THE FIRST MAN IN HISTORY TO BREAK 2 HOURS IN A MARATHON!!!🤯🤯🤯
Sabastian Sawe 🇰🇪 has just shattered the World Record at the London Marathon, running 1:59:30!!!
He makes history as the first man to officially break 2 hours in the marathon.
Yomif Kejelcha 🇪🇹 in his debut ran 1:59:41 to become 2nd fastest alltime, while Jacob Kiplimo 🇺🇬 finished in 2:00:28.
All under the previous World Record.
software is still about thinking
software has always been about taking ambiguous human needs and crystallizing them into precise, interlocking systems. the craft is in the breakdown: which abstractions to create, where boundaries should live, how pieces communicate.
coding with ai today creates a new trap: the illusion of speed without structure. you can generate code fast, but without clear system architecture – the real boundaries, the actual invariants, the core abstractions – you end up with a pile that works until it doesn't. it's slop because there's no coherent mental model underneath.
ai doesn't replace systems thinking – it amplifies the cost of not doing it. if you don't know what you want structurally, ai fills gaps with whatever pattern it's seen most. you get generic solutions to specific problems. coupled code where you needed clean boundaries. three different ways of doing the same thing because you never specified the one way.
as Cursor handles longer tasks, the gap between "vaguely right direction" and "precisely understood system" compounds exponentially. when agents execute 100 steps instead of 10, your role becomes more important, not less.
the skill shifts from "writing every line" to "holding the system in your head and communicating its essence":
- define boundaries – what are the core abstractions? what should this component know? where does state live?
- specify invariants – what must always be true? what are the constants and defaults that make the system work?
- guide decomposition – how should this break down? what's the natural structure? what's stable vs likely to change?
- maintain coherence – as ai generates more code, you ensure it fits the mental model, follows patterns, respects boundaries.
this is what great architects and designers do: they don't write every line, but they hold the system design and guide toward coherence. agents are just very fast, very literal team members.
the danger is skipping the thinking because ai makes it feel optional. people prompt their way into codebases they don't understand. can't debug because they never designed it. can't extend because there's no structure, just accumulated features.
people who think deeply about systems can now move 100x faster. you spend time on the hard problem – understanding what you're building and why – and ai handles mechanical translation. you're not bogged down in syntax, so you stay in the architectural layer longer.
the future isn't "ai replaces programmers" or "everyone can code now." it's "people who think clearly about systems build incredibly fast, and people who don't generate slop at scale."
the skill becomes: holding complexity, breaking it down cleanly, communicating structure precisely. less syntax, more systems. less implementation, more architecture. less writing code, more designing coherence.
humans are great at seeing patterns, understanding tradeoffs, making judgment calls about how things should fit together.
ai can't save you from unclear thinking – it just makes unclear thinking run faster.
Today, on @ethereum's 10th anniversary, we’re launching EigenDA V2 with 100 MB/s throughput, making it the first data availability solution to break the THREE-digit barrier.
As Ethereum enters its second decade, we’re proud to help scale its next wave of innovation.
Learn more 🧵
New blog post about asymmetry of verification and "verifier's law": https://t.co/28Ly8NHJWZ
Asymmetry of verification–the idea that some tasks are much easier to verify than to solve–is becoming an important idea as we have RL that finally works generally.
Great examples of asymmetry of verification are things like sudoku puzzles, writing the code for a website like instagram, and BrowseComp problems (takes ~100 websites to find the answer, but easy to verify once you have the answer).
Other tasks have near-symmetry of verification, like summing two 900-digit numbers or some data processing scripts. Yet other tasks are much easier to propose feasible solutions for than to verify them (e.g., fact-checking a long essay or stating a new diet like "only eat bison").
An important thing to understand about asymmetry of verification is that you can improve the asymmetry by doing some work beforehand. For example, if you have the answer key to a math problem or if you have test cases for a Leetcode problem. This greatly increases the set of problems with desirable verification asymmetry.
