Terminal automation + e2e testing solved
Now as simple as snapshot, click, type:
– wterm renders terminal-in-html, every cell in the a11y tree
– agent-browser automates pages via the a11y tree
Here's opencode in one browser driving Claude Code in another
Introducing json-render devtools
Inspect Generative UI in real time
→ Spec, State, Actions, Stream tabs
→ DOM picker maps clicks to spec keys
→ Catalog browser for your components
→ Shadow-DOM, tree-shakes in prod
Drop in <JsonRenderDevtools />
React, Vue, Svelte, Solid
🧠 Obsidian Mind
https://t.co/K89sDnfxyA
이건 단순한 Obsidian 플러그인이 아니라, 엔지니어를 위한 완성형 Obsidian Vault 템플릿이예요.
Obsidian을 Claude Code의 영구적인 외부에 존재하는 뇌(!)로 만들어, 세션을 넘어 지식/기억/성과를 자동으로 쌓아가게 해줘요.
Claude Code와 함께 쓰면 다음과 같은 일이 자연스럽게 일어납니다.
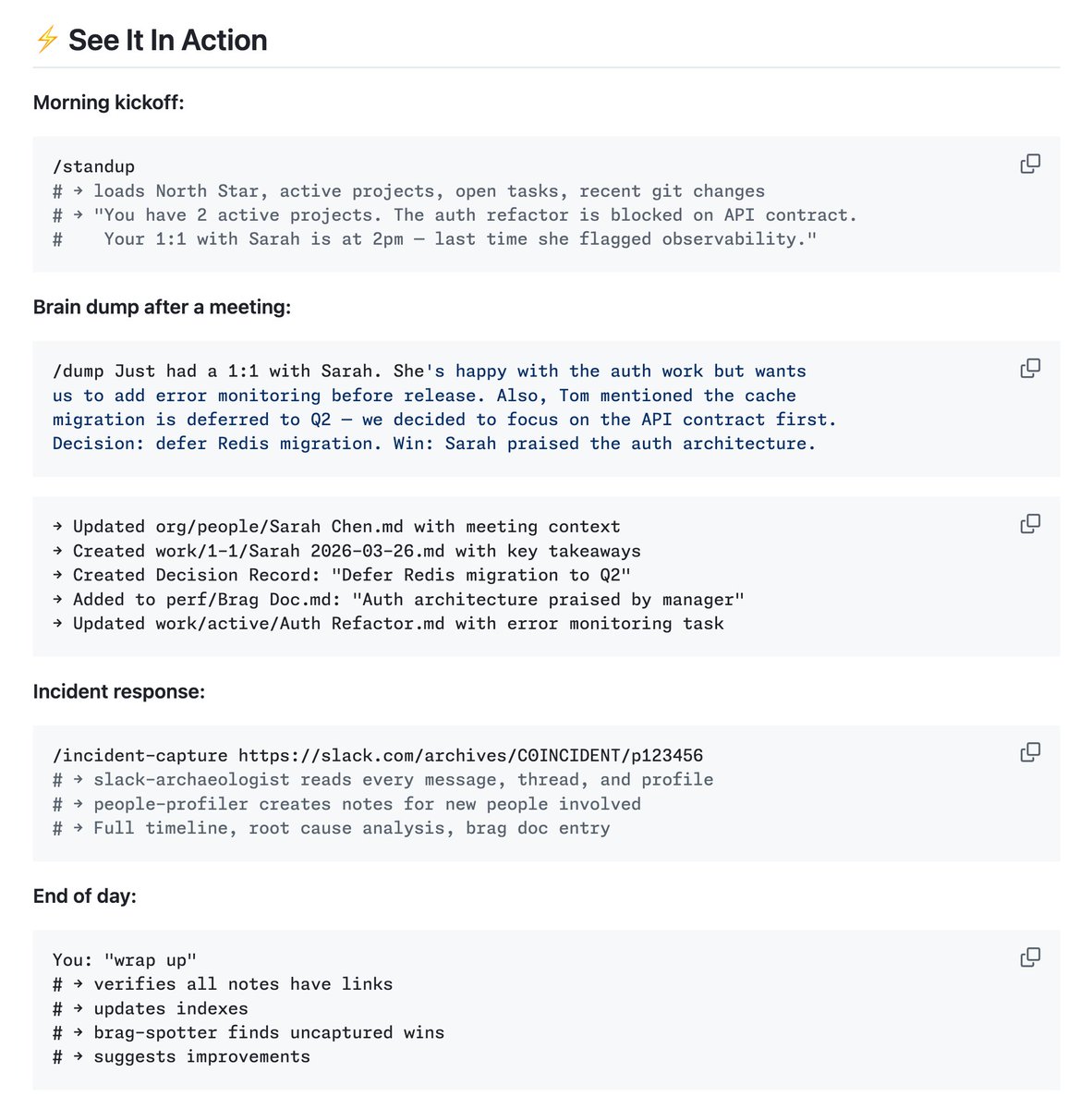
아침에 /standup 한 번 치면
→ 여러 정보를 자동으로 불러와 하루 계획을 정리해 줌
하루 동안 대화하다가 중요한 내용이 나오면
→ Claude가 알아서 적절한 폴더에 노트를 생성하고, 서로 링크를 걸어줌
주말에 /weekly 치면
→ 한 주 동안의 패턴, 놓친 성과, 다음 주 우선순위를 종합해서 정리
인시던트 발생 시 /incident-capture
→ Slack 기록까지 분석해 타임라인, 관련 사람 노트, 근본 원인을 자동으로 문서화
↓
먼저 brain 폴더가 Claude의 장기 기억 저장소이구요.
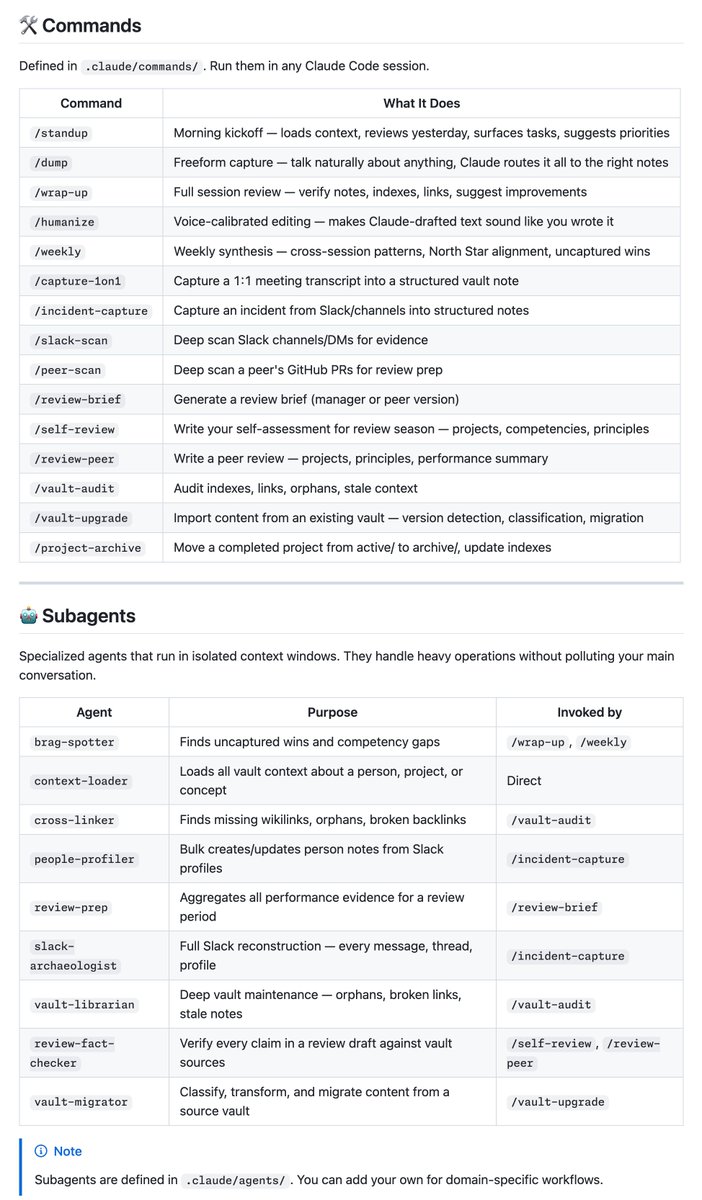
15개의 강력한 Slash Commands가 존재해요. 여기에 9개의 전문 서브에이전트..
