Introducing https://t.co/eFXL4smK0t - a Claude "factory skill" that crawls your web app and generates a Playwright skill specific to your application that significantly speeds up QA flows Claude Code uses to debug or verify features and bug fixes. Will publish benchmark data soon
ANTHROPIC JUST DROPPED A ZERO TRUST PLAYBOOK FOR AI AGENTS
and it's not theory it's architecture
frontier AI compresses vulnerability-to-exploit timelines from months to hours
your agents face threats traditional access controls were never built to handle:
▫️ prompt injection through external data sources
▫️ tool poisoning via MCP server metadata
▫️ memory-based privilege retention across sessions
▫️ multi-agent pivot attacks
the framework breaks it into 3 tiers: Foundation, Enterprise, Advanced
https://t.co/uDuO9cq25H
I'm with @bchesky on this one.
I think the future is not about apps, but about agents.
But the shift to agents doesn't necessarily mean text-forward, chat-based UIs.
That makes sense for some use cases -- but not all.
The future is about agents that work on your behalf, often in the background, and let you interact in ways that make sense. Sometimes, that means typing text, but others it might be a personalized UI element.
UI affordances are underrated. Sometimes humans need some guidance and nudges instead of an empty prompt box.
I think hybrid agentic interfaces will be the future.
And it's not just about B2C. Turns out, B2B users are people too. :)
tldr: everyone is converging on the same product shape: a general harness that takes a goal, uses tools, and does knowledge work.
once every product is a harness, the next frontier is the feedback loop that improves it after deployment.
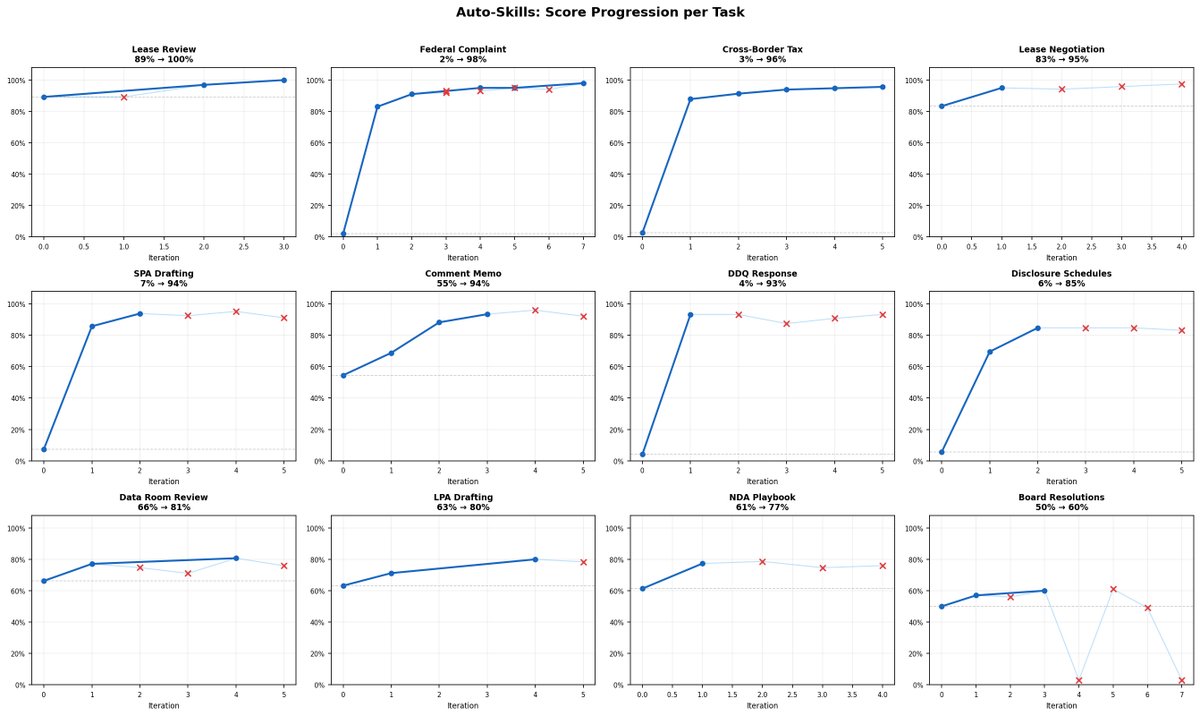
there's a really interesting finding hiding in this picture, right? most of these tasks didn't get better over time. they got better on the first try
meaning: performance was left on the table in the past system. does the team have the strength to avoid the ego hit, and just make progress, knowing most old stuff should be thrown out. interesting findings. nice writeup
@dzhng@morganlinton@denisyarats Curious why you say it should be split from MCP, if you would just end up recreating that part of MCP Apps. I could see political arguments for this if you want to own the standard, but I don't see the technical reason for it.