"Verifier's law" states that the ease of training AI to solve a task is proportional to how verifiable the task is. All tasks that are possible to solve and easy to verify will be solved by AI. The ability to train AI to solve a task is proportional to whether the task has the following properties:
1. Objective truth: everyone agrees what good solutions are
2. Fast to verify: any given solution can be verified in a few seconds
3. Scalable to verify: many solutions can be verified simultaneously
4. Low noise: verification is as tightly correlated to the solution quality as possible
5. Continuous reward: it’s easy to rank the goodness of many solutions for a single problem
One obvious instantiation of verifier's law is the fact that most benchmarks proposed in AI are easy to verify and so far have been solved. Notice that virtually all popular benchmarks in the past ten years fit criteria #1-4; benchmarks that don’t meet criteria #1-4 would struggle to become popular.
Why is verifiability so important? The amount of learning in AI that occurs is maximized when the above criteria are satisfied; you can take a lot of gradient steps where each step has a lot of signal. Speed of iteration is critical—it’s the reason that progress in the digital world has been so much faster than progress in the physical world.
AlphaEvolve from Google is one of the greatest examples of leveraging asymmetry of verification. It focuses on setups that fit all the above criteria, and has led to a number of advancements in mathematics and other fields. Different from what we've been doing in AI for the last two decades, it's a new paradigm in that all problems are optimized in a setting where the train set is equivalent to the test set.
Asymmetry of verification is everywhere and it's exciting to consider a world of jagged intelligence where anything we can measure will be solved.
Great to see!
I was inspired to do this by having to early exercise my options when I left Airbnb (which was an unexpected outlay of cash). And from conversations with Pinterest and Sam Altman around that time.
Glad we did it, and we should have made it 10 years.
.@eigen_da V2 is on the way.
So far on Conduit testnets, latency for blob commitments is down from 10 minutes to 30 seconds.
Near-term goal: 10 seconds.
Faster and faster 🏎️
Slashing goes live on mainnet today! 🥳
The protocol is now feature-complete.
Programmable trust is no longer a concept. It’s code.
Let’s talk about what this unlocks & why it matters. 🧵
EigenDA is now the LARGEST alternative DA provider in the world (in TVL secured).
Meet the new blueprint for scaling the next decade of crypto infrastructure.
Why @Mantle_Official trusts EigenDA to verify and secure $1.3B in value 🧵
It's official.
EigenDA has now been fully activated on Mantle Network Mainnet.
We're proud to be the first and largest L2 to adopt @eigen_da and partner with @eigencloud — unlocking unprecedented scalability, censorship resistance, and security.
ZK rollups just got faster, cheaper, and more secure as @eigencloud brings decentralized proving and @eigen_da to @zksync's Elastic Network.
Why this matters for builders 👇
(Plus: link to a brand new @therollupco episode where @sreeramkannan and @gluk64 break it down)
I don't have too too much to add on top of this earlier post on V3 and I think it applies to R1 too (which is the more recent, thinking equivalent).
I will say that Deep Learning has a legendary ravenous appetite for compute, like no other algorithm that has ever been developed in AI. You may not always be utilizing it fully but I would never bet against compute as the upper bound for achievable intelligence in the long run. Not just for an individual final training run, but also for the entire innovation / experimentation engine that silently underlies all the algorithmic innovations.
Data has historically been seen as a separate category from compute, but even data is downstream of compute to a large extent - you can spend compute to create data. Tons of it. You've heard this called synthetic data generation, but less obviously, there is a very deep connection (equivalence even) between "synthetic data generation" and "reinforcement learning". In the trial-and-error learning process in RL, the "trial" is model generating (synthetic) data, which it then learns from based on the "error" (/reward). Conversely, when you generate synthetic data and then rank or filter it in any way, your filter is straight up equivalent to a 0-1 advantage function - congrats you're doing crappy RL.
Last thought. Not sure if this is obvious. There are two major types of learning, in both children and in deep learning. There is 1) imitation learning (watch and repeat, i.e. pretraining, supervised finetuning), and 2) trial-and-error learning (reinforcement learning). My favorite simple example is AlphaGo - 1) is learning by imitating expert players, 2) is reinforcement learning to win the game. Almost every single shocking result of deep learning, and the source of all *magic* is always 2. 2 is significantly significantly more powerful. 2 is what surprises you. 2 is when the paddle learns to hit the ball behind the blocks in Breakout. 2 is when AlphaGo beats even Lee Sedol. And 2 is the "aha moment" when the DeepSeek (or o1 etc.) discovers that it works well to re-evaluate your assumptions, backtrack, try something else, etc. It's the solving strategies you see this model use in its chain of thought. It's how it goes back and forth thinking to itself. These thoughts are *emergent* (!!!) and this is actually seriously incredible, impressive and new (as in publicly available and documented etc.). The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. The human would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome.