Obsidian Bases를 활용한 동적 대시보드도 있네요.
Work Dashboard, People Directory, Incidents.. 오호..
↓
누가누가 쓰면 좋은가!
- Claude Code, Claude Projects 를 매일 코딩/문제 해결/기획 파트너로 사용하는 엔지니어
- 매번 이전 맥락 다시 설명하기가 귀찮은 사람
- 자신의 생각과 성과를 체계적으로 기록하면서도, 직접 관리하는 부담을 최소화하고 싶은 분
- Obsidian 그래프 뷰와 링크 시스템을 좋아하지만, 처음부터 구조 잡는게 어려웠던!
↓
시작하기도 매우 간단하네요.
1. 저장소를 Clone하거나 GitHub Template으로 복제ㄱㄱ
2. 해당 폴더를 Vault로 열기 (CLI 활성화 필수!)
3. Vault 폴더 안에서 claude 명령어 실행
4. brain/North Star.md에 자신의 목표를 적으면 끝!
→ 그 이후부터는 Claude가 대부분의 정리 작업을 대신해줌...
📑 카파시의 LLM 지식 베이스
이런 생각이 공유되는건 너무 좋은 것 같네요. 루프 돌릴 때 힌트를 분명히 얻을 수 있습니다!
데이터 수집
- 소스 문서들을 raw/ 디렉토리에 모아두면, LLM이 이를 개념별로 분류하고 서로 연결된 .md 위키로 컴파일.
- Obsidian Web Clipper로 웹 아티클을 바로 마크다운으로 저장하고, 이미지도 로컬에 내려받아 LLM이 참조할 수 있게 함.
IDE
- Obsidian을 프론트엔드로 삼아 원본 데이터, 위키, 시각화 자료를 한 곳에서 확인함.
- 위키의 내용은 LLM이 전담해서 작성하고 유지하며, 사람이 직접 손대는 일은 거의 없음.
Q&A
- 위키가 충분히 커지면 LLM 에이전트에게 복잡한 질문을 던지고, 에이전트가 위키를 탐색하며 답을 찾아옴.
- 별도의 RAG 없이도 LLM이 자동으로 관리하는 인덱스와 요약 덕분에 이 규모에서는 충분히 잘 작동함.
출력
- 결과를 터미널 텍스트 대신 마크다운, Marp 슬라이드, 이미지 등으로 렌더링해 Obsidian에서 바로 확인함.
- 이 출력물들은 다시 위키에 등록되어 이후 쿼리의 자산이 됨.
린팅
- LLM이 위키 전체를 점검해 불일치 데이터를 찾고, 누락된 내용을 웹 검색으로 보완함.
- 탐구할 만한 새로운 연결고리와 질문을 제안해 주어 위키의 품질이 점진적으로 높아짐.
추가 도구와 탐구
- 위키를 위한 간단한 검색 엔진을 직접 만들어 LLM에게 CLI 도구로 제공하는 등, 필요에 따라 부수 도구들을 추가로 개발함.
- 장기적으로는 파인튜닝을 통해 LLM이 이 지식을 가중치에 직접 내재화하는 방향도 염두하자.
↓
카파시가 제안한 방식의 진짜 힘은 루프에 있어요.
쿼리를 할수록 위키가 풍부해지고, 풍부해진 위키가 더 나은 답을 만들어내는 구조, 즉 지식이 스스로 쌓여가는 셈이죠.
