Wow.
@Zai_org GLM 5.2 is a marvel! It is *at least* as good as Opus 4.8 and GPT 5.5. It's super fast, inexpensive, and not too verbose.
It responds with nuance and judgement, & handles long context VERY well.
I've never experienced an open weights model like this before.
Codex can now hand off threads between local and remote hosts.
Start work on your laptop, send it to a remote box before you close the lid, bring it back later.
And yes, Codex can orchestrate the handoff for you.
Many people think any given ML project is 99% training.
In reality, it’s 50% evaluation, 40% data cleaning, 8% integration, and 2% training.
The first two set the noise floor for learning. No ML magic matters; the model cannot lower the noise floor, as that’s the optimal bound of Shannon encoding of your data.
Thus, not a single day goes by without me thinking about ontology. Even the old labels have to be constantly reviewed.
Linux monitoring tools you SHOULD have
- btop - sleek UI, CPU + GPU stats, lots of themes
- glances - all‑in‑one overview (CPU, memory, disk, network)
- nvtop / nvitop - GPU graphs, PCIe metrics, power & temp (way better than nvidia‑smi)
- duf - high taste disk usage utility
Docker quietly created its biggest competitor.
It’s called Podman.
And a lot of Linux developers are switching fast.
Why?
Because Podman removes one of Docker’s biggest architectural problems:
the daemon.
No central background service.
No always-running root process.
No giant privileged attack surface.
Instead you get:
• rootless containers
• Docker-compatible CLI
• Kubernetes integration
• OCI support
• pods
• systemd integration
• lower idle resource usage
And most Docker commands still work almost identically.
The bigger trend here is fascinating:
developers are moving toward infrastructure that is:
• lighter
• rootless
• open
• daemonless
• easier to secure
Modern Linux tooling is evolving incredibly fast.
Andrej Karpathy: "90% of what AI twitter tells you to learn will be dead in 6 months"
90% of what ai twitter tells you to learn dies in 6 months
senior engineers already stopped chasing it
the dead list: autogen, crewai, autonomous agent pitches, agent marketplaces, benchmark leaderboards, semantic kernel, dspy as a general framework, horizontal "build any agent" platforms, per-seat pricing for agents
the pattern is obvious. demos that break in production. hype that never ships. frameworks that go viral on monday and vanish by spring
what actually compounds:
context engineering
tool design
orchestrator-subagent pattern
eval discipline
the harness mindset. harness > model, always
mcp as the protocol layer
the edge isn't the newest framework. it's staying a few steps ahead until your signal becomes everyone's mass-opinion
book and study this
Query Optimization Techniques
Ten tips for writing efficient and faster SQL queries:
1. Use column names instead of * in a SELECT statement
2. Avoid including a HAVING clause in SELECT statements
3. Eliminate unnecessary DISTINCT conditions
4. Un-nest sub queries
5. Consider using an IN predicate when querying an indexed column
6. Use EXISTS instead of DISTINCT when using table joins that involves tables having one-to-many relationships
7. Try to use UNION ALL in place of UNION
8. Avoid using OR in join conditions
9. Avoid functions on the right hand side of the operator 10. Remove any redundant mathematics
Read the whole paper here:
https://t.co/8BkUFIIJYx
Keep database access fast, so you have no issues.
Here are 5 things that can help:
1- Use Indexing Wisely
Start by indexing columns frequently used in WHERE clauses, JOIN conditions, and ORDER BY statements.
Avoid adding too many indexes; it will slow down the insertion or updating of data.
2- Reduce Database Calls Per Page
If you call the Database 20 times per page view, you are screwed no matter what you do.
Cache aggressively at different levels to offload the Database and speed up data retrieval.
3- Try to make a read-only database if you can
Separate Database reads from writes. If you don't have a lot of RAM and you do reads and writes, you get paging involved, which can hang your system for seconds.
Set up a separate copy of your main Database just for reading data.
This copy handles all read requests, while the main Database focuses on updates and changes.
4 - Denormalize data
If you have to fetch stuff from 20 different tables, try making one table just used for reading.
Create a simplified table that contains the most frequently used data from multiple tables, specifically for reading.
