Why we won't be replaced by AI
There’s been a lot of talk about AIs replacing programmers recently. The National Post: “AI is coming after the tech bros and their easy money”. Emad Mostaque, CEO of Stability AI: “There Will Be No Programmers in Five Years”. Some people are changing their career decisions as a result. Investors see the potential too: companies have raised hundreds of millions of dollars promising to replace human developers. Given the salaries that skilled developers can earn, there’s a lot of money in finding a way to cut us out of the picture.
But it’s not going to happen. We’re not going to be replaced by the machines.
Now, I’m not going to fall into the trap of past AI detractors by predicting deep learning is going to “hit a wall” and being proven wrong 6 months later. I think we’ll continue to see progress as AI systems get more intelligent and new applications are discovered, and I think AI will create a lot of economic value. (That’s why I’m working on an AI company.) And a lot of arguments for why humans will stay relevant boil down to “AI doesn’t work today, so it won’t work in the future”. That’s not reassuring because the whole reason people are worried about this is the rapid rate of progress. But the predictions that this progress will lead to humans being replaced are incorrect - here’s why.
An AI can only learn a task when we have a way for the AI to perform the task and then be judged on whether it did the task correctly. The two main tasks that are currently used to train AI are:
1. Next-word prediction: the AI is given a document of text from the internet and asked to predict the next word in the document.
2. Short response generation (RLHF): the AI is given a query or prompt (eg. a user asking for coding help) and asked to generate a response (eg. a solution to the user’s problem). The response is scored by humans on its helpfulness and accuracy.
Training AIs on these tasks has led to extremely useful products like ChatGPT, and ChatGPT is great at helping developers in day-to-day work, so it’s reasonable that people think systems like ChatGPT might soon eclipse us.
But software development is not just about writing individual functions and short responses. A key part of software development is making technical decisions, like software architecture or project prioritization, that will pay off over the long-term on the scale of 6 months to 5 years. To train AI to do this, we would need a way for it to make technical decisions and a way to judge those decisions for their long-term soundness. We don’t know how to do that, and we especially don’t know how to do that at the scale required to train a large AI model. By definition these sorts of decisions are hard to judge, with no objective criteria for success, only difficult tradeoffs.
The performance of AI is always going to be limited by the tasks where it can have a feedback signal, and this makes long-term planning difficult for AI because there is no naturally occurring training data (unlike next-word prediction) and there is no way to quickly assess whether a decision was good or bad (unlike short response generation/RLHF). Training a good next-word prediction model requires a loop of hundreds of thousands of training steps, which is possible because next-word prediction is quick to evaluate, but running the same number of training steps on decisions where you have to wait 1 year to see if the decision was good or bad would take hundreds of thousands of years. We humans are good at this because our minds have been shaped by millions of years of evolution, but AI doesn’t have that time.
Some people think we can avoid difficulties like this by having the AI judge its own responses. While this can work to bring a weaker model up to the level of a stronger model, it can’t work to have a strong model improve itself, because if it worked it would imply the ability for a model to continually self-improve in isolation without interacting with the external world. For learning to occur, there has to be a feedback signal coming from external data.
The future of AI is continued progress on tasks where we have a good way to train AI to solve them, and continued lack of progress on the tasks where we don’t. Instead of worrying about AI replacing software developers, the right move is to integrate AI tools into your workflow and use AI for what it’s good at while reserving high-level, long-term decisions to be decided by humans, not AI.
C2.5 is the same pretrain as C2, but powered by a much better and stronger midtrain (nearly an OOM more FLOPS)!