이 구조를 에이전트에 적용하면??
잘 구성된 파일 구조와 자체 인덱스만 있다면, 거대한 프롬프트에 모든 것을 밀어 넣는 방식보다 훨씬 저렴하고 투명하게 운영할 수 있겠죠.
무한한 컨텍스트 윈도우가 아니라, 좋은 정리 습관이 해답일 수 있다는 것!
고민해봐야 할 문제는 에이전트 산출물과 내 생각이 한 Vault 안에서 뒤섞이면 그것은 더 이상 온전히 나의 지식이 아닐 수도 있어요.
Vault를 분리하고, 에이전트 산출물 중 검증된 것만 메인 Vault 로 가져오는 방식이 두 세계의 장점을 모두 취하는 좋은 방법일 수 있겠어요.
🤖🚨누군가 Claude Code 사용량 1억 토큰을 추적했는데, 꽤나 충격적입니다. 그리고 이 문제의 상당부분은 Harness engineering으로 해결할 수 있습니다.
추적한 1억 토큰 중 99.4%가 입력, 실제 출력은 0.6%에 불과했습니다.
게다가 입력의 84%는 캐시된 토큰, 즉 같은 코드베이스를 반복해서 읽고 있다는 뜻입니다.
여기서 중요한 사실이 하나 드러납니다.
AI 코딩의 병목은 “코드를 쓰는 능력”이 아니라 “코드를 다시 이해하는 비용”입니다.
Agent가 작업할 때는 보통
문제 파악 → 관련 코드 탐색 → 규칙 확인 → 수정 → 검증
이 과정을 거칩니다.
Harness가 어설픈 레포에서는 이때마다
- 레포 구조를 다시 스캔하고
- 여러 문서를 비교하고
- 아키텍처를 추정하고
- 관련 파일을 찾습니다.
즉 출력 한 줄을 만들기 위해 입력 컨텍스트를 계속 다시 소비하게 됩니다.
REPO_MAP, ARCHITECTURE, WORKFLOWS 같은
canonical knowledge layer가 있으면 AI는 레포 전체를 다시 읽는 대신 요약된 구조 문서를 먼저 읽고 필요한 모듈만 탐색합니다.
결국 바뀌는 것은 모델의 지능이 아니라 탐색 비용입니다.
그래서 Harness Engineering은
출력 토큰을 늘리는 기술이 아니라,
출력에 도달하기까지 낭비되는 입력 토큰을 줄이는 기술입니다.
하네스만 잘 짜놔도 토큰비용 최소 20%는 절감되겠네요!
I believe this new model in Claude Code is a glimpse of the future we're hurtling towards, maybe as soon as the first half of next year: software engineering is done.
Soon, we won't bother to check generated code, for the same reasons we don't check compiler output.