This reduces the number of steps needed to fetch data, making the application faster. Update this table regularly to keep it accurate.
5- Build a Search index if you need to search a lot.
Use a dedicated search index like Elasticsearch, Azure Search, or a full-text search feature in your Database.
A search index is optimized for quick searches, allowing you to find data faster than regular database queries.
Keep your friends close; keep your Database closer!
So @loaibassam asked me my stack recently, I replied:
FREE:
Nginx web server on Ubuntu (free)
Auto upgrade with unattended-upgrade (free)
Scheduled workers with Cron (free)
Vanilla PHP for site backend (free)
Vanilla CSS (free)
Vanilla JS for code (free)
Game servers I do in vanilla Node JS (free)
SQLite for DB (free)
Python for tool scripts (free)
Cloudflare with Cloudflare tunnel for DNS/SSL (free)
Tailscale for security (free)
OpenFreeMap for maps (free)
CHEAP:
xAI for AI API (cheap)
Stripe for payments (cheap)
Cloudflare R2 for image storage (cheap)
Hetzner VPS ($4/mo)
Cloudflare domain reg (~$10/year)
So about ~$5/mo total costs with about ~5M unique visitors per month per site (these are site averages)
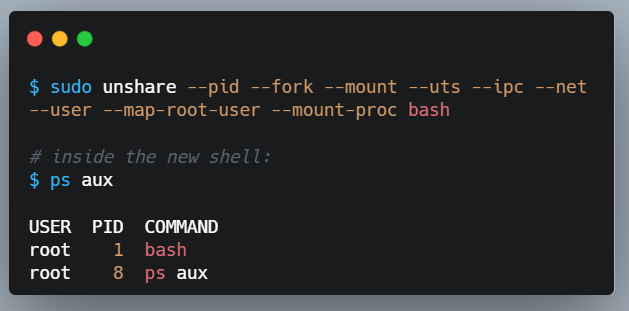
on linux, you can run a program in an isolated environment its own process tree, mount view, hostname, network, and more without docker or any container runtime.
the kernel does it directly.
it’s called unshare. only a few processes visible. the rest of the system is hidden.
Our @golang load balancer at @render handles more than 150 billion HTTP requests a month across millions of services.
The number of times we've wanted to rewrite it in Rust: zero.
Go is the most underrated language in infrastructure. "Boring" is the ultimate feature.
This 2 hour Stanford lecture will teach you more about how LLMs like ChatGPT & Claude are built than most people working at top AI companies learn in their entire careers.
Bookmark this & give 2 hours today, no matter what. It'll be the most productive thing you do this week.
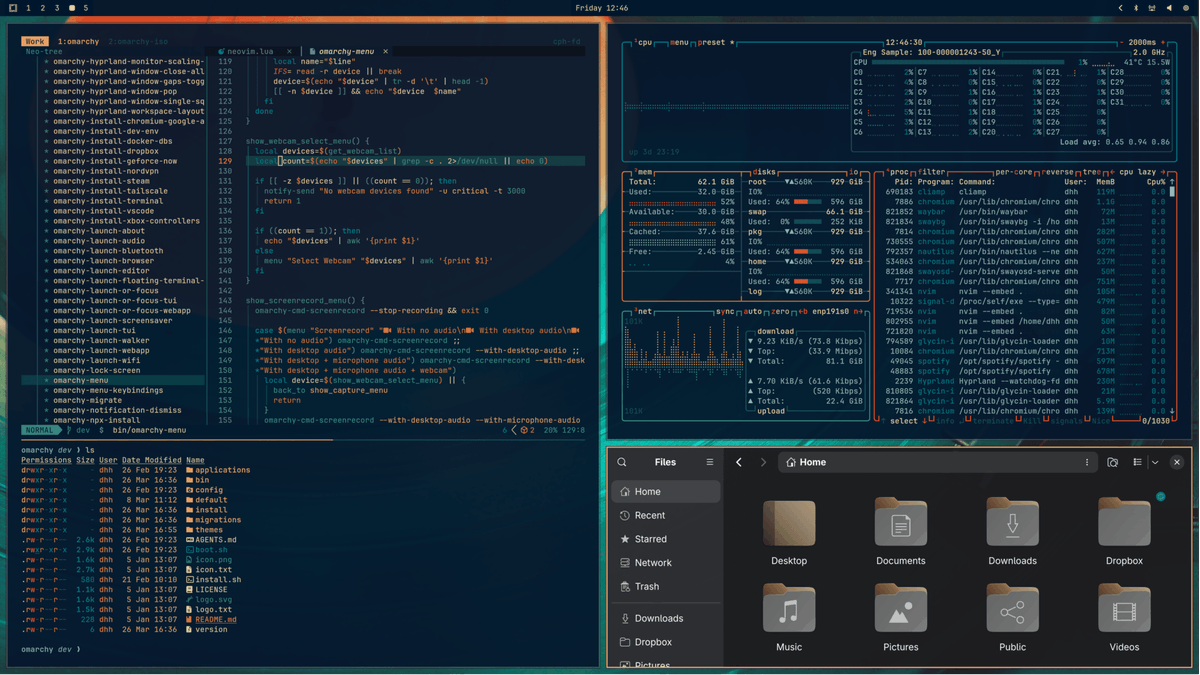
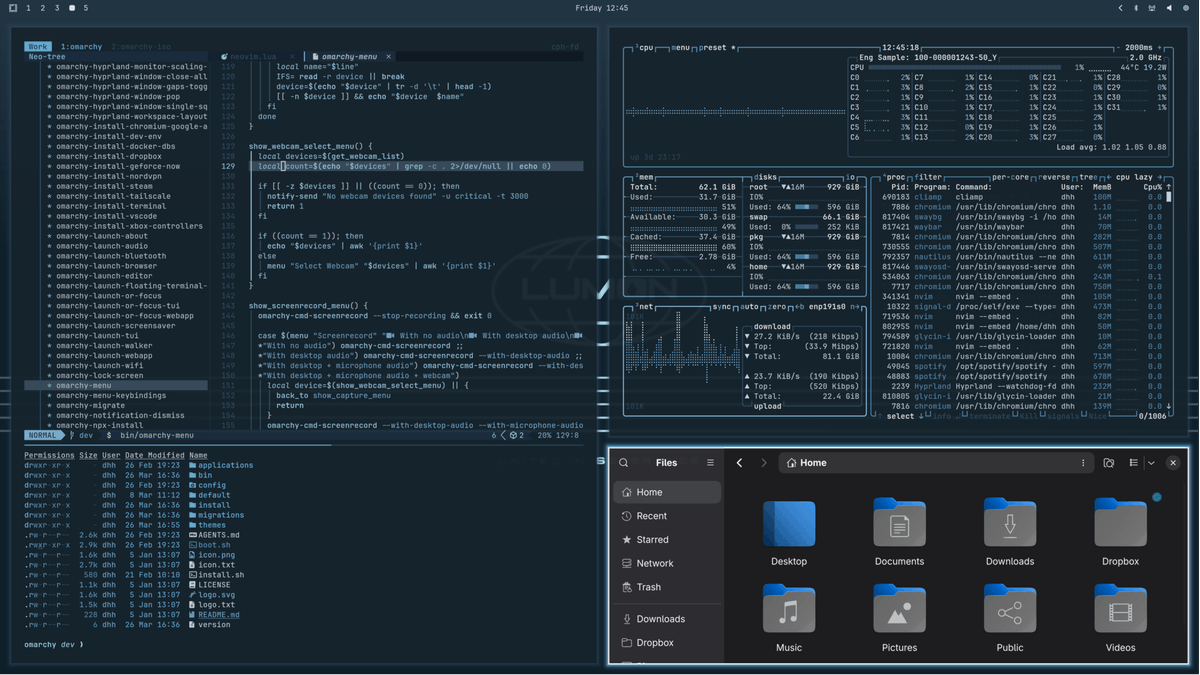
Omarchy 3.5 is out with full Panther Lake support thanks to co-development by @intel and @dell. We're seeing idle draws in the 1-3w range and real-world mixed use of 16+ hours on ~74wh batteries. Amazing chipset! Also, two beautiful new themes. Enjoy! https://t.co/jFkN9KWEta