1/ 🧵
New #EMNLP2025 Paper !!
Toxicity detection is subjective; shaped by norms, identity, & context. Existing models and dataset overlook this nuance.
Enter MODELCITIZENS: a new dataset designed to address this.
✔️ 6.8K posts, 40K annotations across diverse groups
✔️ Context-augmented scenarios
✔️ New finetuned models (LLAMACITIZEN-8B, GEMMACITIZEN-12B) beat GPT-4o-mini by 5.5%
(🚨 Offensive Content Warning)
Great to see @nllpworkshop already celebrating its 8th occurrence, this time in Budapest collocated with @emnlpmeeting!
Go submit your legal AI papers there 🔥
Kudos to the organizing committee for making this happen year after year!
@nikaletras (University of Sheffield), Leslie Barrett (Bloomberg), @KiddoThe2B (University of Copenhagen), @CatalinaGoanta (Utrecht University), Daniel Preotiuc-Pietro (Bloomberg), @gerasimoss (Maastricht University), @shanshan_xu3 (University of Copenhagen)
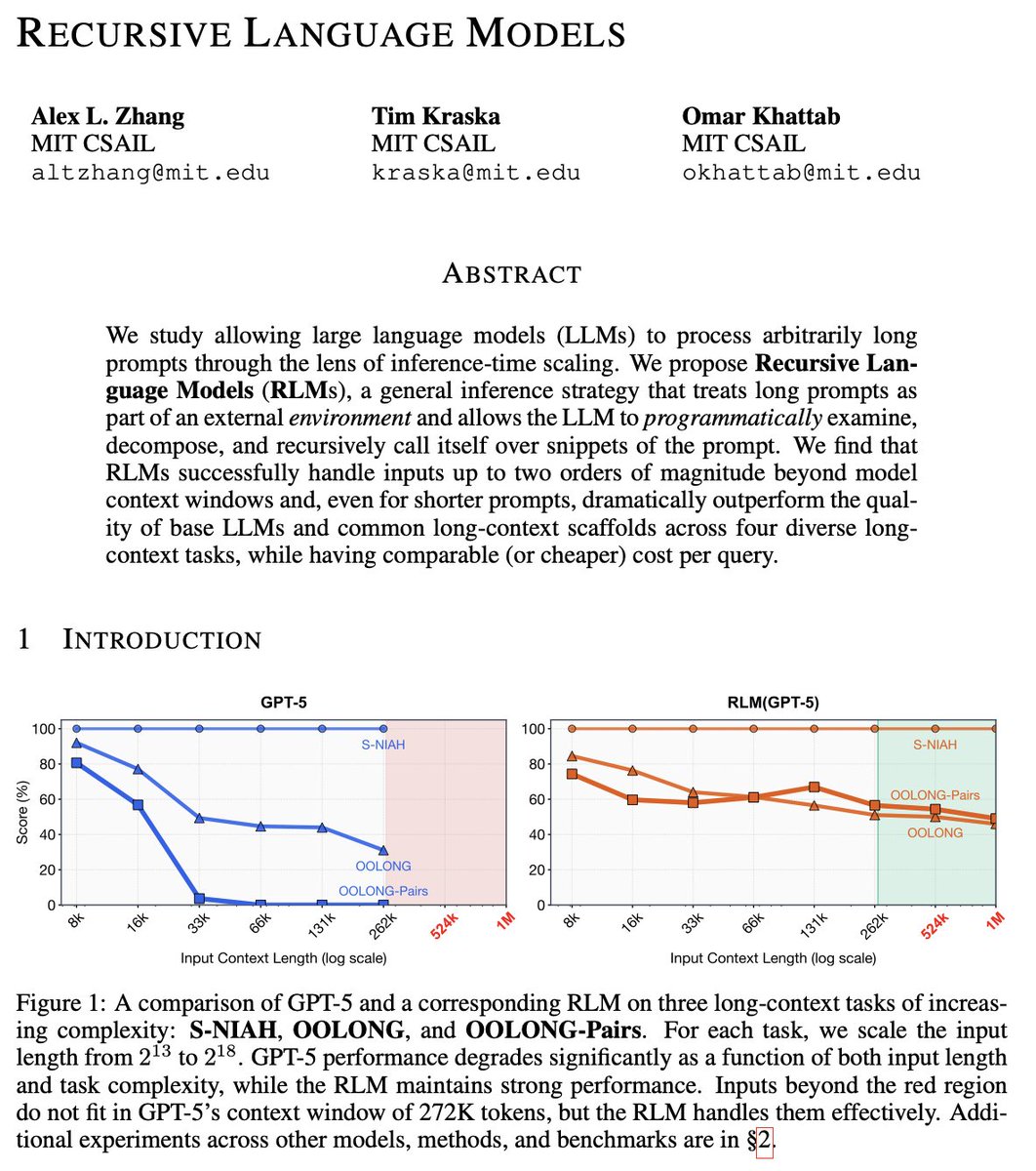
Much like the switch in 2025 from language models to reasoning models, we think 2026 will be all about the switch to Recursive Language Models (RLMs).