(Last last thought/reference this time for real is that RL is powerful but RLHF is not. RLHF is not RL. I have a separate rant on that in an earlier tweet
https://t.co/RMIpFPVpuM)
Data Availability is more important than you think.
Most people view the DA Layer as temporary storage for data access by users and apps. True, but that overlooks key details:
• why is temporary storage needed?
• who needs this storage?
• what kind of data needs to be stored?
• what if data is not stored correctly?
• why can't we just use Ethereum for all those purposes?
External DA solutions like @eigen_da can boost speed and throughput and lower costs while still offering strong security guarantees. Data Availability is a complex topic involving scalability, speed, economics, security, and architecture. So, why should we care?
1. Why does Data Availability matter?
The data availability problem simply asks:
"How can we ensure the data needed to reconstruct the blockchain's state is accessible?"
As most people already know, state is simply all the data stored on the blockchain at a given moment, which is constantly updated. That's also called liveness. Without this data, verifying transactions becomes impossible and opens the door for malicious block proposers.
Ethereum addresses this by requiring full nodes to download each block, verifying transactions by re-executing them against a local state copy. It does not work the same for rollups, obviously, because it sacrifices a lot of speed, but we still need to ensure data is available to maintain security.
But what data even is that? I referred to the state lots of times, so the data that needs to be available is "state data," a.k.a. transaction history. If data is not live, you sacrifice security and risk that your rollup won't be re-org resistant.
Reorgs can occur during L1 block finalization, which means that Ethereum might split into different versions due to malicious acts.
A rollup might align with a fork instead of the canonical chain until the correct chain is settled. Moreover, users might face censorship because of the weak DA layer where their transactions won't be included.
This not only poses technical challenges like data loss but also affects the UX/UI of user-facing applications.
The Data Availability problem first refers to security rather than speed and scalability.
2. What are the benefits of using an external DA layer like EigenDA?
Many rollups use Ethereum for data availability due to its strong security. So, is there any reason to use EigenDA? Yes, there are lots of them.
A rollup can be divided into multiple layers, including the settlement layer, DA layer, execution layer, etc. The overall idea of modular blockchain is to divide it into multiple components to maximize efficiency.
However, relying on Ethereum as a DA layer does not make much sense in cases where you're aiming not only for security but also for reducing costs. The surge of L2 solutions on Ethereum led to high competition for blockspace, making transactions costly.
By March 2024, L2s spent over $37.4 million for storing and accessing data on Ethereum. That changed after the introduction of blobs with a 99% reduction in price. Well, the price was fixed, but fees are still uncertain due to Ethereum congestion.
Rollups like @0xMantle and @megaeth use EigenDA because Ethereum is not a comfortable place to achieve high throughput. That means that Ethereum rollups must compete with other L1 transactions for limited blockspace, which can increase storage costs in the process.
• Ethereum blocks can handle 768kB from blobs plus other data, reaching about 2.5 MB total.
• With blocks every 12 seconds, this gives a bandwidth of 0.2 MB/s.
• It is pretty slow and approximately equals 9,000 TPS.
That is the TPS not for one rollup, but for all rollups that use Ethereum as a DA Layer. And yes, that's pretty slow + there is no horizontal scaling available (compute growth is not proportional to node growth).
Moreover, rollups that use EigenDA have the autonomy to handle their own state updates, in contrast to Ethereum-based rollups, which depend on Ethereum's network for managing changes.
3. How does EigenDA fix those problems?
• As I said before, rollups like MegaETH with their 100,000+ TPS are not able to use Ethereum for DA purposes.
• EigenDA currently has 15MB/s of write throughput.
• That means that it can handle up to 654,000 TPS with compression.
It is pretty suitable for chains that want to onboard apps where high throughput is needed, like APIs, different backends, HFT, etc. But why is it possible?
