We just dropped Gemma 4 Quantization-Aware Training (QAT) checkpoints on Hugging Face!
All Gemma 4 model sizes and their drafters are now optimized with QAT to cut memory requirements and maximize on-device performance!
I just spent months handwriting a 200 page guide on the entirety of ML foundations and math from scratch.
The guide features:
- Neural Nets (Backprop, Adam, SGD, Batch Norm)
- ML Algorithms (SVM, Grad Boosting, K-means, PCA)
- Hardware (Tensor Cores, Systolic Arrays, CUDA)
- Transformers (Multi-Head Attn, KV Cache, LoRA)
- Vision (ViT, Convolutions, MAE, IoU, NMS, VLM)
- Agents (OpenClaw, ReAct, Memory, Orchestration)
Everything I wish I had years ago, for free.
I have so much fun writing this position with some of the most amaaazing people in robotics!
Have a look at it here: https://t.co/zM3NBtobkx
#AI#MachineLearning#Robotics
Today we're shipping Nemotron 3 Ultra.
A 550B MoE frontier-intelligence open model built for long-running agents.
It delivers 5x faster inference and lowers the cost of complex agentic tasks by up to 30% versus other open frontier models.
Nemotron 3 Ultra performed GPT 5.5 level 10× cheaper
We gave three same prompts to build HTML5 canvas with real physics. At first scene we have water in a spinning drum. Galton board - balls through pegs into bins. And a block collision setup with extreme mass differences.
Outputs:
Nemotron 3 Ultra: 11.3k tokens, $0.051
GPT 5.5: 11.0k tokens, $0.57
Nemotron stays right on GPT 5.5's heels, but at 10× cheaper. The gap in quality is far smaller than the gap in price.
"MAI-Thinking-1: Building a Hill-Climbing Machine"
Microsoft just did something almost no frontier AI lab has done before
They shared how they engineered the data behind a frontier-scale model in unusual depth.
From data collection and eval decontamination, to data mix scaling, this paper lays out how they managed 30T pretraining tokens plus 3.55T midtraining tokens
Surprisingly, they also used no third-party distillation and no open-source training datasets
The model itself is not a jaw-dropping release, but the paper might be the best open look yet at a frontier-scale data factory and hill-climbing loop.
Today, we’re launching Reve 2.0, the best 4K image model in the world.
We invented a new way to generate and edit any image using precise layouts. For the first time, it’s possible to create images you can touch.
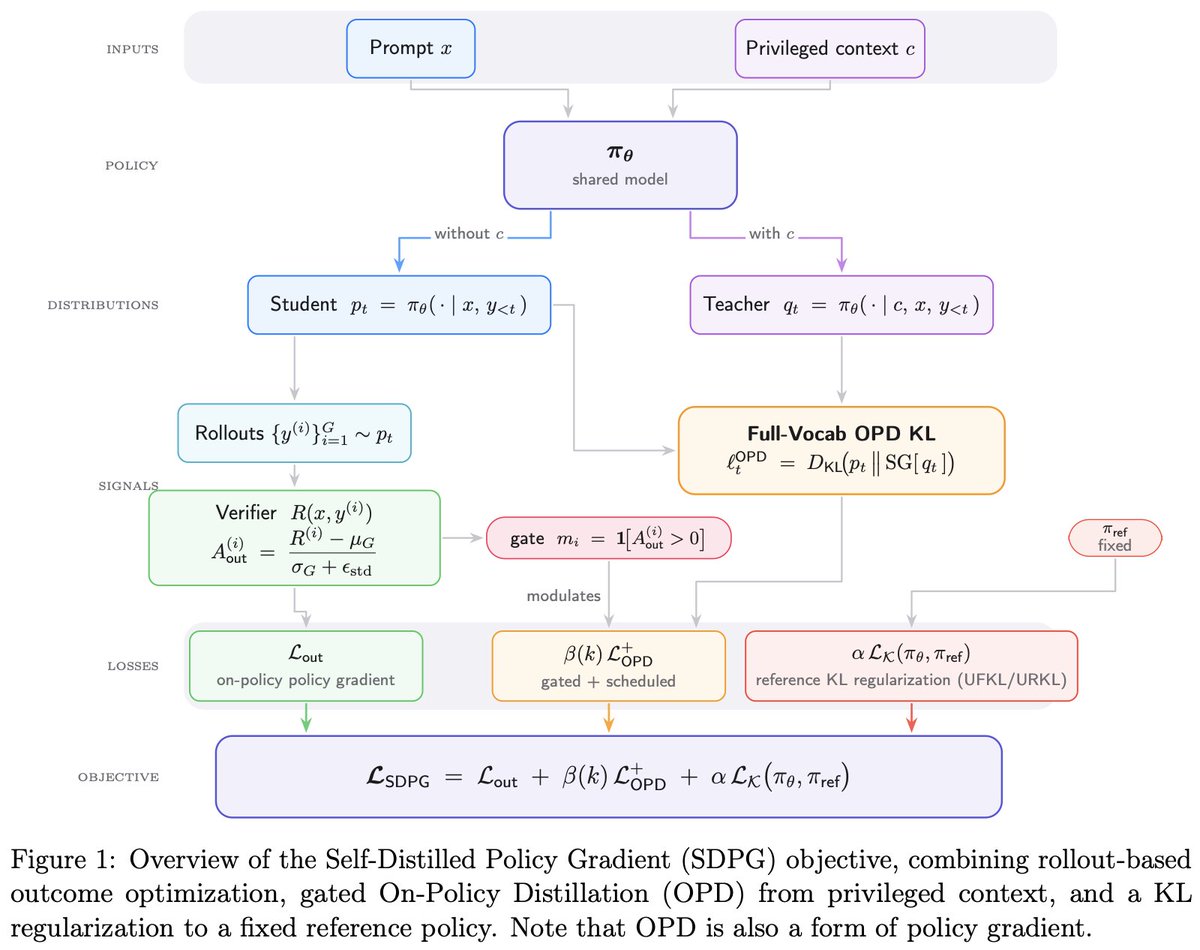
Introducing Self-Distilled Policy Gradient.