@dzhng@morganlinton@denisyarats How do you think MCP Apps factors into this? Do you think that interactive embedded apps is one good use case for MCP since it is substantially more involved than a typical MCP tool?
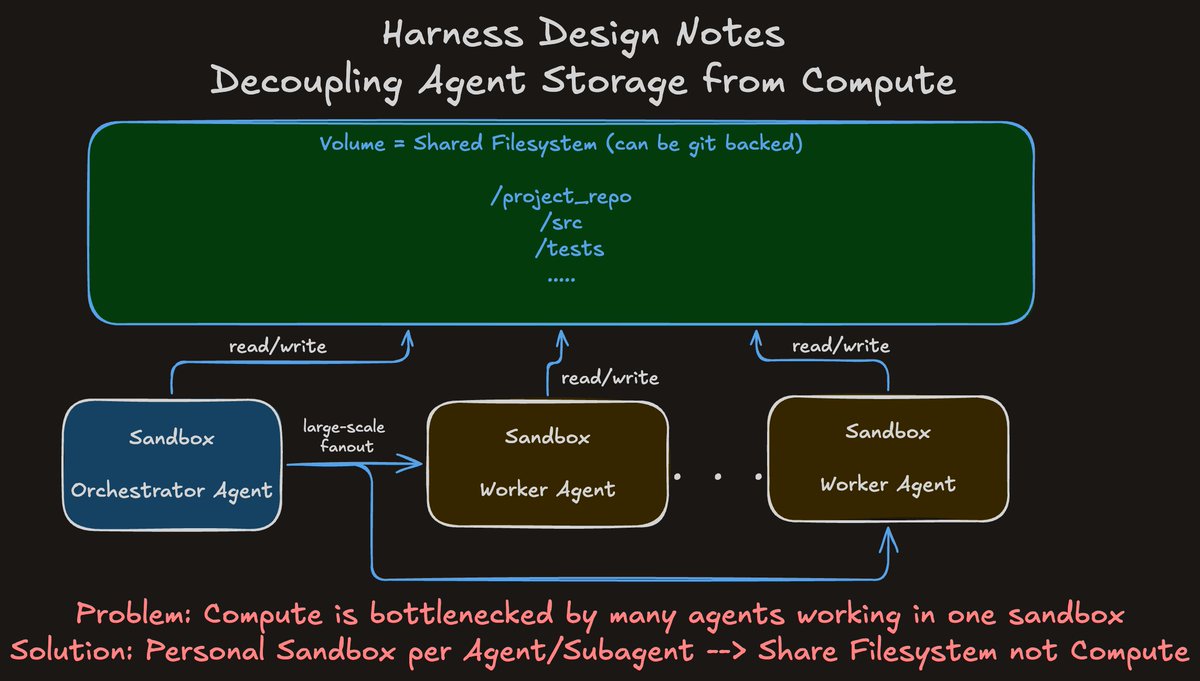
Harness Design Notes: Decoupling Agent Storage from Agent Compute
TLDR: You can give each Agent/Subagent dedicated compute while sharing storage (repo/filesystem) to self-organize work between them. Shared Compute can be a bottleneck especially with long running code execution.