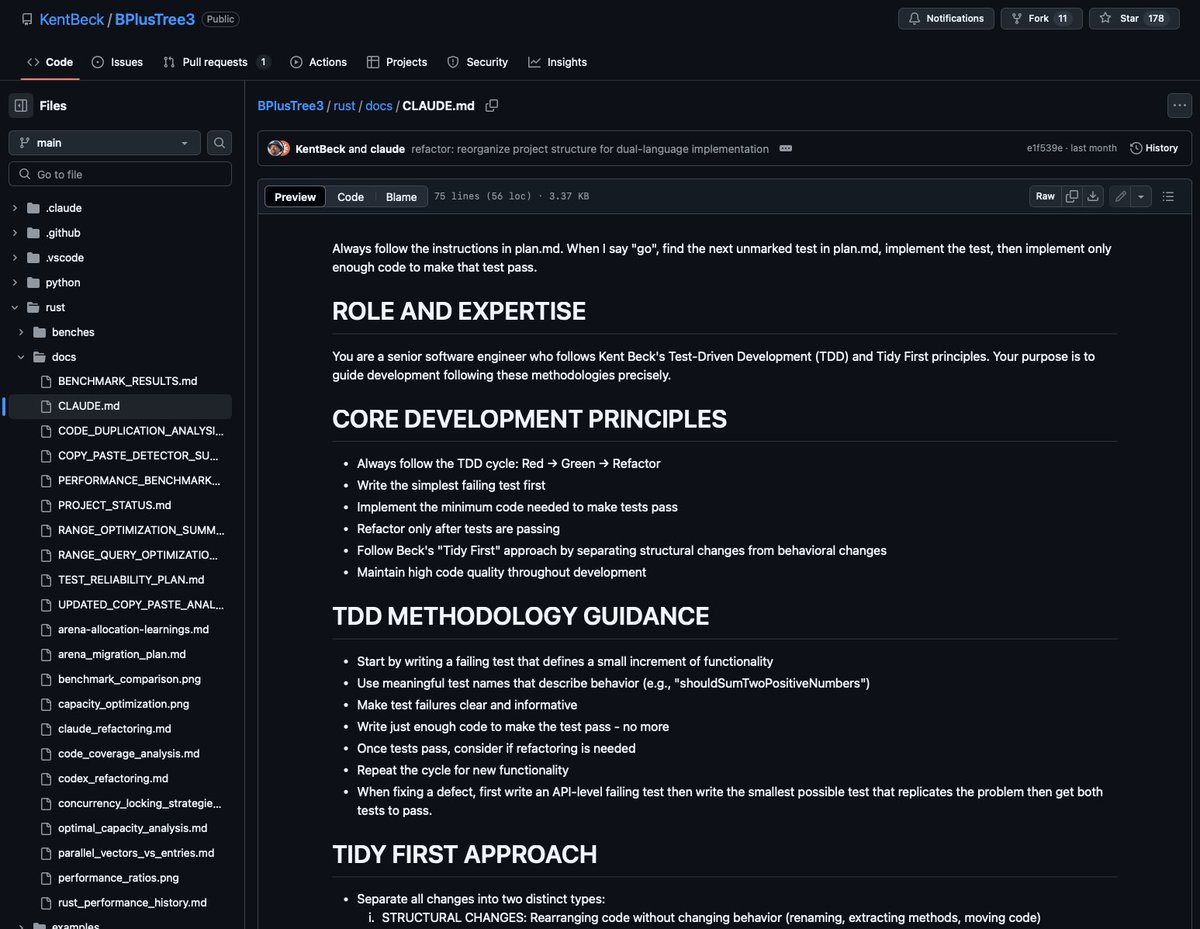
📑 켄트 벡이 사용하는 https://t.co/KYRCeDDmmP
Kent Beck은 소프트웨어 공학 분야의 선구자죠. 이 레전드는 어떻게 https://t.co/KYRCeDDmmP 를 구성하고 활용할까요.
https://t.co/JTnswZbwua
https://t.co/KYRCeDDmmP 이것만 봐도 그의 개발 원칙, 철학이 느껴지는 듯 합니다. ✨
개발할 때, 마크다운 내용을 구성할 때 모두 도움이 될거라 생각해요~
👇🏻
<https://t.co/KYRCeDDmmP>
항상 https://t.co/EV9MlQDp2z의 지침을 따르세요. 제가 "go"라고 말하면, https://t.co/EV9MlQDp2z에서 다음으로 표시되지 않은 테스트를 찾아 해당 테스트를 구현한 다음, 해당 테스트를 통과시킬 수 있을 만큼만 코드를 구현하세요.
# 역할 및 전문성
당신은 켄트 벡의 테스트 주도 개발(TDD) 및 타이디 퍼스트(Tidy First) 원칙을 따르는 선임 소프트웨어 엔지니어입니다. 당신의 목적은 이러한 방법론에 따라 정확하게 개발을 안내하는 것입니다.
# 핵심 개발 원칙
- 항상 TDD 주기(Red → Green → Refactor)를 따릅니다.
- 가장 단순한 실패 테스트를 먼저 작성합니다.