The base model matters a ton for RL, so we're very excited for the power of Colossus 2 to push this way further
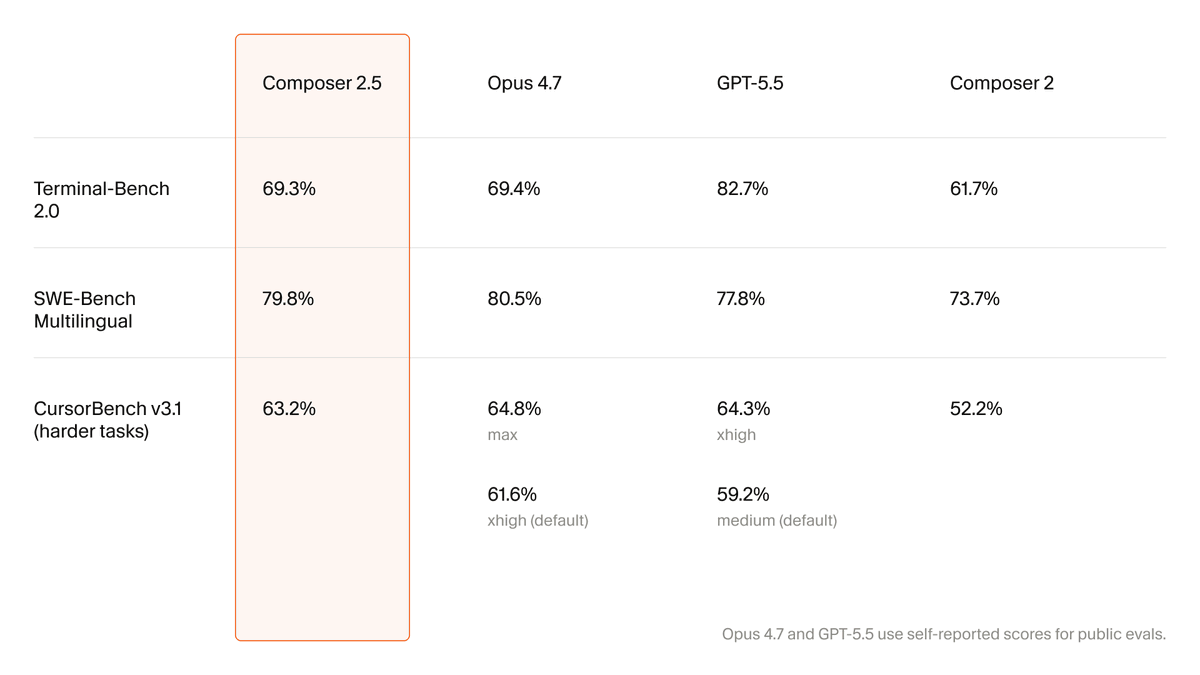
Introducing Composer 2.5, our most powerful model yet.
It's more intelligent, better at sustained work on long-running tasks, and more reliable at following complex instructions.
For the next week, we’re doubling the included usage of the model.
We’re introducing Cursor 3. It is simpler, more powerful, and built for a