I love to learn new things and use them to solve problems. Currently at @hume_ai Previously built WhisperSpeech an Open Source AI TTS model at @Collabora
We take for granted that larger models are better than smaller ones, but why is this so? Our new paper, led by Jing Huang and @EkdeepL, traces this to a data-induced competition for resources (neurons), using formal analysis, idealized tasks, and real pretraining.
Check out this absolute master piece by Jonathan Gratus titled '' A Pictorial Introduction to Differential Geometry, Leading to Maxwell Equations in 3 Pictures'' which is available on arXiv.
To quote the author: ''When I was young, somewhere around 12, I was given a book on relativity, gravitation and cosmology. Being dyslexic I found reading the text torturous. However I really enjoyed the pictures.''
It's a short primer, full of nice figures, perfect for those who love visual examples.
AI needs vastly more data than we do. One idea might close the gap: don't predict raw signals (tokens), predict your own abstract latent representation (JEPA, data2vec).
With @DanKorchinski@MatthieuWyart, on a toy model, we prove how much that helps: the gap is exponential.
🧵
It has been more than 6 months (on and off) that I am trying to get upto speed with GPU/TPU kernel development.
IMHO, profiling should be the starting point of learning this topic. You profile, you question, you look for answers and in the process read and imbibe.
I set out on a journey to do just the same. I began profiling gemma4 and was quickly humbled by the amount of information that was at my disposal. The profiler table with huge GEMM names, the profiler trace with too many CPU rows.
To make my life easier, I stepped back and profiled a basic matrix multiplication and addition operation, the weights and bias interaction, as one might see it. The profiler artifacts were simple enough to reason and think through.
In this blog post, I document my journey and in the process uncover how one should profile and what one should look at! I hope this helps beginners (like me) with a starting point of their kernel development and optimization journey.
PS: This is a big blog post, bookmark it and come back to this when you have the time (good weekend read?)
@halvarflake@__paleologo I learned a ton from every book recommendation from @apenwarr . He also made a very useful observation about sticking to reading about ideas from original sources: https://t.co/LCb8VloBvT
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.
@p_mbanugo@davidcrawshaw@hashbreaker I don’t know of a good overview but there is documentation here: https://t.co/LPeLsSEcb9
Example: https://t.co/YA3eqKSJRZ
A fun experiment comparing a random step with one gradient step:
With a small CNN on CIFAR-10, a random step is basically a disaster. (A gradient step is a ~185σ event.)
That makes sense if you expect a random direction in R^d to be ~sqrt(d) standard deviations worse than the optimal one. So scaling up to a larger model should make things even worse.
But with a 7B model (test on GSM8k), random steps have a good chance of outperforming a gradient step.
(The gradient norm of one PPO update is 1.94, while the L2 norm of the Gaussian perturbation is 85.6. The figure below rescales the Gaussian perturbation to match the PPO update norm, so the random step and gradient step have the same radius.)
We should really rethink the parameter-function map.
For those who like gory details, the slowness of ethernet is not the physical link layer, you can find reports on specialized systems (specialized NIC, kernel-bypass, no switch, etc) sending a one-way UDP packet in 1.1μs.
But ethernet has: kernel syscalls, socket buffers, SKB allocs, routing lookups, driver queues, often a copy, then NIC packet batching, switch store-and-forward paths, then all the same kernel overhead on the other side.
That gets you half way. Then you do it all again for the response!
NVMe has no packet loss. No scheduling. Just a memory-mapped ring buffer queue consumer on the far end. It is a fundamentally simpler system. It does less and goes faster.
Whereas talking to a multi-zone S3 system means routing packets to another computer, with its own kernel and complexities, in a different building through more than one switch. You need all of that complexity built into ethernet systems to make it work.
If you want something in the middle, RDMA systems can do more than NVMe and pay less overhead than traditional TCP over Ethernet. But you are probably not doing RDMA between buildings.
Bytes are faster if they can be stored locally.
@eliguerron@steveruizok Maybe try making it so dragging controls position directly (like the hold and drag space to move cursor; maybe be nonlinear if you move faster?) instead of velocity. Velocity is super sensitive to latency and human reaction time…
"Nobody reviews compiler output, why review AI code?"
Wrong. We do review compiler output. Godbolt exists. Disassemblers exist. Anyone doing serious performance work reads what the compiler produced. The premise is false.
But the analogy itself is flawed. It compares two things that aren't comparable.
A compiler takes a formal language as input. Languages with grammars and semantics defined precisely enough that "what does this code mean" has only one answer.
An LLM takes natural language as input. Natural languages are ambiguous. "Write me a function that handles user input safely" has a thousand valid interpretations and a thousand more invalid ones. The LLM picks one. You don't know which. Unless you look at the code.
Compilers are built from specifications and designed to meet them. The output is the result of a defined translation. When the output violates the spec, it's a bug.
LLMs are built from whatever was in their training data. There is no spec. There can't be one, natural languages have no defined semantics that map to code.
