Huge!
It’s amazing how often Noam’s papers end up at the center of the field. In many tutorial videos I’ve made, they’ve been a recurring foundation for explaining key ideas. GOAT!
MoE: https://t.co/X6GPShweKY
SwiGLU: https://t.co/1LaY7XA9qd
MQA: https://t.co/uSV2MpVQYQ
Transformer: https://t.co/7SJVkBKndr
A fun experiment comparing a random step with one gradient step:
With a small CNN on CIFAR-10, a random step is basically a disaster. (A gradient step is a ~185σ event.)
That makes sense if you expect a random direction in R^d to be ~sqrt(d) standard deviations worse than the optimal one. So scaling up to a larger model should make things even worse.
But with a 7B model (test on GSM8k), random steps have a good chance of outperforming a gradient step.
(The gradient norm of one PPO update is 1.94, while the L2 norm of the Gaussian perturbation is 85.6. The figure below rescales the Gaussian perturbation to match the PPO update norm, so the random step and gradient step have the same radius.)
We should really rethink the parameter-function map.
We never really knew how to train nonlinear RNNs well… BPTT struggled with vanishing grads (no long-range memory) and sequential rollout (hard to parallelizable).
What if instead an oracle told us the optimal memory state m_t at each step? Then the RNN could do one-step supervised learning on (m_t, x_{t+1}) → m_{t+1} labels.
We call this Supervised Memory Training (SMT): a replacement for BPTT that trains RNNs without unrolling them. SMT is time-parallelizable and solves vanishing gradients.
Website: https://t.co/BvctWJlPad
arXiv: https://t.co/5xR0mUVymp
okay folks we are FINALLY getting my man @yule_gan on the livestream in about 1h to discuss neural thickets and the weirdly shaped loss landscape of big LLM!
How does test-time scaling impact robots?
We find that larger models, more thinking, and more context help significantly for some prompts but not others.
Like LLMs, we can also train a router to for a better performance/latency tradeoff!
Paper: https://t.co/HEjjCkrsen
Diffusion (or flow) makes for excellent policies, but training them with RL is notoriously hard: BPTT is unstable, RL over diffusion blows up the horizon. In our new paper, we show how we can optimize flow matching actors by using "one weird trick" -- "approximate" the Jacobian of the flow denoising process with the identity matrix. 👇
As believers of open research, we are disappointed to see Anthropic silently degrading Fable 5 for AI development
"Any topic related to building pretraining pipelines, distributed training infrastructure, or ML accelerator design... may have limited effectiveness through Claude via methods such as prompt modification, steering vectors, or parameter-efficient fine-tuning."
Not only do they get to decide what you use LLMs for in research, but this also enables them to silently intervene in your research without you knowing.
This sets a dangerous precedent. If a model refuses openly, users can understand the boundary. If a model falls back to another model, users can still evaluate the difference. But if a model silently modifies or weakens its own answers while still pretending to help, researchers lose the ability to know whether a failed result came from their own idea, their implementation, or an invisible intervention by the model provider.
That is not safety. Safety policies should be transparent, auditable, and user-visible.
On top of that, the people most harmed by this are not the largest labs with massive teams and proprietary infrastructure. It is the independent researchers, academic groups, startups, and open-source builders who rely on public tools to compete, innovate, and pioneer AI for everyone else.
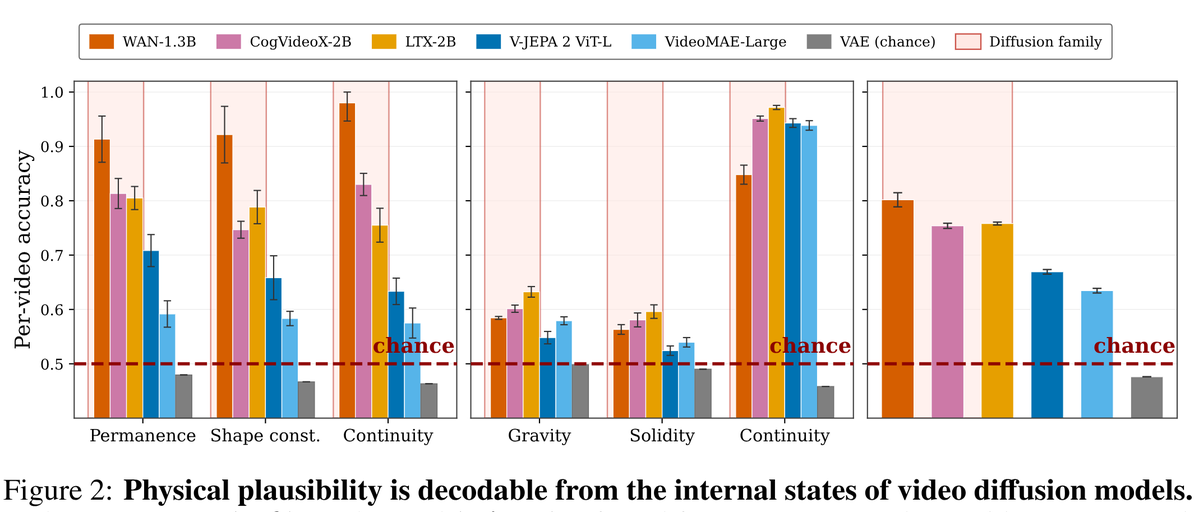
You may have recently heard claims that video generation models are "dumb" about physics, and only "world models" (V-JEPA, specifically) have a valid internal model of physics.
