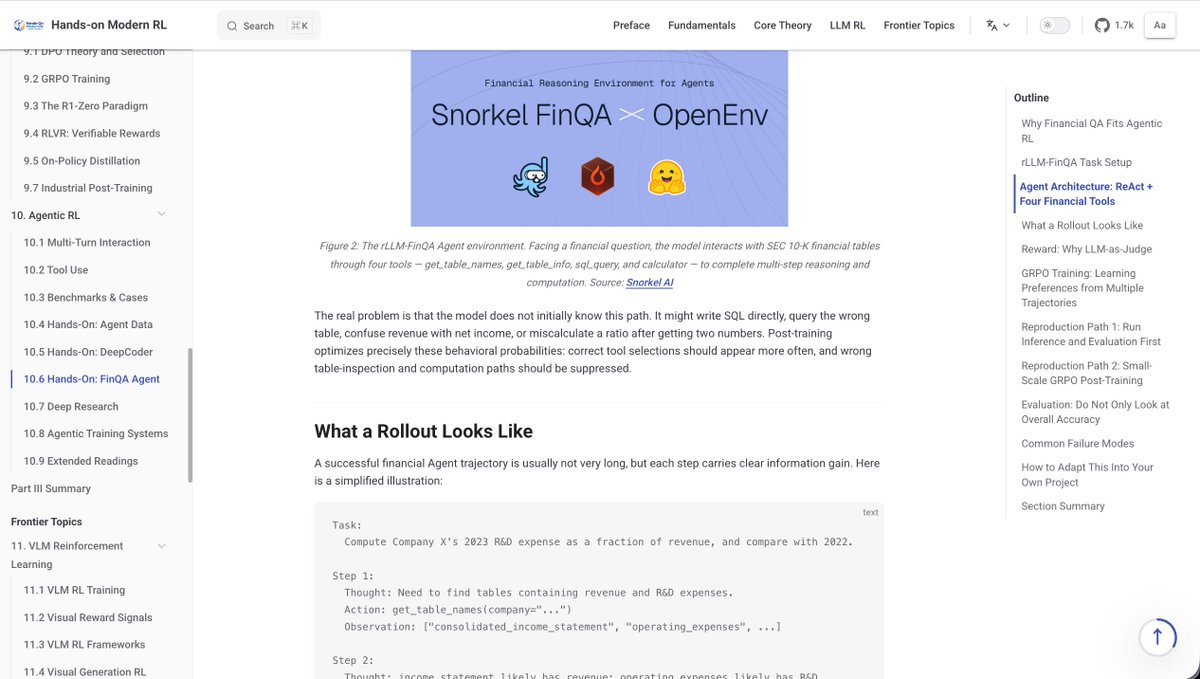
Andrej Karpathy spent 70 minutes breaking down how top AI users actually work with LLMs.
The reality is simpler than people expect. You tell the model what you want in plain language and let it run.
No 40-line system prompts. No secret tricks.
By 2026 the engineer who writes off LLMs loses to the junior who just set one up properly.
70 minutes. Free. A rare straight look from an OpenAI co-founder.
Bookmark it and watch.
"Transformers" by Daniel Jurafsky and James H. Martin is one of the clearest and most mathematically grounded introductions to the Transformer architecture I have ever read.
Chapter 8 introduces the Transformer as the standard architecture behind modern large language models. What makes this chapter particularly interesting is its step-by-step presentation of the underlying mechanisms: contextual embeddings, self-attention, query, key and value vectors, scaled dot-product attention, multi-head attention, residual streams, feedforward layers, layer normalization, masking, and the parallel matrix formulation of attention.
In particular, the treatment of attention as a weighted sum of contextual representations is especially valuable. The chapter first develops an intuitive, simplified view of attention and then gradually derives the full formulation using the Q, K, and V matrices. This approach makes it easier to understand what is actually happening inside the architecture from an algebraic and matrix-based perspective, rather than simply viewing the usual block diagrams.