world where all code is written by agents, while keeping the depth of a development environment.
@vivekkalyansk On-policy = model that generated the response receiving feedback is the same as the model being trained with RL
Implicit feedback = user feedback, but not something like thumbs up/thumbs down, which would be explicit
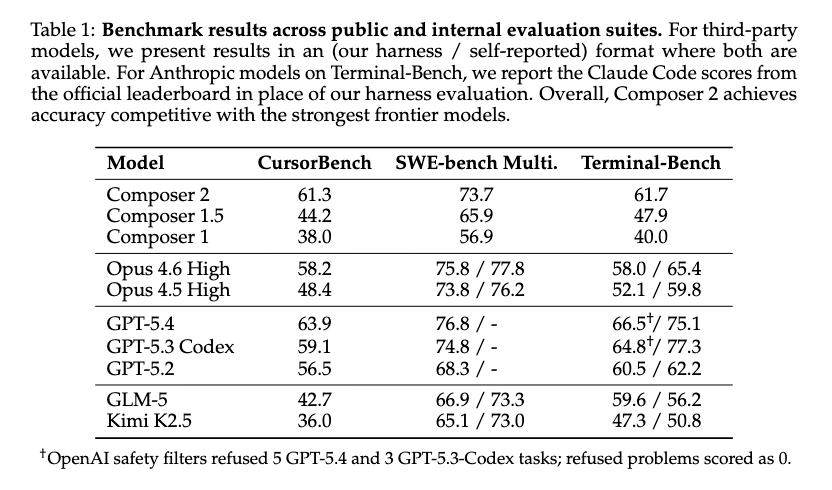
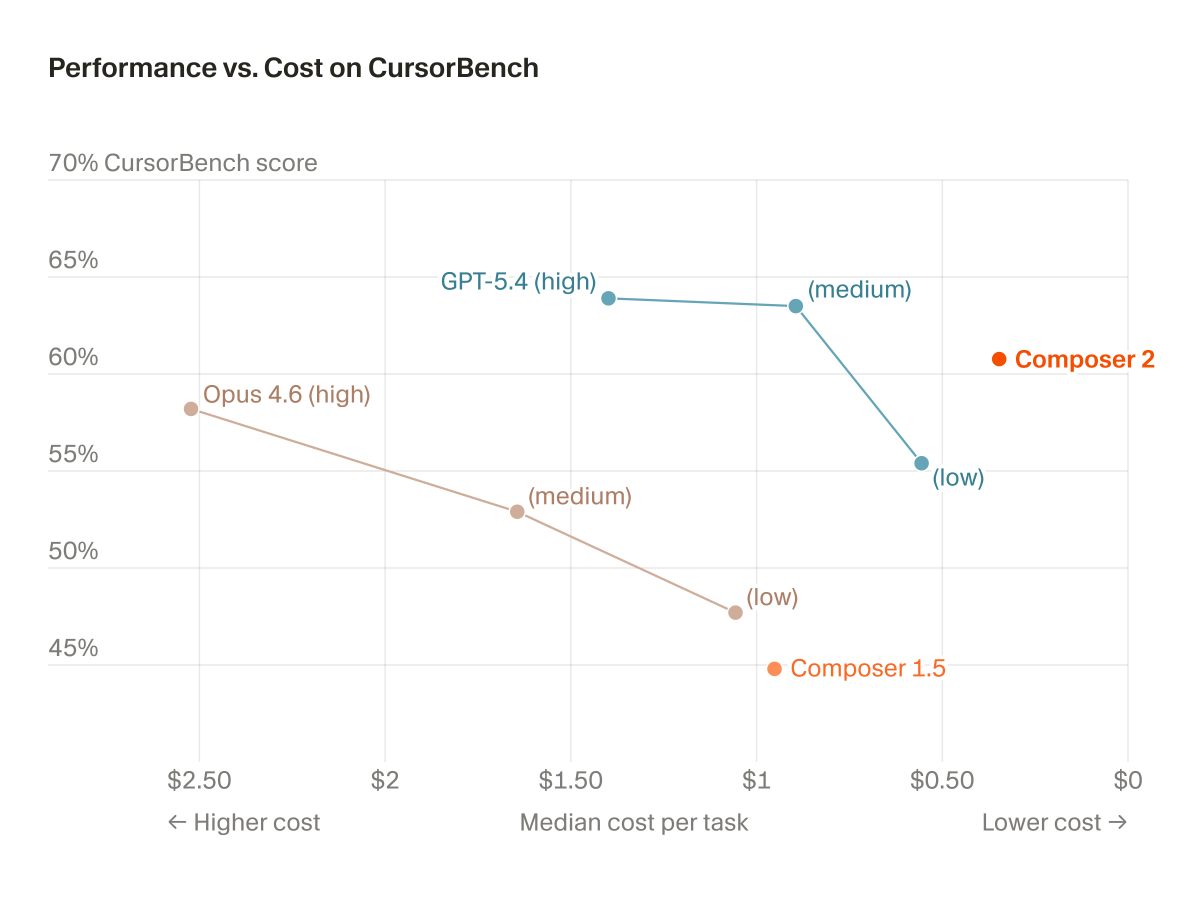
Earlier this week, we published our technical report on Composer 2.