It turns out that models can be far more powerful if you allow them to treat *their own prompts* as an object in an external environment, which they understand and manipulate by writing code that invokes LLMs!
Our full paper on RLMs is now available—with much more expansive experiments compared to our initial blogpost from October 2025!
https://t.co/x47pIfIkTb
Stop using LoRA for RLVR!!!
New paper released👉Evaluating Parameter Efficient Methods for RLVR
📖Alphaxiv: https://t.co/VCNTG4TZvP
💻Github: https://t.co/bUkRjjzBvc
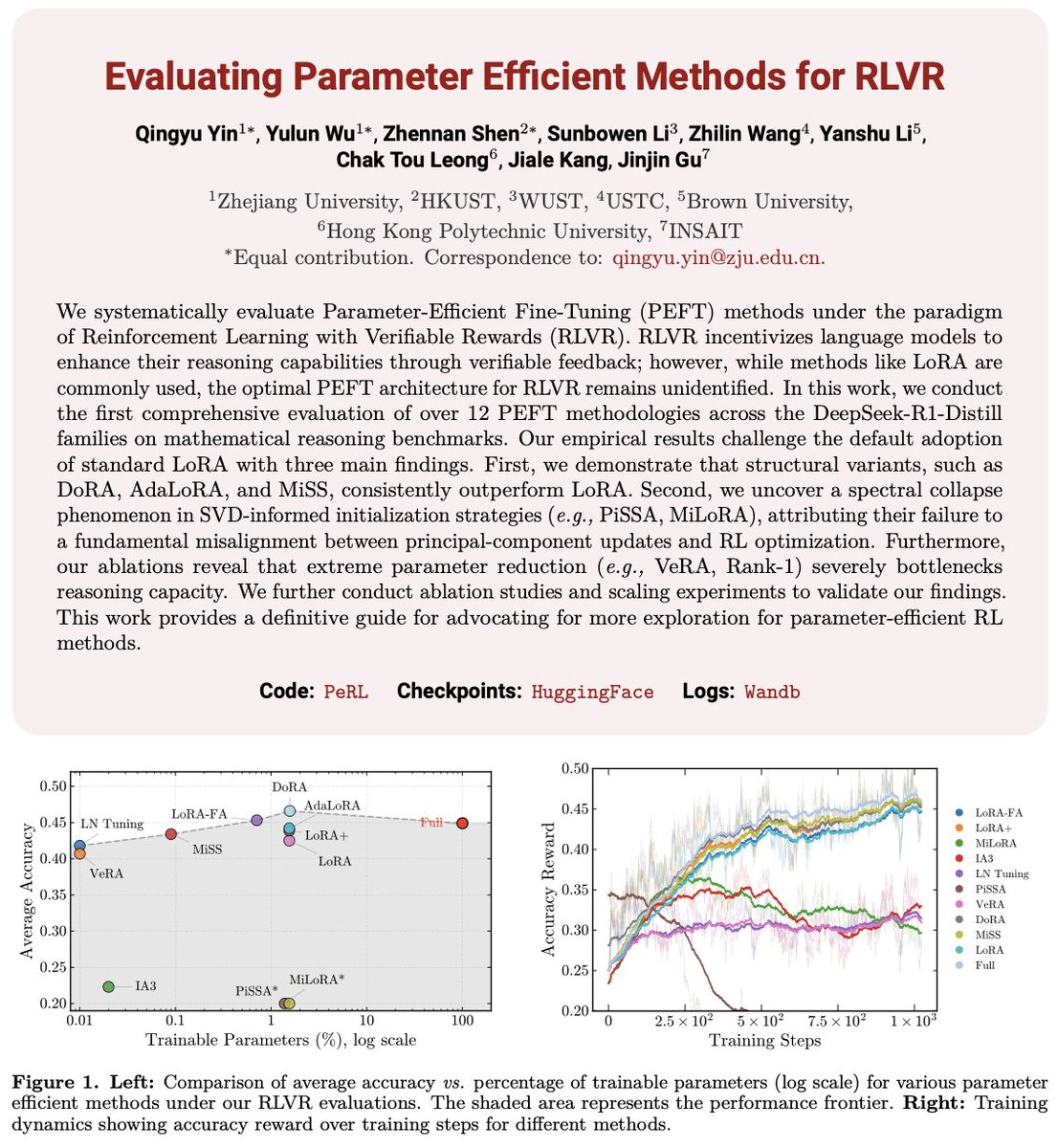
Is standard LoRA truly the optimal choice for Reinforcement Learning?. We present the first large-scale evaluation of over 12 PEFT methodologies using the DeepSeek-R1-Distill family on complex mathematical reasoning benchmarks.
Key Finding: Standard LoRA is suboptimal. Structural variants such as DoRA, AdaLoRA, and MiSS consistently outperform standard LoRA. Notably, DoRA (46.6% avg. accuracy) even surpasses full-parameter fine-tuning (44.9%) across multiple benchmarks.
The failure of SVD-based initialization.
Strategies like PiSSA and MiLORA experience significant performance degradation or total training collapse. This is due to a fundamental "spectral misalignment": these methods force updates on principal components, while RLVR intrinsically operates in the off-principal regime.