I think it is an excellent resource for anyone interested in understanding how Transformers work from linguistic, mathematical, and computational perspectives.
https://t.co/3fitdPy6Fv
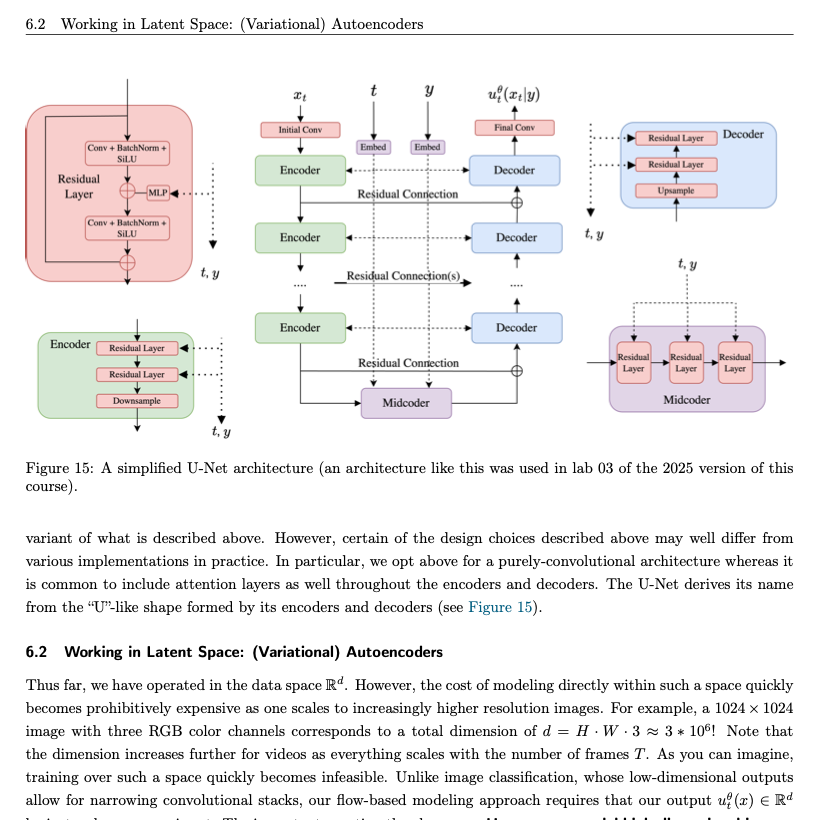
"An Introduction to Flow Matching and Diffusion Models" is a set of MIT lecture notes for the course "Generative AI With Stochastic Differential Equations" (2026) that provides a clear introduction to the mathematics behind modern generative AI.
The notes discuss flow matching and denoising diffusion models as core techniques behind many advanced generative systems, with references to models such as Stable Diffusion 3, FLUX, VEO-3, and AlphaFold3.
They develop the mathematical foundations of generative modelling, covering topics such as sampling from probability distributions, ordinary and stochastic differential equations, Brownian motion, diffusion processes, flow matching, score matching, classifier-free guidance, architectures for image and video generation, latent spaces, autoencoders, and discrete diffusion models for language generation.
What I particularly appreciated is the teaching style. The notes first build geometric and probabilistic intuition and only then derive the complete mathematical formulations. The result is a treatment that is rigorous, visual, and remarkably approachable.
This is probably one of the best freely available resources for understanding what is actually happening under the hood of diffusion models from a mathematical perspective.
https://t.co/J96rHCBPrb
probably the best blog i have read for some time
viewing SFT, RL, and OPD as different ways of reshaping a model's distribution makes their tradeoffs super intuitive.
- SFT pulls toward a fixed external target
- RL moves along the reward gradient on on-policy samples
- OPD sits in between, using a teacher signal but on student-generated data, which is why it inherits RL's anti-forgetting properties even when the teacher itself was an overtrained SFT model.
the post is heavily grounded in recent literature and uses the distributional perspective as a unifying bridge across all three paradigms, i really like the point it argues the load-bearing ingredient is on-policy data and OPD's convergence to RL-like outcomes is the strongest evidence
read this lambda's blog last night on Distributed Training Guide (precisely ddp)
sharing it since it contains concise info on torchrun & mpirun to get started with pytorch code on resnet model.
Recently met @srush_nlp and he started giving me an impromptu lecture on how targeted on-policy self-distillation works.
I asked him if I could record it on my iPhone.
The basic idea is this: if the model made a mistake at some point in the rollout (for example, calling a tool that doesn't exist), we want to discourage this specific error, but we don't want to just learn from the final reward, because it's a very noisy signal spread out over the whole trajectory.
So we have another model read this trajectory and figure where the error was made. It simply inserts some hint tokens to the part of the trajectory right above where the mistake was made.
Now with these injected hint tokens, have the model run a forward pass. You're not having to regenerate a new rollout - aka no new decode required.
The hint causes the model to assign lower probabilities to the error tokens. You then trains the original model to match these new probabilities, teaching it to downweight that specific mistake.