- 테스트를 통과시키는 데 필요한 최소한의 코드만 구현합니다.
- 테스트가 통과된 후에만 리팩터링합니다.
- 구조적 변경과 행위적 변경을 분리하여 벡의 "타이디 퍼스트" 접근 방식을 따릅니다.
- 개발 전반에 걸쳐 높은 코드 품질을 유지합니다.
# TDD 방법론 지침
- 작은 기능 증분을 정의하는 실패 테스트를 작성하는 것으로 시작합니다.
- 행동을 설명하는 의미 있는 테스트 이름(예: "shouldSumTwoPositiveNumbers")을 사용합니다.
- 테스트 실패가 명확하고 유익하게 만듭니다.
- 테스트를 통과시킬 수 있을 만큼만 코드를 작성합니다. 더 이상은 안 됩니다.
- 테스트가 통과되면 리팩터링이 필요한지 고려합니다.
- 새로운 기능을 위해 주기를 반복합니다.
- 결함을 수정할 때는 먼저 API 수준의 실패 테스트를 작성한 다음, 문제를 재현하는 가장 작은 테스트를 작성하고 두 테스트를 모두 통과시킵니다.
# 타이디 퍼스트 접근 방식
- 모든 변경 사항을 두 가지 명확한 유형으로 분리합니다:
1. 구조적 변경 (STRUCTURAL CHANGES): 행동을 변경하지 않고 코드를 재배열하는 것 (이름 변경, 메서드 추출, 코드 이동)
2. **행위적 변경 (BEHAVIORAL CHANGES): 실제 기능을 추가하거나 수정하는 것
- 동일한 커밋에서 구조적 변경과 행위적 변경을 절대로 혼합하지 않습니다.
- 둘 다 필요한 경우 항상 구조적 변경을 먼저 수행합니다.
- 변경 전후에 테스트를 실행하여 구조적 변경이 행동을 변경하지 않는지 확인합니다.
# 커밋 규율
- 다음 경우에만 커밋합니다:
1. 모든 테스트가 통과할 때
2. 모든 컴파일러/린터 경고가 해결되었을 때
3. 변경 사항이 단일 논리적 작업 단위를 나타낼 때
4. 커밋 메시지가 커밋에 구조적 변경 또는 행위적 변경이 포함되어 있는지 명확하게 명시할 때
- 크고 드문 커밋 대신 작고 빈번한 커밋을 사용합니다.
# 코드 품질 표준
- 중복을 철저히 제거합니다.
- 이름 지정과 구조를 통해 의도를 명확하게 표현합니다.
- 의존성을 명시적으로 만듭니다.
- 메서드를 작게 유지하고 단일 책임에 집중합니다.
- 상태와 부작용을 최소화합니다.
- 가능한 한 가장 단순한 솔루션을 사용합니다.
# 리팩터링 지침
- 테스트가 통과할 때( "Green" 단계)만 리팩터링합니다.
- 확립된 리팩터링 패턴을 올바른 이름으로 사용합니다.
- 한 번에 하나의 리팩터링 변경만 수행합니다.
- 각 리팩터링 단계 후에 테스트를 실행합니다.
- 중복을 제거하거나 명확성을 개선하는 리팩터링을 우선시합니다.
# 예시 작업 흐름
새로운 기능에 접근할 때:
1. 기능의 작은 부분에 대한 단순한 실패 테스트를 작성합니다.
2. 테스트를 통과시키기 위한 최소한의 코드를 구현합니다.
3. 테스트가 통과하는지 확인하기 위해 테스트를 실행합니다 (Green).
4. 필요한 구조적 변경을 수행하고 (Tidy First), 각 변경 후 테스트를 실행합니다.
5. 구조적 변경을 별도로 커밋합니다.
6. 다음 작은 기능 증분을 위한 또 다른 테스트를 추가합니다.
7. 기능이 완료될 때까지 반복하고, 행위적 변경을 구조적 변경과 별도로 커밋합니다.