The Expressivity Floor.
While RLVR can tolerate moderate parameter reduction, extreme compression (e.g., VeRA, IA³, or Rank-1 adapters) creates an information bottleneck. Reasoning tasks require a minimum threshold of trainable capacity to successfully reorient policy circuits.
Recommendations for the community:
a. Move beyond the default adoption of standard LoRA.
b. Prioritize geometry-aware adapters like DoRA that decouple magnitude and direction.
c. Avoid SVD-informed initializations for RL tasks.
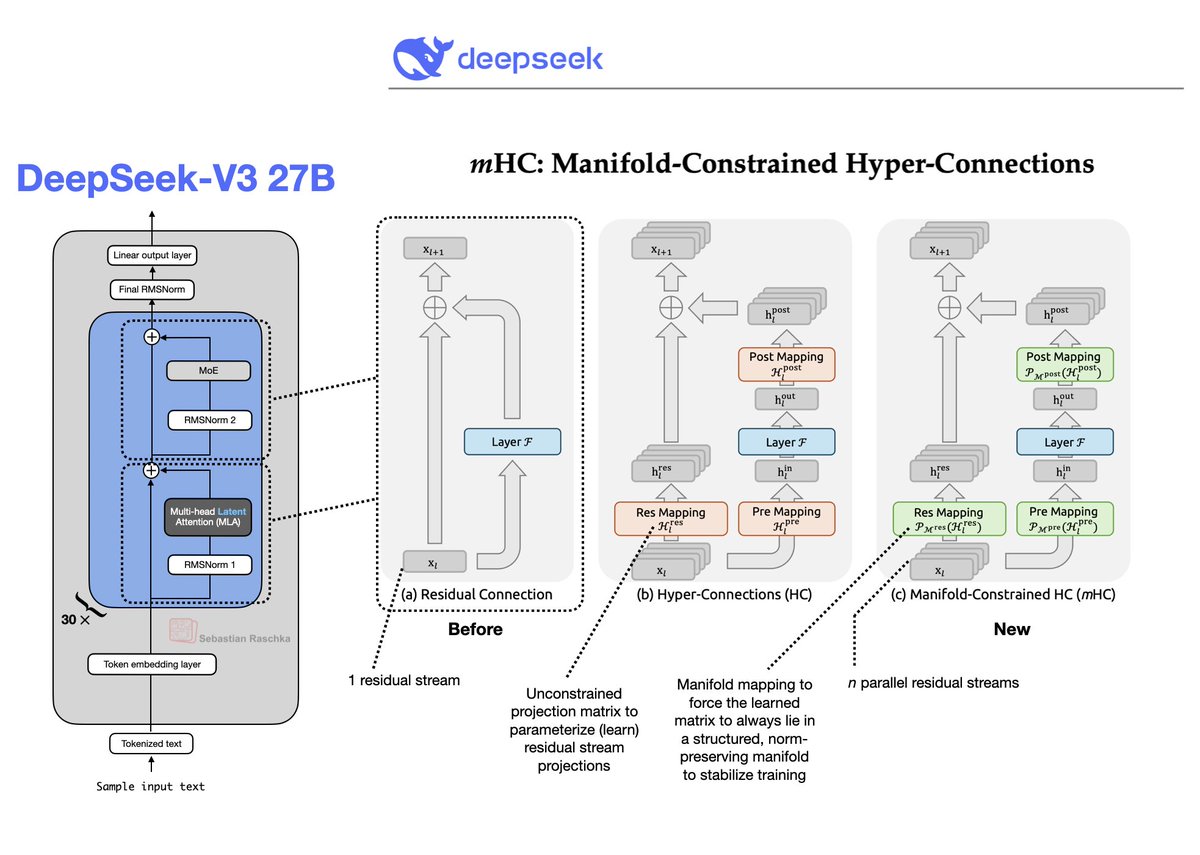
Efficiency and performance tweaks in the transformer architecture usually focus(ed) on the normalization, attention, and FFN modules.
Well, here is a holiday gift from DeepSeek (https://t.co/ow1RpEG2Bv).
Finally some improvements of the residual path as well.
Join us at the #RegulatableML workshop at #NeurIPS2025#NeurIPSanDiego to bridge the gap between AI regulation and real-world practice!
🗓 Date: Dec 7, 2025
⏰ Time: 8:45 am - 5:30 pm (PST)
📍 Location: Upper Level Room 1AB, San Diego, CA
More info: https://t.co/NtaC9wV0ed
#neurips2025#NeurIPS Call for AI researchers!
Attend the 𝟑𝐫𝐝 𝐑𝐞𝐠𝐮𝐥𝐚𝐭𝐚𝐛𝐥𝐞 𝐌𝐋 𝐖𝐨𝐫𝐤𝐬𝐡𝐨𝐩, Dec 7, San Diego, CA. Bridging ML safety research with regulatory frameworks.
Join us! 🔗https://t.co/NtaC9wV0ed