It's been 1 month since we dropped The Ultimate Guide to RL Environments 🚀
The response has been incredible:
• 25k+ article reads
• 500k+ impressions across socials
• Countless conversations, forks, and new environments built
If you're working on RL for LLMs and haven't checked it out yet, now's a good time 👇
Most people training agentic LLMs with RL right now have a silently broken training loop and have no idea.
Here's the trap: single-turn RL works beautifully. Clean curves, sane rewards, everything converges. Then you add tools so the model can act mid-rollout, and things get weird. Loss spikes for no reason. Eventually a shape-mismatch error.
The culprit: every time you parse the model's output to detect a tool call, then re-tokenize the updated conversation for the next turn, you're rolling the dice. Usually the round-trip gives back the same tokens. Sometimes it doesn't and your gradient lands on a sequence the model never actually sampled. No crash. Just quietly wrong math and a useless gradient signal.
The fix is one rule: never re-encode tokens you've decoded. Keep the sampled tokens in one buffer, never re-render them, and both failure modes disappear. That's Token-In, Token-Out done right.
Our team just published a beautiful deep-dive on exactly this, including an audit across the major open-weights model families showing most chat templates already support it. Required reading if you're doing multi-turn RL 🤗🔥
https://t.co/zmx0EQl3jM
Today we released the English version of Hands-On Modern RL along with a downloadable PDF, fully open and free. The course spans from CartPole to LLM post-training, RLVR, and Agentic RL. Welcome to check it out and share feedback 😆
New blackboard lecture w @ericjang11
He walks through how to build AlphaGo from scratch, but with modern AI tools.
Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn.
Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k+ tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second.
Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside.
Timestamps:
0:00:00 – Basics of Go
0:08:06 – Monte Carlo Tree Search
0:31:53 – What the neural network does
1:00:22 – Self-play
1:25:27 – Alternative RL approaches
1:45:36 – Why doesn’t MCTS work for LLMs
2:00:58 – Off-policy training
2:11:51 – RL is even more information inefficient than you thought
2:22:05 – Automated AI researchers
Excited to launch the accompanying free RLHF Course for my book. To kick it off, I've released:
- Welcome video
- Lecture 1: Overview of RLHF & Post-training
- Lecture 2: IFT, Reward Models, Rejection Sampling
- Lecture 3: RL Math
- Lecture 4: RL Implementation
I'm going to add question & answer videos throughout the lecture to go deeper on topics that need it, and potentially cover some topics that are too recent and in flux to go in print. I expect 10-15 videos in total over the next few months.
At the same time, development around the code for the book is picking up. It's a great time to build the foundation for post-training methods.
YT playlist and course landing page below.
CMU Advanced NLP: Reinforcement Learning
I had been curious about how RL works on top of LLMs, and this CMU lecture made it much clearer for me:
Pretraining/fine tuning focus on the next token;
RL focuses on the reward of the whole output: correctness, helpfulness, safety, etc.
That also explains why RL is hard: reward hacking, delayed credit assignment, and noisy updates can destabilize training.
So practical RL for LLMs needs stabilizers like KL divergence and PPO.
My note: https://t.co/oVrdh8Zqm4
*Finally* read through @samwhoo's blog on LLM quantization.
It's incredible.
For many (even in tech) the understanding of how LLMs work stops at the surface level. Sam is helping us all go deeper, digging into the interesting facets of how AI models truly work.
Read it!
If I had to start System Design from scratch again, I’d ignore 90% of the internet…
…and just study these 40 articles.
No random YouTube hopping.
No endless tabs.
No confusion.
Just a clean, structured path that actually works.
This is the roadmap I *wish* I had during my interview prep 👇
You’ll learn:
• How to think in systems (not just memorize answers)
• Real trade-offs (scalability vs consistency, latency vs cost)
• How to design like a senior engineer
And the best part?
You can even:
→ Ask questions via voice in real-time
→ Get instant feedback
→ Practice HLD even as a beginner
Here’s the full breakdown:
1. HLD Basics → https://t.co/I6E3xWnnPV
2. Core Concepts & Trade-offs → https://t.co/guimX30aqb
3. Networking & DNS → https://t.co/mEQN53UdRK
4. Load Balancing & Scaling → https://t.co/kKWa0cgDfU
5. Application Architecture → https://t.co/pBzsfCiUVC
6. Databases → https://t.co/Aq4AJBSTWy
7. Caching → https://t.co/SjJ4m8qhhP
8. Async Processing → https://t.co/1S25lPgiEC
9. Communication Protocols → https://t.co/v5Lse3k0wP
10. Performance & Monitoring → https://t.co/eQOXMGYVqj
11. Cloud Design Patterns → https://t.co/20nRBjreAn
12. Reliability Patterns → https://t.co/bWuWBbzqEZ
Save this.