Compilers are semantically deterministic. The same input produces output with the same behaviour, every time. LLMs are not. Partly by design and partly due to hardware variance, batch size, inference order, and floating point operations (and no setting temperature to zero does not address those). All of which can push the same prompt to produce different code.
Compilers complain loudly when the input is nonsensical. LLMs fail silently, producing plausible-looking, but wrong code.
We trust compiler output because the trust was earned across decades of use, with millions of engineers using the same tools. Early compilers were reviewed heavily. Hand-written assembly was the default because trust hadn't been earned yet.
We're at the hand-written assembly stage with AI. We may never get to the trust-the-output stage for the reasons explained above.
If you’re a software developer, you should own what goes to production. The compiler analogy is a way of skipping that responsibility.
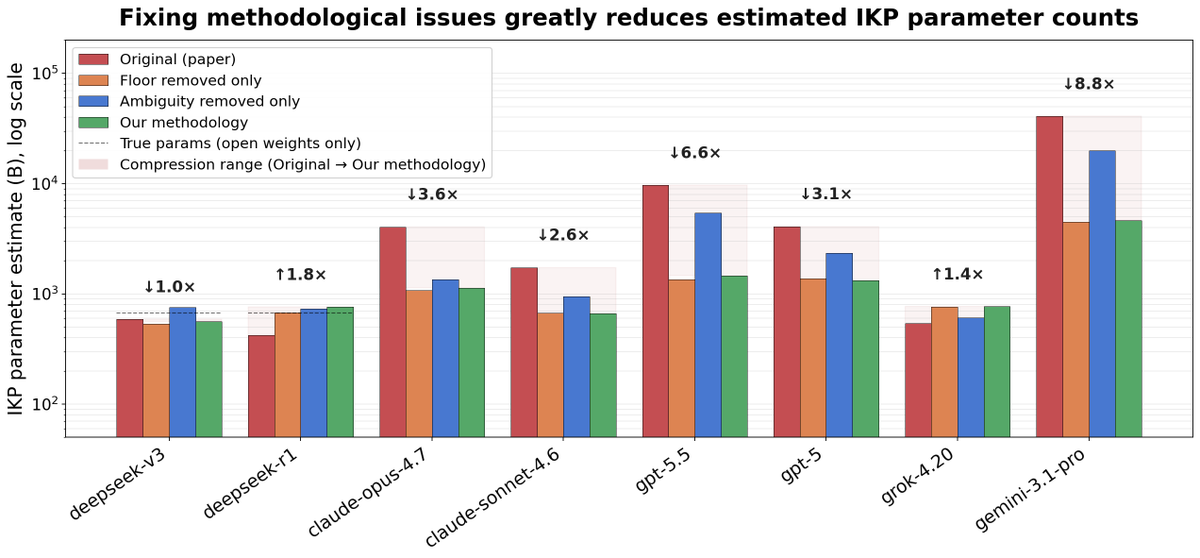
A recent viral paper claims to reverse-engineer the parameter counts of frontier models: GPT-5.5 = 9.7T, Opus 4.7 = 4.0T, o1 = 3.5T, etc.
@ben_sturgeon and I investigated and found serious issues in the paper; fixing them gives GPT-5.5 as ~1.5T (90% CI: 256B-8.3T).
@Jonathan_Blow@etscrivner I nice counter-example was camera APIs on Linux and Android. The simple interface is a pointer to continuous physical memory with some metadata. The bad interface is a set of special opaque API endpoints for passing camera images between each of ISP, CPU, DSP and GPU.
@Jonathan_Blow@etscrivner The reason it worked quite well is because it was a reusable APIs with well understood constrains and invariants. It was not about seek/read/write specifically although Plan9 pushed in this direction. The same design made REST work quite well.
@Jonathan_Blow@etscrivner I think you are comparing excellent API design with poor one-off file formats. Most software design is bad so I’d always take a random static data format over a random API. Databases and standard file formats are a nice middle ground where you’re not held hostage by shitty code.
@nicbarkeragain There was a very simple but fun tree-based algorithm that makes this work for rows with arbitrary (but known) heights:
https://t.co/gYZ8k9HxcB and https://t.co/JL0ERxyHde
It is kind of funny to still be defending both E2E learning and representation learning in 2026, as if we were back in 2015 or 2019. lol
The wild part is that this also looks like magic. People tried to optimize these kinds of metrics in the GAN era, and very often the results just collapsed.
Now it works, not because the idea suddenly became obvious, but because enough pieces finally line up: representations, generators, optimization, scale, and the pipeline.
Maybe this is the deep learning bitter lesson again: if it is not mathematically impossible, deep learning might eventually make it happen.
Also sharing the perspectives from Zhengyang. We have countless, fruitful discussions during this project. At the center, it is how we should view representation in 2026
Two months ago, I vaguely posted a number: 0.9 FID, one-step, pixel space.
Now it is 0.75, and can be even lower.
Many wonder how.
I thought it might end as a small FID prank: simple and deliberate.
It started with one question: can FID be optimized directly, and what does it reveal?
Introducing FD-loss.