Today, the UVA School of Data Science was packed with new and familiar faces for our annual Datapalooza event. A special thank you to our keynote speaker Danielle Citron and all of our presenters for Datapalooza 2025: Truth and Accountability in the Age of AI.
📢Please retweet: We are hiring a **Postdoc** at UVA to work on Continually Monitoring and Updating Multi-modal Medical AI Models!
Great opportunity to design impactful methods alongside great collaborators @_ahmedmalaa and @RoxanaDaneshjou
More info: https://t.co/a3Qs5X0pgy
⏰✨ Good news for all the fashionably late submitters out there! We’ve extended the deadline for the First International Workshop on Data Mining and AI for Law (DMAIL 2025) 🎉.
Instead of September 1, you now have until September 10 to polish, perfect, and procrastinate (just a little bit longer 😉).
So if your paper was 90% ready, congrats—it’s now magically 100% on time. 🚀
🔗 Workshop details: https://t.co/mP44wDzBWD
1/ 🧵
New #EMNLP2025 Paper !!
Toxicity detection is subjective; shaped by norms, identity, & context. Existing models and dataset overlook this nuance.
Enter MODELCITIZENS: a new dataset designed to address this.
✔️ 6.8K posts, 40K annotations across diverse groups
✔️ Context-augmented scenarios
✔️ New finetuned models (LLAMACITIZEN-8B, GEMMACITIZEN-12B) beat GPT-4o-mini by 5.5%
(🚨 Offensive Content Warning)