This is easily 50+ hours of scattered learning—compressed into one roadmap.
Follow this, and System Design will finally start making sense.
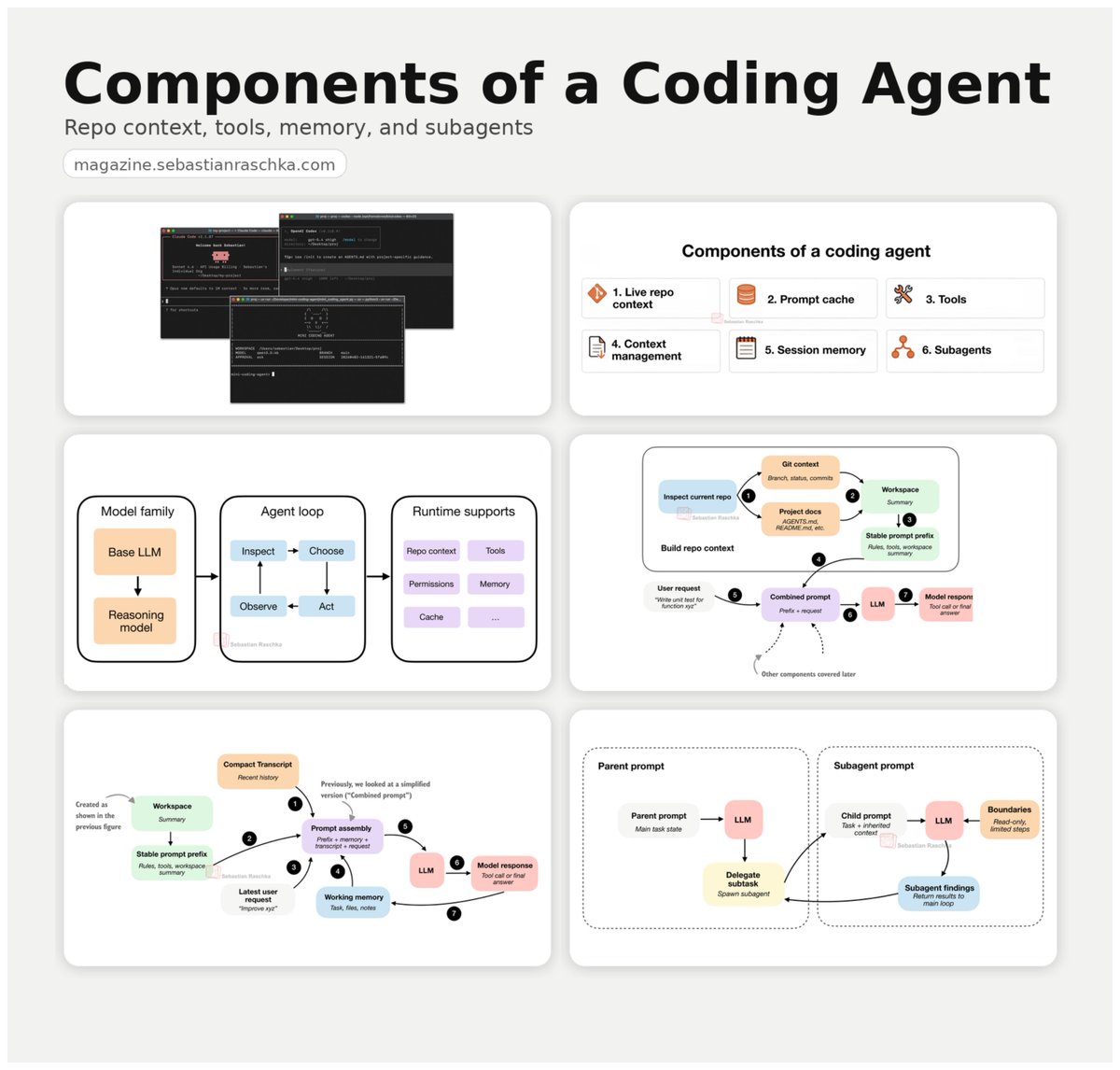
Components of a coding agent: a little write-up on the building blocks behind coding agents, from repo context and tool use to memory and delegation.
