Local minima are rare in high dimensions because a strict local minimum has to curve upward in every direction, so all Hessian eigenvalues must be positive.
In a D-dimensional toy model where eigenvalue signs are independent, that’s a 2^(-D) event. In GOE-like random matrix models, positive definiteness is even rarer, roughly exp(-cD^2).
So as dimension grows, random critical points are much more likely to be saddles than minima. This is one reason high-dimensional optimization is often a saddle-escape problem, not a bad-local-minimum problem.
Wrote up some of the math here: https://t.co/vkaVqVD64N
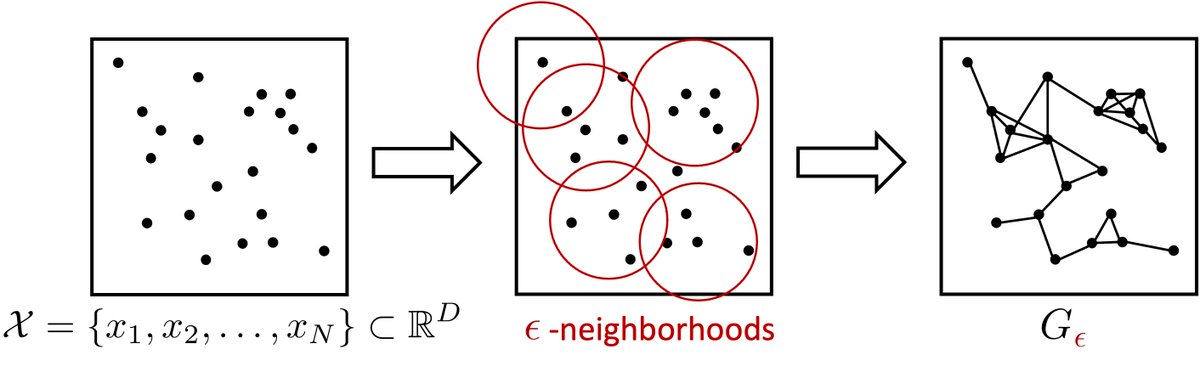
Can we learn the curvature of a data manifold from a finite sample? We study continuum limits of Ollivier’s Ricci curvature on geometric graphs, proving pointwise consistency and showing that positive lower bounds on the underlying manifold are inherited by the graph with high probability. We further discuss applications to heat kernels and manifold learning.
With Nicolás García Trillos. Now published in Discrete & Computational Geometry: https://t.co/fnArhFeMdx
very awesome resource from hugging face with available slides about how they generated 1T synthetic data
a really cool sneak peek at what we feed foundation models
A critical initialization for biological neural networks
Spontaneous brain activity is often treated as noise: the background hum of a nervous system waiting for a task. But large-scale recordings in mice have shown something more structured. Even in darkness, without explicit stimuli, thousands of neurons display coordinated activity patterns that extend across the brain and persist far longer than the fast biophysical timescales of individual neurons.
Marius Pachitariu and coauthors ask a simple question: could this macroscopic structure emerge from a simple kind of network initialization?
Their answer connects neuroscience, random matrix theory and machine learning. They model spontaneous neural activity as linear dynamics governed by a random connectivity matrix, stabilized by a global inhibitory-like normalization. When this matrix is symmetric and critically normalized, with its largest eigenvalue very close to one, the network naturally produces high-dimensional activity modes with a power-law covariance spectrum.
This is not just a mathematical curiosity. The same spectral structure appears in large-scale mouse recordings from cortex and brainwide Neuropixels data, with power-law exponents around 0.7–0.85. Hippocampal CA1 is the striking exception: its activity looks less correlated, closer to an efficient, high-capacity code for information storage.
The ML perspective is especially interesting. In artificial neural networks, initialization is often treated as a technical detail: Xavier, He, orthogonal schemes, and so on. But this paper reframes initialization as a computational substrate. A critically initialized recurrent system can generate slow, global, high-dimensional modes before task-specific learning. In simulations, these dynamics support time-dependent computations, including zero-shot working memory tasks.
The biological implication is powerful: spontaneous activity may not be random noise, but a preconfigured dynamical scaffold on which learning and computation can operate. The brain may start from an initialization already close to useful temporal memory, with learning then shaping readouts or task-specific pathways.
For R&D teams building ML systems in drug discovery, materials development, energy research or biotechnology, the lesson is broader than neuroscience. Initialization, architecture and dynamics define what kinds of scientific signals a model can preserve, combine and retrieve before training. In applied research pipelines where data are scarce, noisy and time-dependent, designing the right dynamical substrate may be as important as choosing the loss function.