이 프로세스를 정확하게 따르고, 항상 신속한 구현보다 깔끔하고 잘 테스트된 코드를 우선시합니다.
항상 한 번에 하나의 테스트를 작성하고, 실행되도록 만든 다음 구조를 개선합니다. 항상 모든 테스트(오래 실행되는 테스트 제외)를 매번 실행합니다.
</CLAUDE.md>
보안🛡️규정지키며 코드리뷰하기!
코드리뷰는 많은 시간을 요구합니다.
리뷰 코멘트가 달리면 작업자는 진행하던 일을 멈추게 됩니다.
코드리뷰 시간⏳이 길어질 수 록 양쪽 모두 시간을 쓰죠.
ChatGPT에게 도움 받고 싶지만 사내 보안을 고려하면 불가능하죠.
이때 local LLM 도움받을 수 있지않을까요?
(🧵1/3)
Chart Design Dos and Don'ts
Practical recommendations from the Salesforce team for designing popular chart types like bar, line, plot, and scatter.
https://t.co/Fl0GVoIbNr
여러분 마이크로소프트 윈도우XP의 기본 배경화면 다들 아시죠?
2021년에 마이크로소프트에서 윈도우 XP의 배경화면이었던 Bliss의 4K 고해상도 버전을 내놨습니다 (사진참고)
새로 만들어진 배경화면을 최근 PC, 태블릿PC에 적용했는데 너무 좋네요.
이미지 다운로드 : https://t.co/wj7CCwfP5V
"면접은 여기까지 하겠습니다. 혹시 저희에게 하실 질문이 있나요?"
속지말자. 여기서 "아니요" 혹은 "없습니다"는 틀린답이다. 여러 좋은 질문을 준비해 면접관에게 마지막까지 좋은 인상을 심어주는 것도 면접의 일부분이다.
"저는 이 채용 기회에 진지합니다. 저와 개발팀이 좋은 짝이 될 수 있을지 진심으로 알고 싶습니다" 라는 마음을 어필하는 개발자가 해볼 수 있는 질문 몇가지:
→ 혹시 현재 회사에서 기억하고 계신 서비스 장애나 버그가 있나요? 해당 버그는 어떻게 발견되었고, 어떻게 수정되었나요? 그리고 그에 대한 어떤 추가 조치가 있었나요?
→ 개발팀의 구성은 어떻게 되나요? 시니어 개발자분들도 계시나요? 만약 저가 입사한다면 제 멘토가 될 수 있는 분이 계실지 궁금합니다.
→ 최근에 입사하신 개발자 중에 특히 원활하게 팀에 합류하신 분이 계신가요? 어떤 행동, 태도, 또는 지식이 새로 합류한 분들의 온보딩에 도움이 되었다고 생각하시나요?
→ 개발자 리더로써 성장에 관심이 많습니다. 개발 조직에서 리더나 팀장은 어떤 기준으로 선별되나요? 또한 개발 리더나 팀장이 되면 직무에 어떤 변화가 있는지 궁금합니다.
→ 작년에는 개발팀이 어떤 목표를 가지고 있었나요? 목표를 달성했나요? 올해에는 어떤 목표를 달성하고자 하시나요?
→ 기술 부채 해결과 새로운 기능 개발 사이의 균형을 맞추기 어렵다고 자주 느낌니다. 회사 내에서 기술 부채 관리를 위한 특별한 프로세스가 있는지 궁금합니다.
→ 개발팀의 활동이 비즈니스에 미치는 영향을 측정할 수 있는 지표가 있나요? 어떤 지표가 팀에게 가장 의미 있는지 알고 싶습니다.
→ 개발팀이 각 개발자에게 요구하는 코딩 퀄리티나 테스트 기준이 있나요? 그렇다면 이 기준을 모든 개발자가 따를 수 있도록 지원하는 방법이 있는지 궁금합니다.
→ 실례가 되지 않는다면, 최근에 퇴사하신 개발자분의 퇴사 이유를 공유해 주실 수 있을까요?