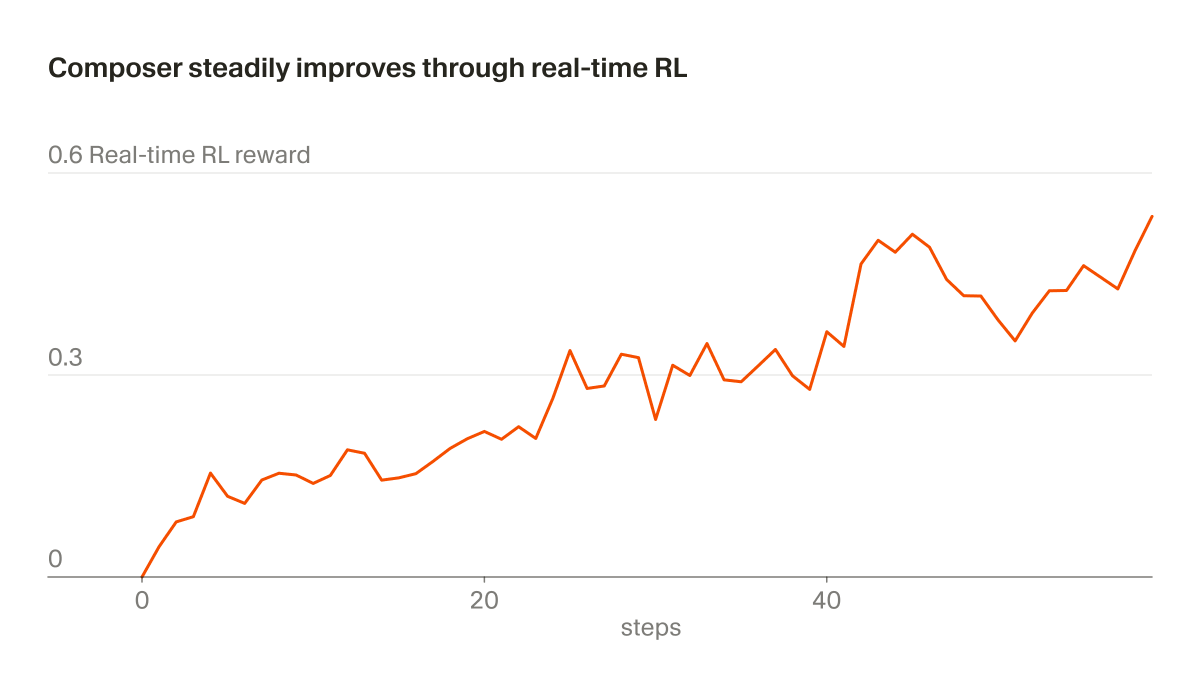
We're sharing additional research on how we train new checkpoints. With real-time RL, we can ship improved versions of the model every five hours.
New post: how we do evals at @cursor_ai. Takeaways:
1. Online metrics from real Cursor requests provide construct validity
2. CursorBench: a dynamic offline suite distilled from online learnings
3. Multi-axes evals -- correctness, efficiency, agent interaction behavior
Semantic search improves our agent's accuracy across all frontier models, especially in large codebases where grep alone falls short.
Learn more about our results and how we trained an embedding model for retrieving code.
I joined @cursor_ai a few months ago to help build a fast model for agentic coding. Very excited the first version has shipped and can't wait to hear what you all think!
https://t.co/RaFv9cMB4g
Excited to release our first model. We've been working on it for a while, and it came out of the oven pretty well! I've been enjoying daily driving it and I think you might too.
Some exciting new to share - I joined Cursor! We just shipped a model 🐆 It's really good - try it out!
https://t.co/EX2QDRFrDB
I left OpenAI after 3 years there and moved to Cursor a few weeks ago. After working on RL for my whole career, it was incredible to see RL come alive and be deployed in a product that millions of people use everyday in ChatGPT, and then honestly kind of surreal to see it surpass me at the types of tasks I regarded as markers of intelligence in o1/o3. To me, the next frontier is to bring the whole world of economically useful tasks in-distribution for RL
At Cursor, we’re building a team focused on RL foundations and agentic coding - reach out if you’re interested in working with us!