Token-level rewards, credit assignment, self-distillation.
RL and distillation are converging toward the same idea:
Policy gradients, it always has been, it always will be.
https://t.co/RJeRFUTeyz
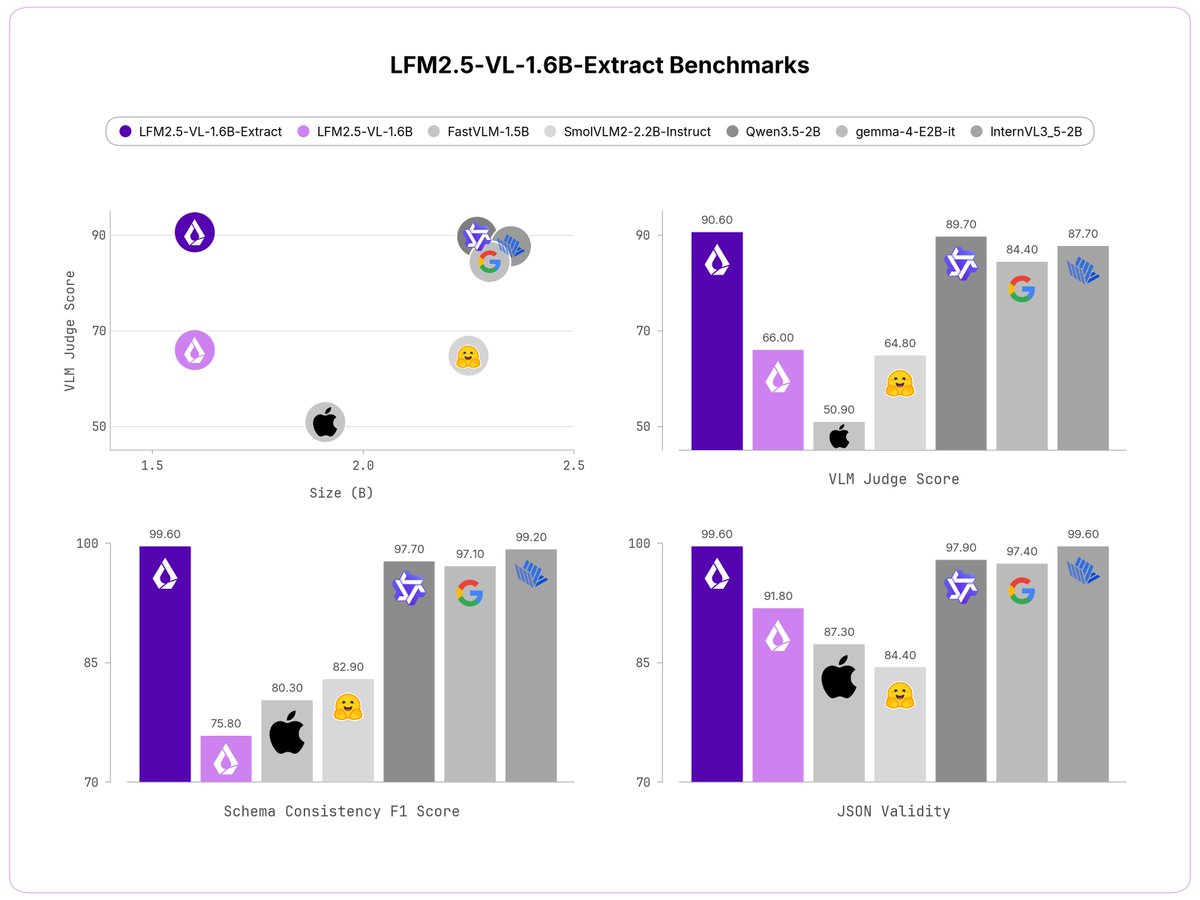
Introducing LFM2.5-VL-1.6B-Extract and LFM2.5-VL-450M-Extract: Vision-language models that return structured JSON, not free-form text.
