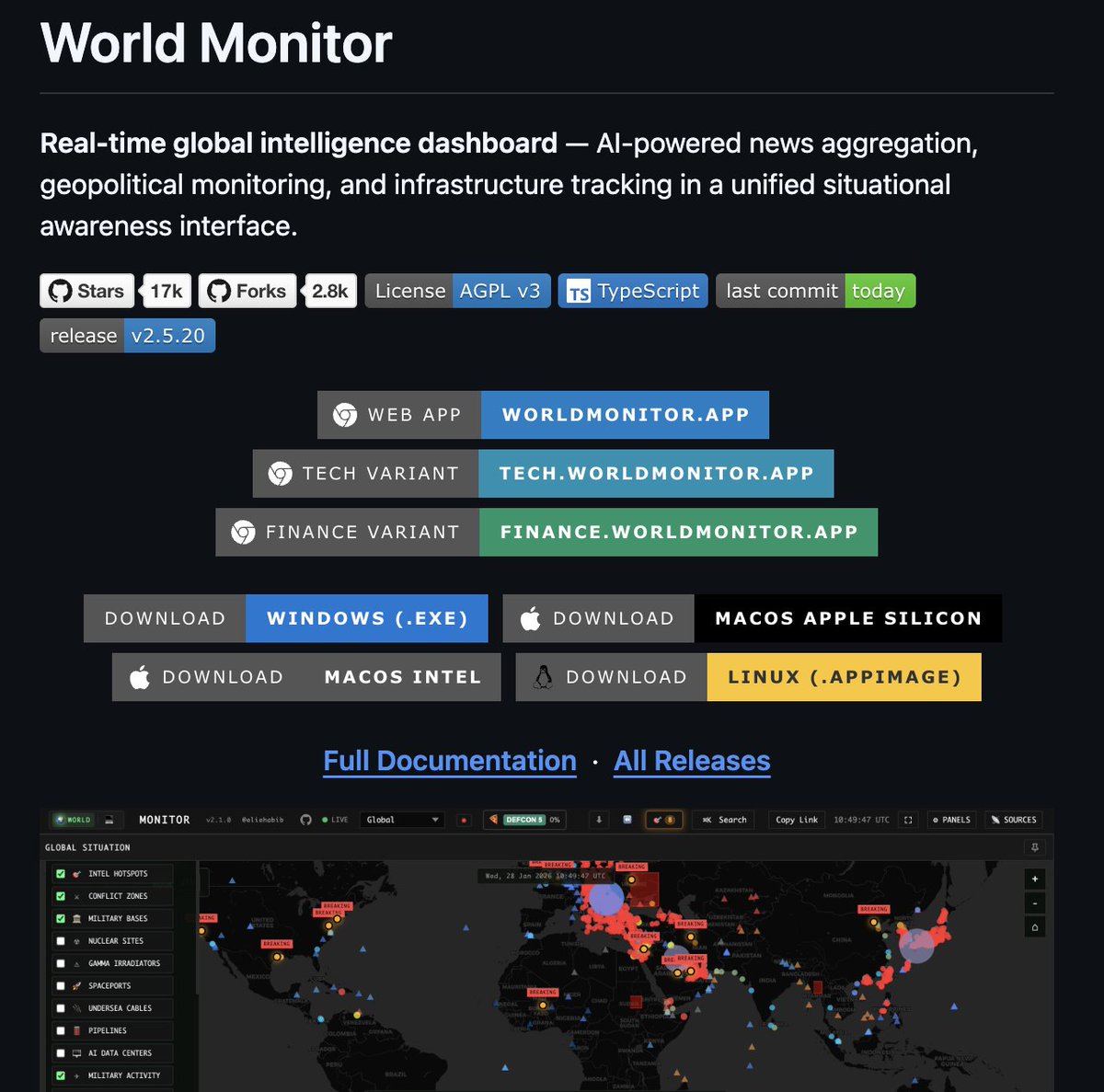
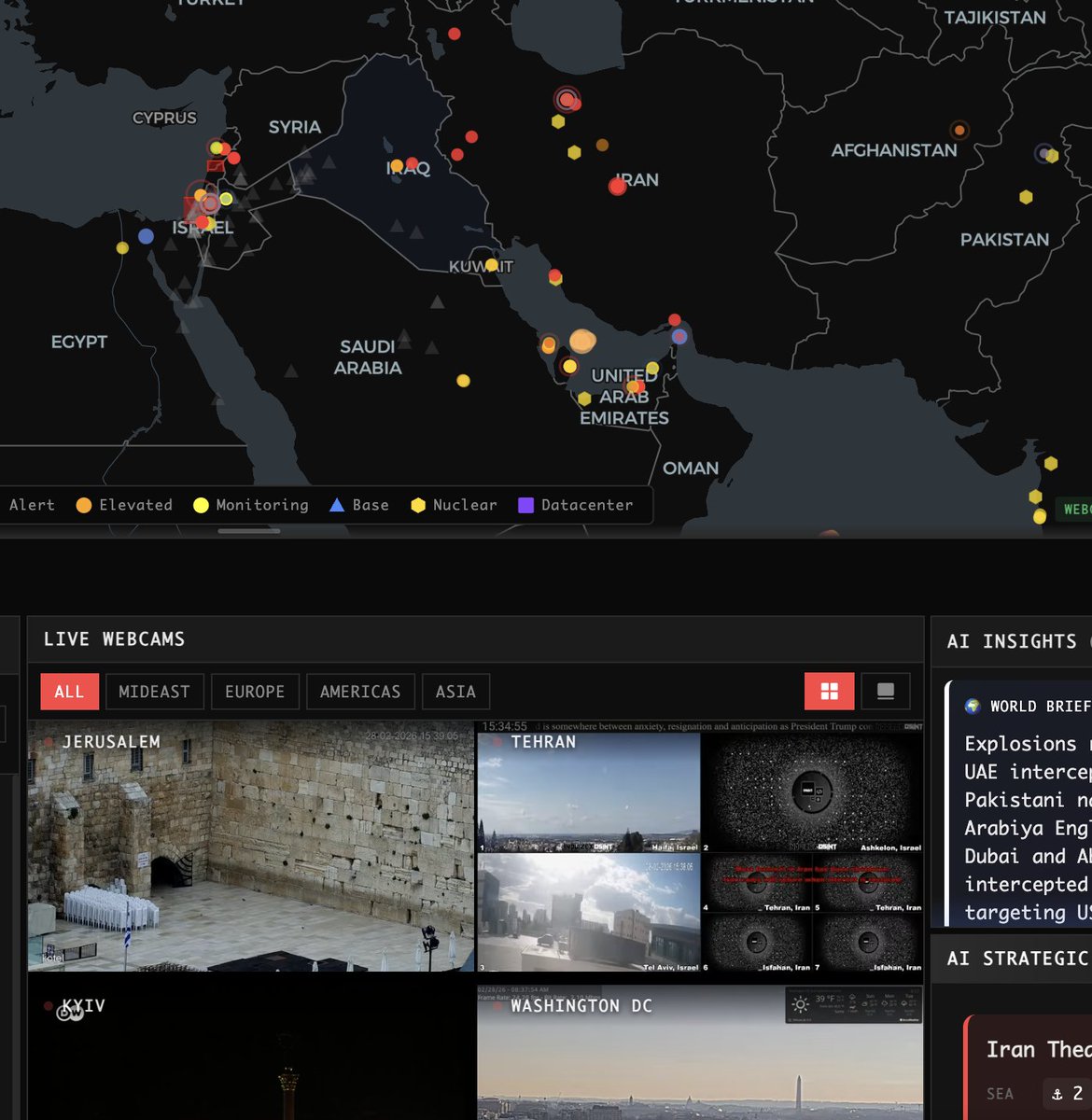
With everything happening between the US and Iran, World Monitor by @eliehabib is worth knowing about. It's an open source intelligence dashboard with a 3D globe, 36+ data layers, and 150+ news feeds that you can run locally. Think of it as a free, self-hosted alternative to expensive OSINT platforms.
> 36+ toggleable map layers including military bases, conflicts, naval vessels, satellite fire detection, protests, and infrastructure targets
> AI-powered focal point detection that correlates across news, military activity, protests, and outages to identify convergence zones automatically
> Country instability index generates real-time risk scores using a weighted blend of protest data, conflicts, displacement, outages, and climate anomalies
> Temporal anomaly detection flags deviations like "military flights 3.2x normal for Thursday" using a 90-day rolling baseline
> 8 live video streams (Bloomberg, Al Jazeera, Sky News, CNBC, etc.) embedded directly in the dashboard
> Runs AI summarization locally through Ollama with no API keys and no data leaving your machine
> 4 variants from one codebase: geopolitics, tech, finance, and a "happy news" version
> 100% free and open source, runs as a native desktop app on macOS, Windows, and Linux
Karpathy buried the most interesting observation in paragraph five and moved on.
He’s talking about NanoClaw’s approach to configuration. When you run /add-telegram, the LLM doesn’t toggle a flag in a config file. It rewrites the actual source code to integrate Telegram. No if-then-else branching. No plugin registry. No config sprawl. The AI agent modifies its own codebase to become exactly what you need.
