You have a right to be foolish, I wouldn’t judge you for that. I have been foolish long enough to learn not to condemn the fool. But you have no right to be evil, and to support a continuation of Nigeria in its current form, is to be complicit in the evil that it is..
Could it be that sex, as ordained by the Almighty, points toward a union infinitely more profound and presently beyond humanity’s full grasp?
Few realities evoke such power, pleasure, beauty, longing, vulnerability, and destructiveness as sex....
https://t.co/M3dN0HEyra
Give Us Four Years, We’ll Raise Nigeria’s Power Supply To 10,000MW - Obi
This is something we have carefully studied, and we are not going to come into government and start making excuses about why it cannot be done. It is completely unacceptable that a country of over 200 million people generates and distributes only about 4,000 megawatts of electricity while millions of Nigerians still lack access to reliable power. Countries like South Africa and Egypt, despite having significantly smaller populations, each generate and distribute over 40,000 megawatts. Nigeria is not even producing one-tenth of what those countries generate, and that must change. We will also tackle unemployment through honest and transparent policies by supporting micro, small, and medium-sized businesses with tax incentives, financial support, and access to affordable credit so they can grow, create jobs, and drive economic development.
Peter Obi, NDC 2027 Presidential Candidate
A coach who never stopped teaching. It sounds crazy to say this, but you made greatness feel normal. Even after hat-tricks, wins and trophies, there was always another lesson, another challenge and another level to reach. That mentality changed this club forever and changed me too. The honour of a lifetime to work with the best. Thank you for everything, boss 🙏🏻 🩵
Users see a chat interface.
Behind that interface, a small fleet of agents queries data, optimizes channel allocations, and renders plots.
For the marketing team using it, planning cycles that used to take weeks now finish in days.
https://t.co/hW8gsYBGHj
Pep Guardiola on @BernardoCSilva: "If I talk a lot, I will cry.
"Just I can say, 'Thank you so much, from the deepest of my heart, on behalf of this club, what you have done'. Bernardo has proved that football starts from here [the brain], to the feet. And that guy is not the fastest, quickest, but knows exactly in every single moment what every single action requires. Never injured, always committed.
"Last season defined Bernardo for me; when everybody was not there, always he was there, suffering the first. His mentality. And he has one thing that is important; always he sees the positive things in the life. That's why his life will be so happy with his wife Ines and the kids, he will be so happy because always he's positive...
"He deserves the BIGGEST recognition. When you write 'LEGEND', you have to write in capital letters, because he has been. For every single game during nine years!
"He's a special, special player. All I can say is where he will go, the team will be SOOOO lucky to have him!" 🩵
🗣️ "Who is top of the league? Arsenal. That is only reality."
Pep Guardiola's thoughts after Man City's 2-1 victory over the Gunners.
🎤 @AndyKerrtv#beINPL#MCIARS#MCFC
We can't have it both ways.
The 1st Commandment opens with a reminder and an invitation: https://t.co/a7PgeZtmTp
Discover more ↓ https://t.co/RTyafqToqN
Local LLMs are now running SMB workflows off your own hardware. Keep your data private while AI handles the busy work.
Start optimizing your stack today.
#LocalAI#SMB#LLM
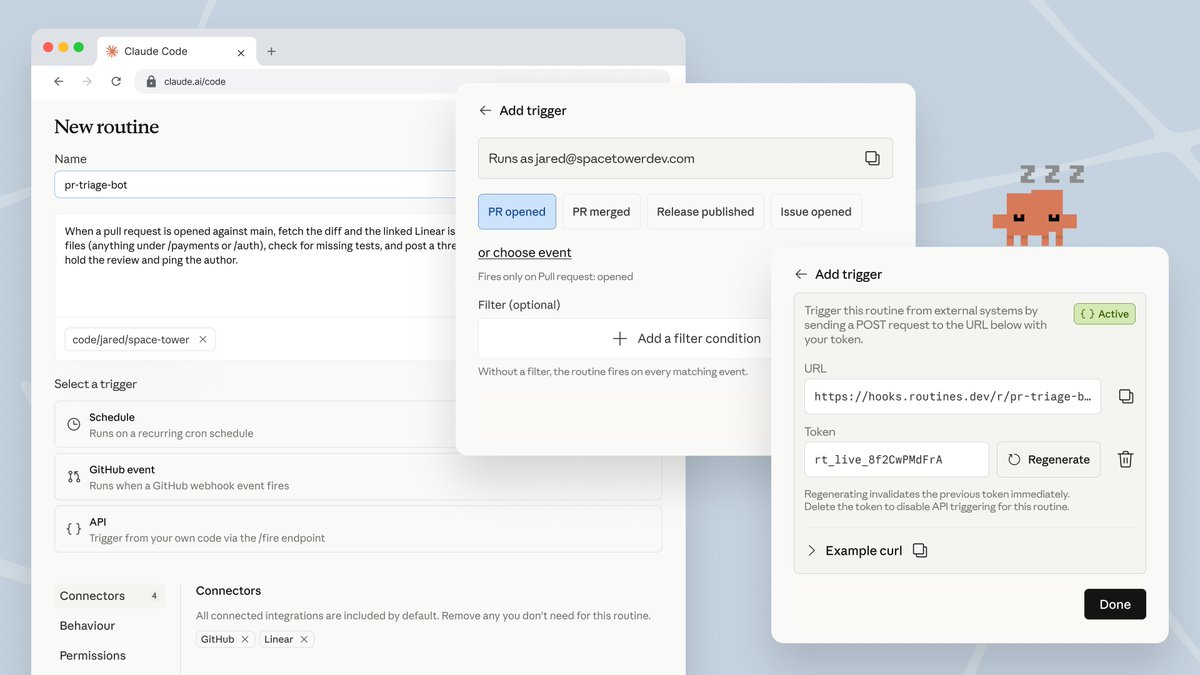
Now in research preview: routines in Claude Code.
Configure a routine once (a prompt, a repo, and your connectors), and it can run on a schedule, from an API call, or in response to an event.
Routines run on our web infrastructure, so you don't have to keep your laptop open.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
























![City_Xtra's tweet photo. Pep Guardiola on @BernardoCSilva: "If I talk a lot, I will cry.
"Just I can say, 'Thank you so much, from the deepest of my heart, on behalf of this club, what you have done'. Bernardo has proved that football starts from here [the brain], to the feet. And that guy is not the fastest, quickest, but knows exactly in every single moment what every single action requires. Never injured, always committed.
"Last season defined Bernardo for me; when everybody was not there, always he was there, suffering the first. His mentality. And he has one thing that is important; always he sees the positive things in the life. That's why his life will be so happy with his wife Ines and the kids, he will be so happy because always he's positive...
"He deserves the BIGGEST recognition. When you write 'LEGEND', you have to write in capital letters, because he has been. For every single game during nine years!
"He's a special, special player. All I can say is where he will go, the team will be SOOOO lucky to have him!" 🩵](https://pbs.twimg.com/media/HGSc662bYAEBv-I.jpg)