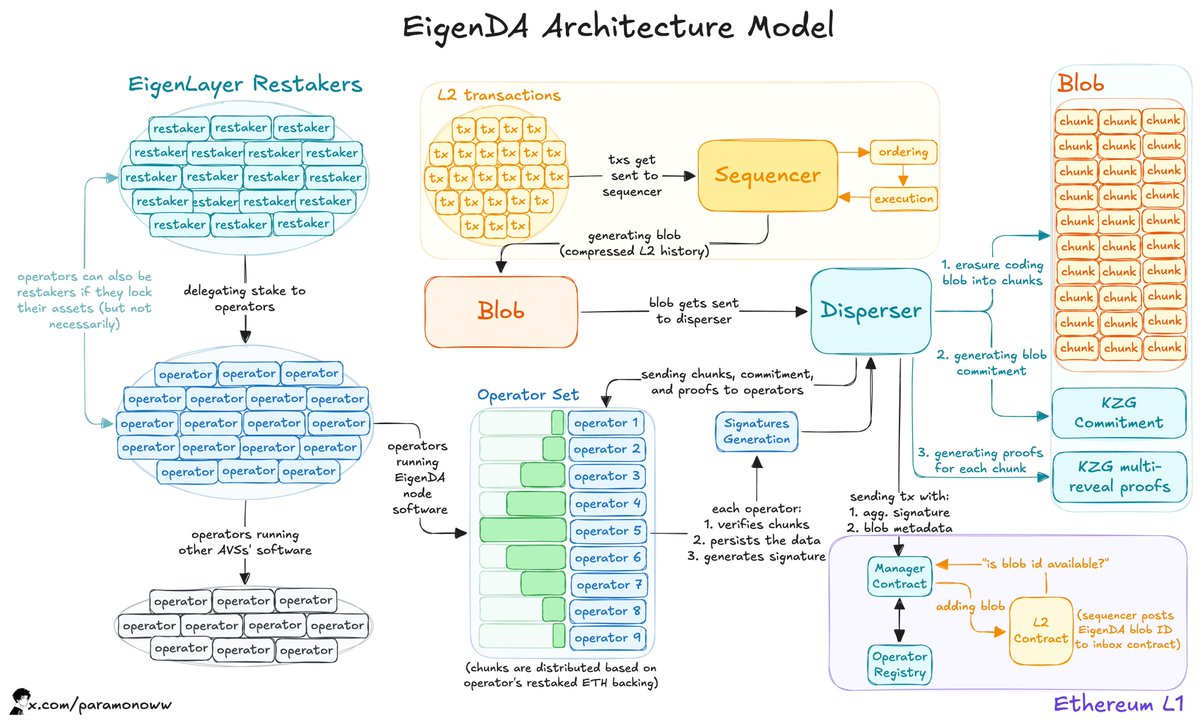
• When a rollup's sequencer sends a block to EigenDA, the disperser (an EigenDA component) erasure codes this blob into chunks, which are basically smaller parts of the blob.
• Those chunks are sent to different storage operators, getting confirmation that they have stored the data.
• The thing is that each unique storage operator processes their own unique set of chunks, so there are no two operators who process the same chunks.
This approach makes it possible for horizontal scaling to exist: more operators -> more chunks can be processed -> higher throughput -> higher TPS.
The average cost of storing 1MB of data in EigenDA is approximately $0.05 at the time of writing, which makes it pretty cheap and convenient for rollups who want to store their data and make it accessible at any given point in time.
At the beginning, I mentioned that data availability is security first. But how does EigenDA handle security in that case?
EigenDA is an AVS on EigenLayer, which means that EigenDA has its own operator set with stake delegated to those operators to economically secure EigenDA. There are over 200 operators with more than $15 billion in stake combined. So, this system is pretty secure.
Current DA systems often merge data accessibility verification with data ordering, creating complex setups. While verifying data can be done in parallel, ordering it for consensus is slow.
This is useful for systems managing their own data order but unnecessary for systems like EigenDA, which leverage Ethereum's existing ordering mechanisms.
EigenDA achieves greater speed and efficiency in data storage, thanks to its use of erasure coding and the KZG commitment scheme, which allows for storing only the minimal required data.
4. How does EigenDA work?
The EigenDA architecture might seem pretty complex at the beginning, but in the end, everything makes sense.
1) Rollup's sequencer sends a batch of L2 transactions in the form of a blob to the disperser.
2) Disperser divides this blob into small pieces (chunks) and creates two types of proofs: KZG commitment proof and KZG multi-reveal proofs.
3) All chunks are uniquely distributed across the EigenDA Operator Set (operators running EigenDA node software and having stake delegated to them).
