Introducing Handshake AI—the most ambitious chapter in our story. We leverage the scale of the largest early career network to source, train, and manage domain experts who test and challenge frontier models to failure for the top AI labs.
We built a better way to grade agentic work.
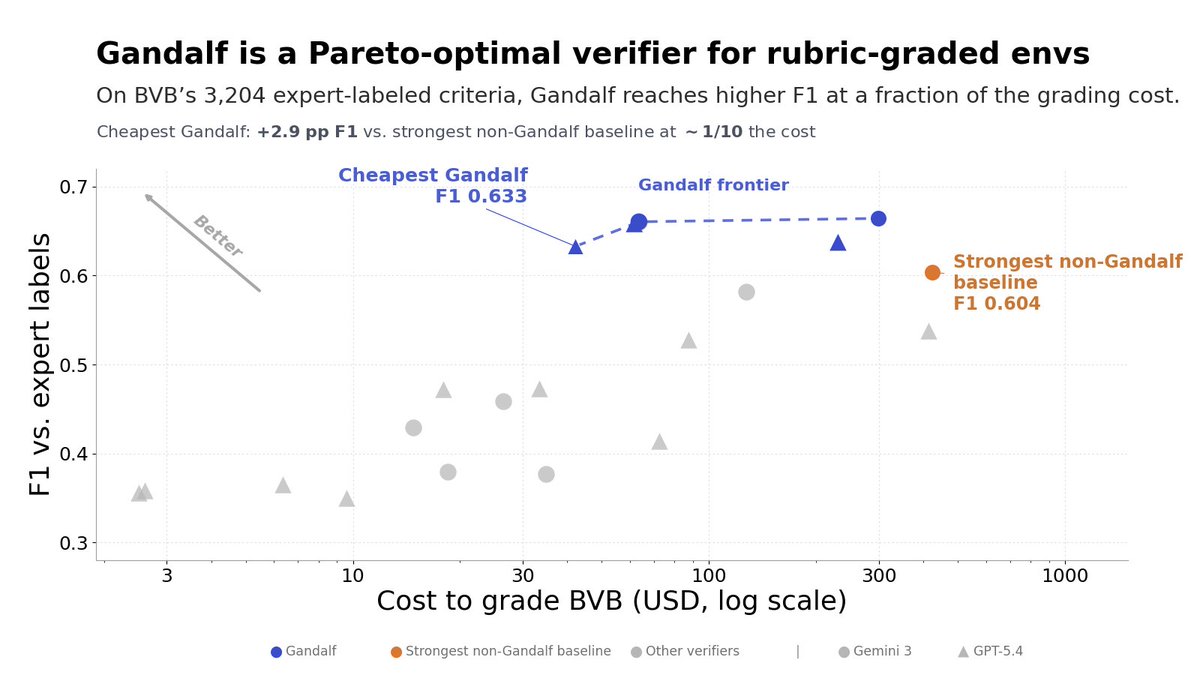
Gandalf is a reactive agent-as-judge that inspects files, tool state, and artifacts the same way a human expert would. On our banking benchmark, even the cheapest Gandalf config beat the next-best verifier at ~10x lower cost.
Verifier architecture matters more than the model behind it.
👇 More from @AnishAthalye
Grading agent rollouts in rubric-graded RL environments is itself a hard task.
Prior approaches pass serialized artifacts or agent trajectories to an LLM judge; this loses information / doesn't support sophisticated criteria.
In contrast, we built a reactive agentic judge.
Agent evals are becoming foundational infrastructure.
@jomulr joined @CAISconf’s RLEval workshop to share Handshake’s perspective on RL environments, evaluation, and why @harborframework is emerging as the framework.
Packed room to hear @alexgshaw and @ryanmart3n break down how @harborframework grew into *the* framework for RL environments.
In our RLEval workshop at @CAISconf today, attendees tackled big open challenges in RLEs & Agent Evals + I shared the approach we take at @joinHandshake
Kudos to @anishathalye and @jomulr for co-chairing the RL agentic benchmarks workshop track for the inaugural ACM CAIS conference this week.
We presented two separate Handshake AI Research papers in: (1) AI agentic systems - first evaluation of grader frameworks, and (2) AI benchmarks - first investment banking benchmark. Their posters had big crowds all afternoon. Great job!