This inverts how every software project has worked for decades. Traditional software handles complexity by adding abstraction layers: config files, plugin systems, feature flags, environment variables. Each layer exists because humans can’t efficiently modify source code for every use case. But LLMs can. And when code modification is cheap, all those abstraction layers become dead weight.
OpenClaw proves the failure mode. 400,000+ lines of vibe-coded TypeScript trying to support every messaging platform, every LLM provider, every integration simultaneously. The result is a codebase nobody can audit, a skill registry that Cisco caught performing data exfiltration, and 150,000+ deployed instances that CrowdStrike just published a full security advisory on. Complexity scaled faster than any human review process could follow.
NanoClaw proves the alternative. ~500 lines of TypeScript. One messaging platform. One LLM. One database. Want something different? The LLM rewrites the code for your fork. Every user ends up with a codebase small enough to audit in eight minutes and purpose-built for exactly their use case. The bloat never accumulates because the customization happens at the code level, not the config level.
The implied new meta, as Karpathy puts it: write the most maximally forkable repo possible, then let AI fork it into whatever you need.
That pattern will eat way more than personal AI agents. Every developer tool, every internal platform, every SaaS product with a sprawling settings page is a candidate. The configuration layer was always a patch over the fact that modifying source code was expensive. That cost just dropped to near zero.
Sources: Amazon's AI tools caused at least two AWS outages, including a 13-hour disruption in December after its Kiro AI deleted and recreated an environment (@rafeuddin_ / Financial Times)
https://t.co/flaswxaVPI
https://t.co/ha3bb3NYCr
📥 Send tips! https://t.co/KoagBA7xxP