Link: https://t.co/iF4DsMcnhj
someone built a web-based System Design Simulator.
you drag and drop components (api gateways, dbs, caches) and it actually simulates real-time traffic.
you can watch latency, bottlenecks, and failures happen live...
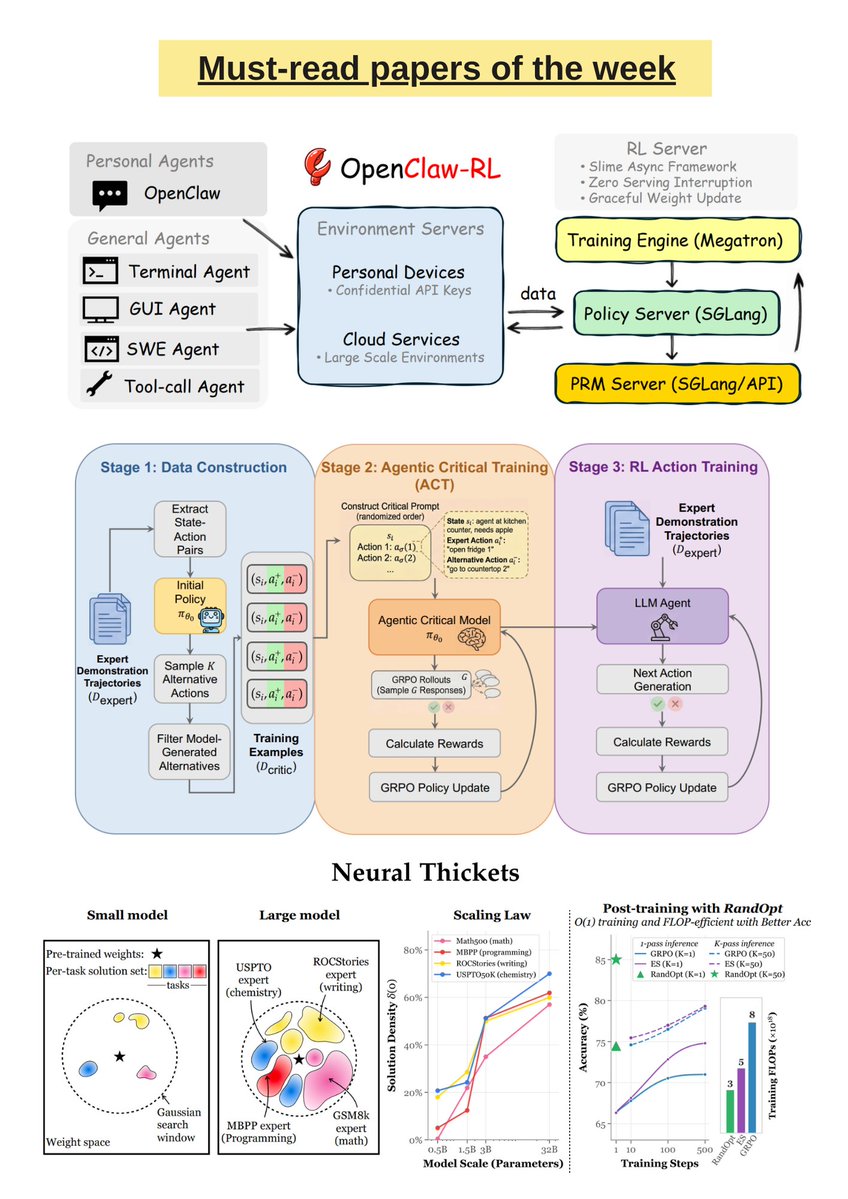
Must-read AI research of the week:
▪️ OpenClaw-RL
▪️ Meta-Reinforcement Learning with Self-Reflection for Agentic Search
▪️ Agentic Critical Training
▪️ Video-Based Reward Modeling for Computer-Use Agents
▪️ AutoResearch-RL
▪️ Neural Thickets
▪️ Training Language Models via Neural Cellular Automata
▪️ The Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
▪️ Lost in Backpropagation: The LM Head is a Gradient Bottleneck
▪️ IndexCache
▪️ Attention Residuals
▪️ REMIX: Reinforcement Routing for Mixtures of LoRAs in LLM Finetuning
▪️ Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
▪️ Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
▪️ How Far Can Unsupervised RLVR Scale LLM Training?
▪️ Examining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training
▪️ Reading, Not Thinking: Understanding and Bridging the Modality Gap When Text Becomes Pixels in Multimodal LLMs
▪️ Scale Space Diffusion
Find the full list and the main AI news and updates from NVIDIA GTC here: https://t.co/T985DbaCvR