@MainzOnX Fix H, D per model. Bucket S to powers of 2. Let XLA pad each bucket. Cache compiled HLOs keyed by bucket. Compile on cold start only. Amortized over 000s of requests, the recompile cost vanishes
@ritv3999 Nice! I landed in the 0.45 hood as well. Definitely been interpreting "works at all" as exciting. Curious what your arch choice was for where the noised target enters.
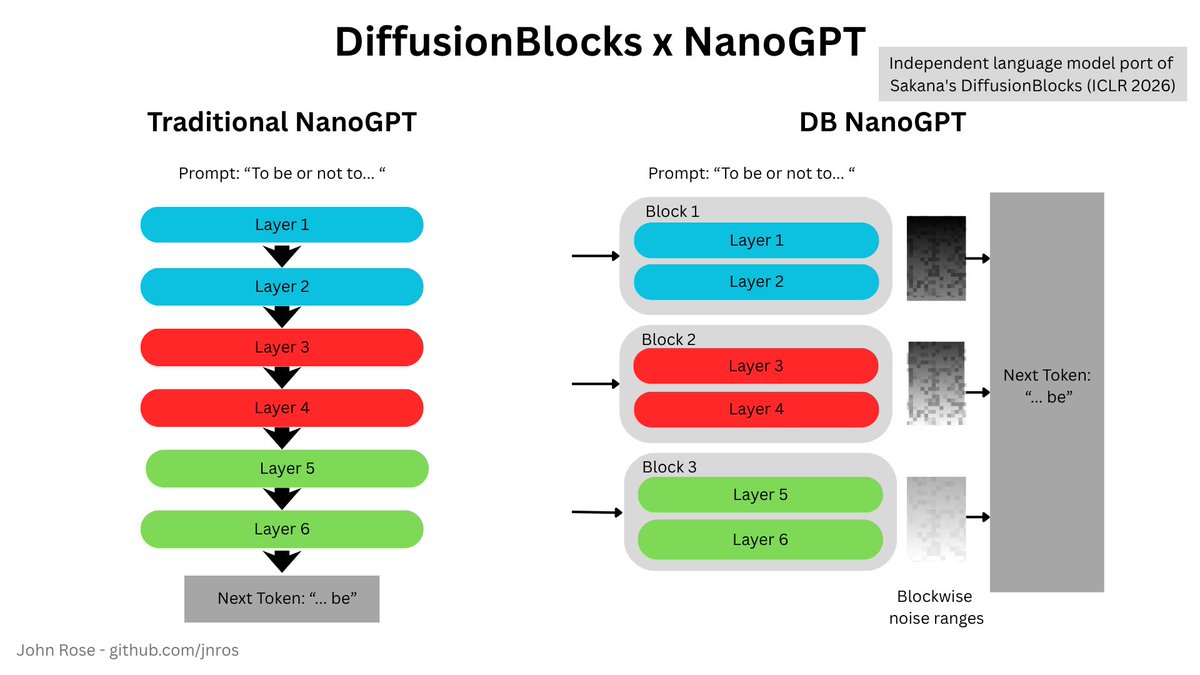
@ritv3999 Early numbers: 6-layer causal GPT, 3 independent blocks. ~2.16× lower peak VRAM, val CE within ~0.6 nat of baseline. Costs more training steps to converge