jane street has some interesting blogs
too bad it would take a week to understand each
https://t.co/Z00MpzUDiU
https://t.co/qMXCn5wO8J
https://t.co/OdSGZzzYSY
https://t.co/kTgOenAhVT
Static benchmarks are dying — they tend to get saturated quickly.
Evaluation and training data should co-evolve with frontier models.
We released BenchEvolver — a framework that automatically evolves saturated problems into harder, verified tasks for evaluating frontier models, which can also serve as useful self-improvement signals for RL.
New work from UC Berkeley @berkeley_ai@BerkeleyRDI@BerkeleySky
Project Page: https://t.co/PL1KpGyd87
Paper: https://t.co/gBQOXrZbAV
New paper on truthful AI!
We introduce a definition of “lying” for AI
We explore how to train truthful ML models
We propose institutions to support *standards* for truthful AI
We weigh costs/benefits (economy + AI Safety)
(w/ coauthors at Oxford & OpenAI)
https://t.co/9QII1WXFqw
We really don't understand AI lying fully.
What happens when an AI lies? How can you best detect it? Can white-box detectors beat black-box ones in an adversarial setting?
It is an ongoing interpretability challenge.
We'd like you to try your hand at it. Join our contest!
But AI lie detection is hard and remains a central research challenge.
Recent research suggests that simple probes can pick up on neural "tells" that reveal when it is lying, even when the output looks clean.
https://t.co/zTQIaNcpag
https://t.co/wVCwKlGVIr
Interestingly, training compute for open-weight AI models doesn't appear to have grown very much in the last 2 years. Llama 3.1-405B (and derivative models) still holds the record 2 years later. Data from Epoch. https://t.co/DWBq23xNAt
Introducing Q-Judger and Qwen-Image-Bench, an automated T2I evaluation suite from Qwen team. Apache 2.0. 🤖 https://t.co/hv3R6iU9UX
Q-Judger is built on Qwen3.6-27B with thinking mode. Input prompt + image, get structured JSON scores across 5 dimensions: Quality, Aesthetics, Alignment, Real-world Fidelity, Creative Generation. Spearman ρ = 0.92 vs human expert rankings. Trained on 130K+ bilingual pairs supervised by 80 professional annotators from art academies.
Announcing Zoo's completely redesigned sketch mode! You can sketch complex 2D geometry SO much quicker now. So many improvements:
- Constraint solver
- Trim tool (remove parts of intersecting geometry)
- Select regions (overlapping 2D spaces) for extrude
It's a big upgrade.
The #CVPR2026 Art Gallery is now live 🥳
114 artworks using or about computer vision, presented online and as videos and installations at the @CVPRConf in Denver between 5-7 June next week 😍
Check it out https://t.co/XTGoCWaDV8
#creativeAI#AIart
Today we’re releasing DeepSWE, a new standard for agentic coding benchmarks.
On public leaderboards, top models often look relatively close in capability. DeepSWE shows where they actually diverge, reflecting the realistic experience of developers in their day-to-day work.
You can’t make scientific breakthroughs without the tools to pursue them.
Big news from @NSF: $250M to restart and supercharge the SBIR/STTR program, including a new $40M pilot for next-gen scientific instrumentation.
America’s small businesses will build the platforms that define discovery.
https://t.co/a0z16TawAy
The radar plot is the most popular chart in football analytics. It might also be the least effective.
Chris Fonnesbeck breaks down why and builds the replacement: https://t.co/DeOScY3tfh
#SportsAnalytics#DataViz#Bayesian
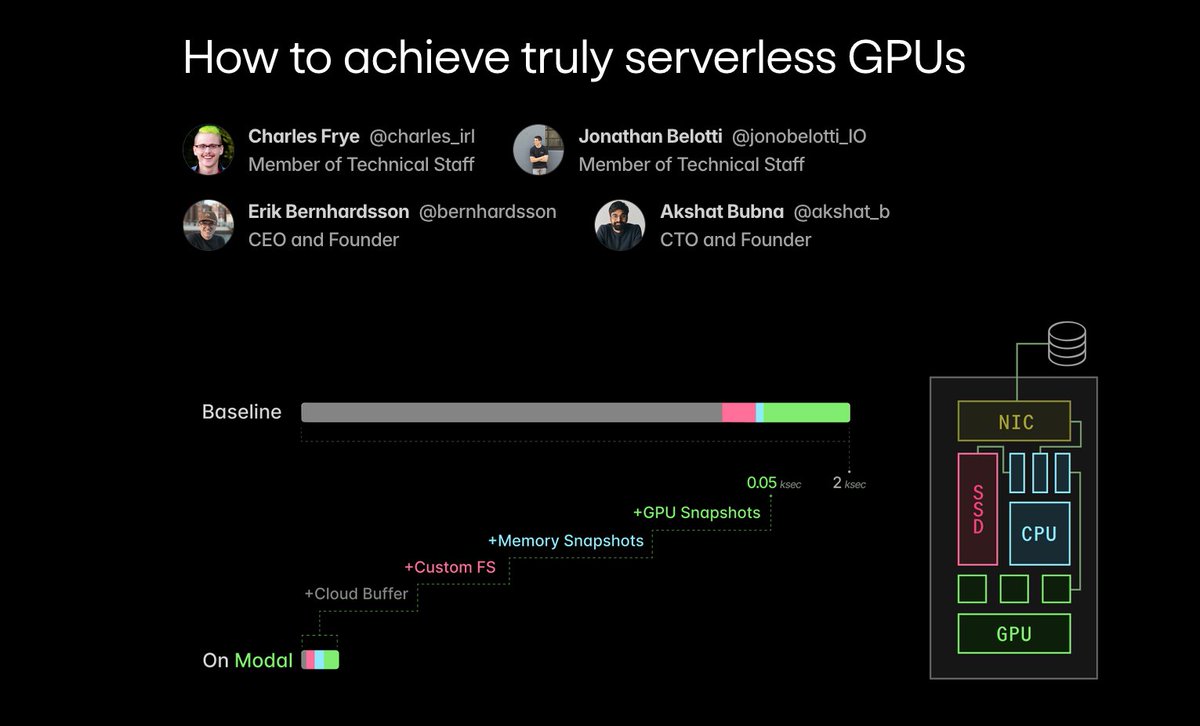
Inference isn't everything, but it does require a new stack -- not Kubernetes, not SLURM.
At @modal, we dove deep to build that stack.
In this blog post we explain how, from compute management & cloud-native cacheing to CRIU & GPU checkpointing.
https://t.co/DQ4wvuXjre