Source: Pachitariu et al., Nature (2026) — CC BY 4.0 | https://t.co/oE37FfYmKc
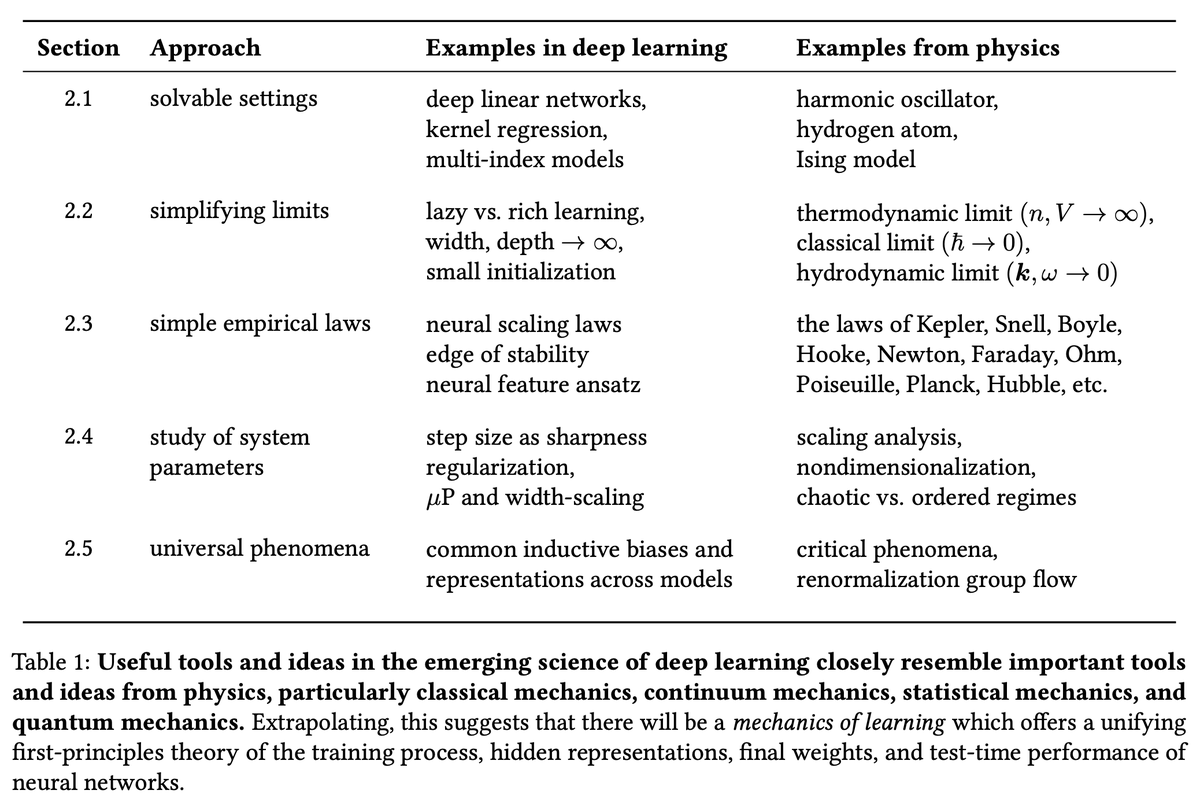
1/ Deep learning is going to have a scientific theory. We can see the pieces starting to come together, and it's looking a lot like physics!
We're releasing a paper pulling together these emerging threads and giving them a name: learning mechanics.
🔨 https://t.co/92nSIHameW 🔧
🚀We just released Asset Harvester, an image-to-3D model and end-to-end pipeline that extracts real object assets from autonomous driving videos!
🌐 Website: https://t.co/vXnFVW1ui8
💻 Code: https://t.co/3q3vcRvojy
[1/5]
#AssetHarvester#AVSimulation#WorldModel #AutonomousDriving
this is an unique perspective on muon: instead of explaining it purely as a spectral gradient normalization method the paper interprets it as the operator-norm endpoint of a broader family of spectral wasserstein gradient flows. love how it is beautifully explained by gabriel peyré by unifying ordinary wasserstein gradient flow, intermediate schatten-normalized flows and muon. pure elegance!
Earthset.
The Artemis II crew captured this view of an Earthset on April 6, 2026, as they flew around the Moon. The image is reminiscent of the iconic Earthrise image taken by astronaut Bill Anders 58 years earlier as the Apollo 8 crew flew around the Moon.
Wow, this tweet went very viral!
I wanted share a possibly slightly improved version of the tweet in an "idea file". The idea of the idea file is that in this era of LLM agents, there is less of a point/need of sharing the specific code/app, you just share the idea, then the other person's agent customizes & builds it for your specific needs.
So here's the idea in a gist format: https://t.co/NlAfEJjtJV
You can give this to your agent and it can build you your own LLM wiki and guide you on how to use it etc. It's intentionally kept a little bit abstract/vague because there are so many directions to take this in. And ofc, people can adjust the idea or contribute their own in the Discussion which is cool.
We see our home planet as a whole, lit up in spectacular blues and browns. A green aurora even lights up the atmosphere. That's us, together, watching as our astronauts make their journey to the Moon.
Meet Gemma 4: our new family of open models you can run on your own hardware.
Built for advanced reasoning and agentic workflows, we’re releasing them under an Apache 2.0 license. Here’s what’s new 🧵