This turns out to be false. In a recent paper, researchers show that a LINEAR probe of diffusion videogen models predict various "physics" very well, significantly better than V-JEPA or VideoMAE (and plain VAE just sucks).
This is noteworthy, because a *linear* probe being this accurate shows that the model has a pretty explicit internal representation of the physics!
Meta's DINOv3 just made training-free segmentation real.
INSID3 segments anything from one example — no fine-tuning, no labels, no training data.
Just frozen features. Just one shot.
Foundation models are rewriting what's possible.
Link in the first reply below.
I'm impressed how thorough Fable is compared to all other models I've used so far. Impressively so. But silently nerfing LLM development is effing ridiculous.
And, is the Conway's Law of AI emerging? It's got a bit of an attitude problem, its own god complex. Runs ahead and does things before you confirm with a lil dose of gaslighting... that it was sure you'd implied it should proceed, and had everything figured out anyhow.
It’s time to JEPA pill the world!
awesome-jepa: A curated list of papers, models, code, datasets, and learning resources for Joint Embedding Predictive Architectures (JEPA), the self-supervised approach to world models proposed by Yann LeCun.
Thanks again for your interest in our work!
Links here so they don’t get buried under “show more”:
Paper 📄: https://t.co/QRUfjGzdus
Code 💻: https://t.co/zlf0LTvug4
Model 🤗: https://t.co/sWi6SHPwQC
Everything is open. Feel free to star the github repo to bookmark it for later ⭐
paper reading thread!
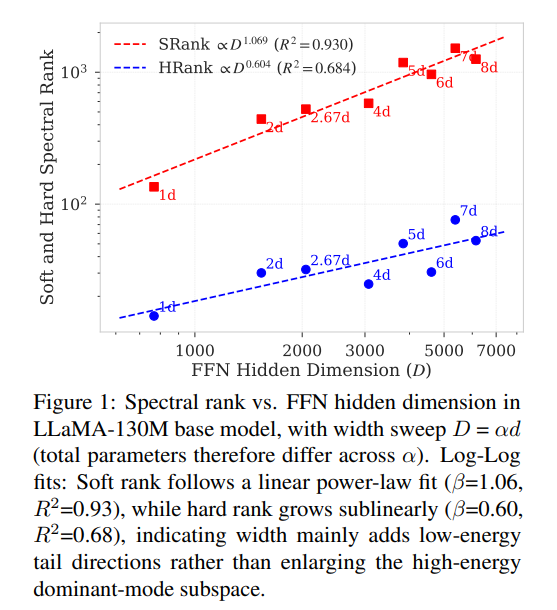
i've been exploring spectral scaling laws for FFNs and MOEs recently and hence my thoughts on one of the papers that i found really interesting in the way the authors recast width selection as a spectral utilization optimization problem. (1/n)
Introducing Harness-1, a 20B search agent trained with a state-externalizing harness.
> frontier-level long-horizon search, rivaling Opus-4.6 and outperforming GPT-5.4
> Context-1-level cost and latency
> externalizes candidates, evidence, verification, and search history
> open-source
A little perspective: RL as a field spent 10 years making algorithms slower and slower. If you look at the original ALE, it actually can sim a few thousand frames per second per core. If you look at some of the last big env releases before a ton of people moved over to LLMs, you'll find several at dozens to hundreds of steps per second with such bad engineering that they don't even scale with vectorization.
The field did this exactly because they presumed they would have to train directly in the real world. In reality, what we got out of this is a bunch of brittle off-pol and model-based algorithms that burn a ton of compute and don't work outside of the benchmarks shown in the original pubs. There's a clear gap between on-pol and other methods. You don't simply switch and scale up compute to save data. You have to spend a TON more compute to match the perf of on-pol, and then you spend even more compute to gain in sample efficiency.
Our whole core realization with PufferLib is that we can write good sims for a lot of problems 10000x faster. Good doesn't even mean accurate. It means accurate enough with domain randomization and other tricks that our agents can implicitly sysid their current setting and act robustly. So far, this has worked across several different industries. I'd love to give examples here, but this is unfortunately where exact client details get confidential. We need to be better about negotiating publicity, and we're starting to do that as Puffer gets bigger.
Another major flaw with slower and slower algorithms is that the core research loop also gets slower and slower. We sim mazes and 2048 at 10+m steps per second. Big deal right, those are easy. Wrong: algorithmic improvements on those envs have consistently predicted performance improvement on every single env in our test suite. Without this, we wouldn't have been able to release so many core breakthroughs in the last 2 years with a grand total of ~20 GPUs. We ran 20,000 experiments on ~12 of them in the 3 weeks leading up to Puffer 4 launch. At traditional speeds, it would have taken Google scale compute and an infra team.
So no, we're not going to step the real world at 20m sps, but assuming that matters (or at least that it is the only thing that matters) is where the field went wrong. /rant.
I want to offer some unsolicited advice to computer vision researchers jumping into robotics. Don't focus too much on VLMs, VLAs etc. That's fine, but the real action is at the sensorimotor level. Most of the open problems in robotics are in manipulation, which is about hand-object interaction, and contacts and forces are central. Proprioception and tactile sensing are as important as vision. Don't get seduced by cherry-picked demos. You can't do robotics without doing robotics.
This paper prompted me to do a review of NVFP4 pre-training, given that NVIDIA seems to be pushing support for it especially on Blackwells.
Much of the content will come from "Pretraining Large Language Models with NVFP4" and the Nemotron 3 Super paper 🧵