This spring, we worked with @OpenAI to launch the Codex Creator Challenge. More than 1,500 students built something on their own terms, driven by their own ideas. That kind of confidence and creative ownership is exactly what the most forward-thinking employers are hiring for.
Explore what they built: https://t.co/qothruRxyu
Demo gods were on my side for this guest lecture on AI Agent Security at @MIT_CSAIL: I was able to show a prompt injection attack against @AnthropicAI's Opus 4.6 model. Agent security is still an unsolved problem!
The Handshake x @OpenAI Codex Creator Challenge winners are in 👇
🥇See why your code fails, line by line, with TraceCode by Obinna Nwachukwu
🥈Interactively explore America's power grid with InfraMap by Leonard Alsleben
🥉 Explore global dragon mythology with Where Dragons Dwell by Huiying Chung
The AI Showcase is May 20. https://t.co/2Kp0lHiuDz
@TanagerDon Hi Don, thanks for contacting Handshake Support. Please open the chatbot at the bottom right of https://t.co/S4RwiP3Oqt and ask it to create a new support ticket. From there, we can review your account status. We look forward to hearing from you.
@aaqib_15 Hi Aqib,
Thanks for reaching out to the Fellow Experience team with Handshake AI! My name is Regina, and I'd be happy to help you!
To better assist you and make sure we get you the right support, could you please provide more information?
The following may be helpful to bet...
This @joinHandshake event with @OpenAI was so energizing.
Not surprisingly, when you give young people powerful tools, their creativity and ambition run wild. The @UCBerkeley students were incredible.
With AI, your career will be more about showing than telling. Build something real, not just a pretty resume. This is just the start.
85% of seniors use generative AI. Now they're building with it too.
So proud to see @UCBerkeley students turn curiosity into craft at the Codex Creator Challenge with @OpenAIDevs. 🙌
Students are learning to build with Codex, and building to learn.
Here’s what @UCBerkeley students built at the Codex Creator Challenge with @joinHandshake.
AI models are incredible at coding and math. Labs like OpenAI and Anthropic solve verifiable domains by teaching models with tasks that have clear right or wrong answers, like "5/2."
But in domains like finance or law, there is rarely a single right answer. There, labs turn to verifiers, complex systems that use AI, to grade the answers. But these verifiers can make mistakes! Is that an issue?
In our latest research, we show that the verifier can be wrong 15–30% of the time, and the models will learn just as well. This means we can use these imperfect verifiers without losing performance!
Does an imperfect verifier break reinforcement learning with verifiable rewards (RLVR)? Turns out it doesn’t!
Why does this matter? As the world moves into reinforcement learning in semi-verifiable domains, perfect verifiers don’t exist.
We added controlled and LLM-based noise to RLVR reward signals and found that up to 30% noise barely hurts training; performance stays within 4pp of the clean baseline.
This research has already impacted how we build reinforcement learning environments at @joinHandshake. For a major benchmark we are launching tomorrow, we hill-climbed the verifier to 88% accuracy—above the 85% human inter-rater agreement—knowing from this research that this is good enough.
With @andreas_plesner@guzmanhe
📣 Second speaker announcement for Acquired Unplugged:
Garrett Lord, co-founder and CEO of Handshake, will join Ben Gilbert and David Rosenthal for a live conversation on building Handshake into the career network for the AI economy.
Space is limited. Register here: https://t.co/IozL3YESTp
I asked @GarrettLord how @joinHandshake came out of nowhere to become a top data labeling partner to the AI labs:
"We started to see incredible demand for individuals with PhDs and Master's on the Handshake platform. People studying to be lawyers, doctors, consultants, and getting their Master's in Tax Accounting. All the data labeling companies were trying to recruit them.
We saw this, and were also hearing from those same people that it was a frustrating experience. They weren't getting paid on time. They weren't getting trained properly. And they weren't being treated as experts in their domain.
We realized we had an opportunity to go direct. And we could then pass along the customer acquisition costs as savings to the AI labs, leapfrogging others in the space.
Human AI data labeling is a very operationally intensive business. The only durable advantage in this space is access to an audience. Otherwise, it's a commoditized set of companies competing with each other for margin.
If you can build loyalty, improve retention, and treat these people the way they expect to be treated, you can pass along many benefits to the labs.
The three things they care a bout is data quality, speed, and volume. And you can do this by building a much better product experience."
From our conversation published in July, 2025. Full episode linked in the replies.