4) Operators also receive the commitment proof to verify chunks against it using multi-reveal proofs.
5) Operators send signatures to the disperser that they have successfully verified the chunks.
6) Disperser aggregates received signatures, registers the blob on-chain by sending a transaction to the EigenDA Manager Contract.
7) Manager Contract checks with the Operator Registry that signatures are verified correctly.
8) Rollup sequencer sends an EigenDA blob ID to its inbox contract on Ethereum.
9) Inbox contract checks with the Manager Contract if the blob ID is indeed available.
10) If available, the blob ID is added to the inbox contract, and Ethereum’s rollup view is updated. If not, a malicious operator is slashed.
One important feature is that blobs are erasure coded at a 4.54 ratio. That means that the system provides more redundancy, which means the system can recover from more simultaneous node or storage failures without losing data.
The main reason to use erasure coding is to allow a single operator to store only one chunk, significantly reducing costs. As more operators join, individual costs drop.
5. What is the relationship between EigenDA and Ethereum consensus? Can’t rollup just use EigenDA?
Rollup can't use only EigenDA because it still needs to settle somewhere. And using EigenDA, you can only settle transactions on Ethereum.
EigenDA does not have its own consensus mechanism; it uses Ethereum's security and validator set through restaking. This means that a rollup or an end user relies on Ethereum's consensus to ensure that data is correctly ordered and finalized.
• The rollup determines the agreed-upon sequence of transactions.
• It then uses EigenDA for storage where transactions are posted in batches.
• The rollup posts the state roots to Ethereum for finalization.
• After the transactions are sequenced and recorded on the base layer, they are permanently added to the rollup chain, becoming irreversible (finalized) after a certain period.
6. If the DA layer is not secure enough, what happens?
There are two big problems a lot of teams are working on: re-org protection and censorship resistance.
Security against censorship and reorgs requires a robust DA layer where economic security prevents majority control. The primary design concern is the cost of consensus attacks.
As the old saying goes: "To minimize malicious behavior, we need to make it unprofitable."
A blockchain is economically secure when attack costs greatly exceed potential gains. Verifying proofs on Ethereum enhances rollup security against censorship but doesn't address all issues with data availability.
If the DA layer is compromised, the rollup remains vulnerable since Ethereum's smart contract only checks attestations. This can lead to liveness issues where new blocks can't be produced, illustrating that using one blockchain for data limits security assurances from another.
Before EigenDA, there were data availability committees which look pretty similar to dPoS. EigenDA is different because it's open for everyone who wants to run node software or delegate their assets. It also offers more security because operators can actually be slashed if acting maliciously.
7. Which apps need to access the DA network besides the rollup and Ethereum themselves?
Well, there are lots of them. DEXs, DeFi protocols, NFT marketplaces, DAOs, staking protocols, and interoperability protocols all require full transaction history for various purposes like liquidity tracking, financial calculations, authenticity verification, compliance, governance, reward calculation, and secure messaging.
@alt_layer uses EigenDA for rollups launched on their platform, @Calderaxyz lets you launch a rollup within 1 minute with EigenDA, etc. There are lots of different interesting use cases.
There has been a lot of "monolithic vs. modular" discussions over the past year, but in the Ethereum landscape, there has been more modular stuff winning.
Proposer-Builder Separation (PBS), DA layers, different sequencing modules, finality layers: it seems like every big part of the Ethereum ecosystem is in the process of being split into multiple ones and maximizing the efficiency of each part.
As I've said a lot in my previous writings, the future of millions of general-purpose rollups and app-specific rollups is inevitable, so if it's inevitable, let's make it efficient.
🚀 Breaking news: All Chains Fit on EigenDA!
------------
@eigen_da mainnet is now processing 15+ MB/second (120Mbps), and we are posting ALL raw block data from 15+ chains simultaneously.
------------
L1s: Bitcoin, Ethereum, Solana, Celo, Celestia, Avalanche, BNB chain, Fantom.
L2s: Polygon, Mantle, Base, Arbitrum, Optimism, XAI games, Blast, Scroll, ZKSync, Mode, Taiko.
------------
The *only* fully horizontally scalable system in crypto.
------------
All Ideas Fit on EigenDA.
You can even inscribe your idea into EigenDA!
------------
What breakthrough are you going to build on @eigencloud?
https://t.co/GRxkeeCFqf