Pass in an image and a list of fields. Get back a clean JSON object.
> Two sizes: 1.6B parameters and 450M
> open-weight
> run on any device SoC
🧵
Introducing Magenta RealTime 2, a new open model musicians can play as an instrument!
Run low-latency, live music synthesis natively on your MacBook using MIDI, text, and audio. 🎶
We love seeing Google’s open model ecosystem grow!
Outstanding paper on long-horizon agents.
(bookmark it)
Similar to humans, how do you make agents persist on a difficult task, and how is that useful?
And which models today work well on this?
This new work, AutoLab, explores this question and how encoding persistence in agents is beneficial for tasks such as auto research and engineering tasks.
Can a model keep improving an artifact for hours, under a strict wall-clock budget, the way real research and engineering actually work?
Results:
AutoLab hands agents 36 expert-curated tasks across system optimization, model development, CUDA kernels, and puzzles, each starting from a correct but deliberately suboptimal baseline.
Across 17 frontier models, the dominant predictor of success was not the quality of the first attempt. It was persistence, repeatedly benchmarking, editing, and folding in empirical feedback.
It appears that Claude-opus-4.6 sustained that loop well. Most of the other models quit early or burned the budget, making almost no progress.
Paper: https://t.co/jb8uYR0fpE
Learn to build effective AI agents in our academy: https://t.co/LRnpZN7L4c
We’re going all in on World Models.
Today we’re launching the 1X World Model Lab.
The bet is simple:
You can’t fine-tune your way to AGI.
And you definitely can’t fine-tune your way to robots that can operate in the physical world.
General-purpose humanoids need models that understand space, motion, objects, causality, affordances, physics, and action before they ever see a specific task.
The frontier is not better VLA wrappers.
The frontier is embodied world models.
The 1X World Model Lab will focus on large-scale embodied world model pretraining: building the most generalizable foundation model for humanoid robots from the ground up.
The next frontier in AI requires scaling:
web-scale media + egocentric human videos + sim + dexterous remote operated robot data + on-policy NEO data → real-world deployment for robot data collection and RL → abundance of data → physical AI
The robot collects data.
The model gets better.
The robot gets better.
Repeat.
To lead this, we brought in one of the best for the mission: @_sam_sinha_ , as Head of World Models.
Sam was a founding research scientist at Luma AI and has been at the frontier of scaling multimodal generative video models his whole career.
If you’re the best in the world at large-scale pretraining, video models, robotics, RL, infra, or data — and you want your models to move atoms, not just pixels — join us.
Send background + evidence of exceptional ability to:
[email protected]
We’re building the model that makes autonomous labor real.
Introducing Ideogram 4.0: the best open image model in the world.
Think it. Make it. Own it.
Download the weights, fine-tune on your own data, and run it on your hardware. Live on every Ideogram plan and the API today.
Seven new models launching at Build: let’s go!
Reasoning. Code. Image. Transcribe. Voice.
Built from scratch on a clean data lineage, designed for efficiency, working seamlessly as a family of models
Thread 🧵
#MSBuild
New research from Google.
Just shows the impressive results you can get from custom agent harnesses.
LEAP wraps a general-purpose LLM in an agentic scaffold that grounds every step in the Lean compiler and iterates against verifier feedback.
The same general model solves all 12 Putnam 2025 problems and lifts Lean-IMO-Bench one-shot solve rate from under 10% to 70%, beating a specialized gold-medal system that scores 48%.
Paper: https://t.co/bh4Yoi19E2
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Building apps has never been easier.
With Sites, Codex can turn your work, ideas, and plans into an interactive website or app your team can explore, use, and share with a URL.
Rolling out to Business and Enterprise plans, before expanding more broadly.
Training an LLM from scratch is easier to study when the whole path is in one repo.
Train LLM From Scratch is a PyTorch repository for learning how a transformer language model is built, trained, saved, and used for text generation.
It helps you move from “I understand attention on paper” to a runnable training pipeline by pairing model code with data download, preprocessing, config, training, and generation scripts.
Key features:
• Transformer components from scratch – separate PyTorch modules for MLP, attention, transformer blocks, and the final model
• Pile-based data path – scripts download The Pile files and preprocess JSONL.ZST text into tokenized HDF5 datasets
• Configurable training setup – model size, context length, heads, blocks, batch size, learning rate, and file paths live in https://t.co/zuPqaR3MhP
• Hardware guidance – README compares common GPUs for 13M and 2B-class training runs
• Generation workflow included – generate_text.py loads trained checkpoints and produces sample text outputs
It’s open-source (MIT license).
Link in the reply 👇
1/ We give LLMs extra compute to "think" before they answer. But text-to-image models are still stuck in a dumb, feedforward, one-pass loop.
What if we let pixels ponder?
It fixes spatial layout and attribute binding without scaling backbone parameters.
More of my beloved topic of universal transformers!🧵