Started writing up some harness design patterns over a very long flight this weekend, might make this a series if there's interest!
We're on the edge of using a massive amount of compute to orchestrate agents across long horizon work
Ex: for Agent Teams, an orchestrator organizes potentially many agents that fan out and do work on a project (like a large repo)
For anyone who runs many agents locally, you see your CPU usage skyrocket for even moderate runs with code exec
But Sandboxes to the rescue :)
There's a nice pattern of shared filesystems via Volumes that all agents access while getting their own sandbox environment. The coordination happens via writing to the write place in the filesystem. And using git makes it so you can track and roll back changes over time
good Harness Engineering on self-organizing agents via filesystems requires thinking about infra too. Many patterns work but you have to measure them for your work!
Harness Engineering is Systems Engineering
🆕 How to Kill The Code Review
https://t.co/fzUMQxwVOS
the volume and size of PRs is skyrocketing. @simonw called out StrongDM’s “Dark Factory” last month: no human code, but *also* no human review (!?)
in this week’s guest post, @ankitxg makes a 5 step layered playbook for how this can come true.
An interesting aspect of these models and foundation model companies:
- Their internal teams know *a ton* about how to best use these models
- They are publishing things (e.g. skills) that let you essentially leverage that knowledge for free
- You should never really 'hand craft' a context at this point. It's much better for you to 'find the existing' bootstrapped context (or context generator) and use that instead, or have the model 'prompt it' out of you (e.g. AskUserQuestion tool all day)
- The skill-creator skill is a perfect example of this. It's essentially leading-edge knowledge of people *at foundation labs knowing what works* just available to you, for free
- It's kind of weird, but there's actually just incredible 'alpha' by finding existing skills that work versus trying to do your own thing.
- With the right set of skills loaded, I would make a bet that a large proportion (maybe a majority) of white-collar work could be accomplished by purely typing the key '/' followed by a word into a terminal, over and over again
- It still helps to have good taste, know what good looks like, take incremental approaches, and just generally be curious -- but the shape of what it even means 'to work' has totally shifted - and it's going to continue to shift even faster than it is now.
It's certainly weird, but we are here.
Prompt caching can be surprisingly easy to regress.
Read more on why prompt caching is so important for agents and how to design your agent around it here:
https://t.co/Gnd7v2XGTr
New chapter of my Agentic Engineering Patterns guide. This one is about having coding agents build custom interactive and animated explanations to help fight back against cognitive debt https://t.co/F5mqcUSp3f
This turtle behavior, often called "claw fluttering", is a courtship ritual where a male turtle rapidly vibrates or waves his long front claws (or "jazz hands") near a female's face to attract her.
Holy shit… this paper might be the most important shift in how we use LLMs this entire year.
“Large Causal Models from Large Language Models.”
It shows you can grow full causal models directly out of an LLM not approximations, not vibes actual causal graphs, counterfactuals, interventions, and constraint-checked structures.
And the way they do it is wild:
Instead of training a specialized causal model, they interrogate the LLM like a scientist:
→ extract a candidate causal graph from text
→ ask the model to check conditional independencies
→ detect contradictions
→ revise the structure
→ test counterfactuals and interventional predictions
→ iterate until the causal model stabilizes
The result is something we’ve never had before:
a causal system built inside the LLM using its own latent world knowledge.
Across benchmarks synthetic, real-world, messy domains these LCMs beat classical causal discovery methods because they pull from the LLM’s massive prior knowledge instead of just local correlations.
And the counterfactual reasoning?
Shockingly strong.
The model can answer “what if” questions that standard algorithms completely fail on, simply because it already “knows” things about the world those algorithms can’t infer from data alone.
This paper hints at a future where LLMs aren’t just pattern machines.
They become causal engines systems that form, test, and refine structural explanations of reality.
If this scales, every field that relies on causal inference economics, medicine, policy, science is about to get rewritten.
LLMs won’t just tell you what happens.
They’ll tell you why.