A Oxford PhD student got flagged for submitting AI-generated work.
His advisor called it the most sophisticated research process he had seen in 20 years.
The student had not used AI to write a single word.
Here is the workflow that got him reported.
He starts every essay with a diagnostic he calls brutal. He dumps his rough argument into Claude and asks one question: what are the three weakest logical jumps in this reasoning, and where would a hostile examiner attack first? The AI does not write his essay. It destroys his draft, and then he rebuilds from whatever survives.
Most students using AI are doing the opposite. They hand Claude a topic and ask it to write. He hands Claude his thinking and asks it to find every place where that thinking falls apart. The difference between those two approaches is the difference between outsourcing your brain and sharpening it.
The second step is the one that made his advisor go quiet. He uploads the five most important papers in his field alongside his draft and asks Claude what claims in his argument contradict or oversimplify what these authors actually found. Most PhD students cite papers they have skimmed once. He cites papers he has been forced to genuinely reckon with, because Claude keeps catching the places where he got them wrong.
The final move is almost unfair. Before he submits anything, he pastes his conclusion and runs one more prompt. He asks what a philosopher of science would say is missing from this argument and what assumptions he is making that he has not defended. His essays come back from reviewers with phrases like unusually rigorous and demonstrates rare critical depth, and his committee has no idea that the depth came from a machine asking him harder questions than any human in his department was willing to ask.
The academic integrity hearing lasted three hours. The panel asked him to rebuild his methodology from scratch in the room. He opened his laptop and showed them exactly how the workflow ran, prompt by prompt. They did not just clear him. They gave him the highest grade in the department's history and asked him to present the process to faculty.
Here is what that story actually means. What took most PhD candidates six months of back-and-forth with advisors, he was compressing into a single session because he had figured out something almost nobody else has. AI does not make your thinking better by replacing it. It makes your thinking better by attacking it faster than any human critic ever would.
He was not using AI to write. He was using it to think harder than he could alone.
The tool is the same one everyone has. The workflow is the part nobody is teaching.
Pierre de Fermat was not a professional academic; he worked full-time as a lawyer and government official and pursued mathematics purely as a passionate hobby.
He went on to pioneer number theory and modern calculus. He also famously scribbled the 'Last theorem' conjecture in the margin of his copy of the ancient Greek text Arithmetica by Diophantus-- the conjecture was solved by mathematician Andrew Wiles 357 years later.
Do you know the man behind modern rigorous mathematics?
Born in Paris in 1789, Augustin-Louis Cauchy grew up during the French Revolution, a time of chaos and transformation.
As a young man, he showed an extraordinary gift for mathematics and engineering.
He studied at École Polytechnique, one of France’s most elite scientific institutions.
Soon after, he worked as a military engineer on projects under Napoleon Bonaparte in Cherbourg, helping fortify the harbor. But his true passion was not fortifications—it was mathematics.
Cauchy began rebuilding calculus on a solid foundation of rigor, replacing vague intuition with precise definitions and proofs.
He clarified what it truly means for a sequence to converge, for a function to be continuous, and for a series to converge absolutely.
He introduced fundamental ideas such as Cauchy sequences, which formalize the concept of convergence.
He also developed the Cauchy–Riemann equations, central to complex analysis, and proved the Cauchy’s integral theorem—cornerstones of modern mathematics.
Cauchy was extraordinarily prolific, writing more than 700 papers and influencing nearly every branch of mathematics, from mechanics to number theory.
When he died in 1857, he had transformed mathematics into the precise and rigorous science we know today.
His name still appears everywhere: Cauchy sequences, Cauchy’s theorem, the Cauchy–Schwarz inequality—the mark of a true giant.
this is one of the best technical articles i’ve read lately. what separates you from anyone else that’s using AI is your ability to steer the LLM and squeeze what you want from it, not what it decides to offer. commit to the long-term investment of recording your “taste”.
Meet Roger Penrose;
Born in 1931 in Colchester, England, Roger Penrose grew up in an intellectual family, his father was a geneticist, his mother a doctor-turned-artist but he didn’t follow a straight path to physics.
As a child during World War II, he spent years in Canada, returning to England afterward. He studied mathematics at University College London, earning his degree, then pursued a PhD at Cambridge in algebraic geometry, completing it in 1957.
Early on, Penrose’s interests shifted. He briefly explored pure math before his curiosity pulled him toward physics, influenced by lectures from figures like Paul Dirac. He held temporary posts at various universities in England and the US, never quite settling into a conventional academic track right away.
Then he found general relativity.
Working on gravitational collapse, Penrose in 1965 introduced ingenious mathematical tools including the concept of trapped surfaces that proved black hole formation and singularities were inevitable consequences of Einstein’s theory, even without perfect symmetry.
This work stunned the field, showing black holes weren’t exotic curiosities but robust predictions of physics.
What made Penrose unique was not just rigor, but vision. He repeatedly uncovered hidden geometric structures in physical laws. He co-developed the Penrose-Hawking singularity theorems with Stephen Hawking, forever changing our understanding of the universe’s extremes. He invented twistor theory, a radical framework mapping space-time into complex geometry that has influenced quantum gravity pursuits. And his aperiodic Penrose tilings, non-repeating patterns, prefigured the discovery of quasicrystals and blurred lines between math and materials science.
In 2020, he received the Nobel Prize in Physics (shared) for demonstrating that black hole formation is a robust prediction of general relativity. He remains one of the few to bridge mathematics and physics so profoundly.
Within the scientific community, Penrose’s reputation is formidable.
His ideas often challenge consensus, and his lectures can leave audiences rethinking fundamentals.
Yet in person, he is thoughtful, unassuming, and generous often crediting others while quietly pursuing his own unconventional lines of inquiry.
Roger Penrose took a winding route through mathematics before revolutionizing our picture of black holes and the cosmos.
And still, he became one of the most original minds in modern physics and mathematics the quiet visionary many regard as a true pioneer of the field.
Why String Theory Won't Die
The string theory idea refuses to die because it's one of the few frameworks that forces a quantum object and spacetime geometry into the same picture.
In the render, a closed string isn’t just a loop doing pretty vibrations. Its internal phase pattern is a quantum degree of freedom, shown as color. At the same time, its motion stirs ripples in the surrounding metric, shown as the fabric below.
One object, two roles. A wave-like state living on the string, and a curvature-like response spreading through the background. You can literally watch quantum stuff and gravity stuff talk to each other in the same scene.
#StringTheory #Physics #QuantumMechanics #GeneralRelativity #MathematicalPhysics #SciComm
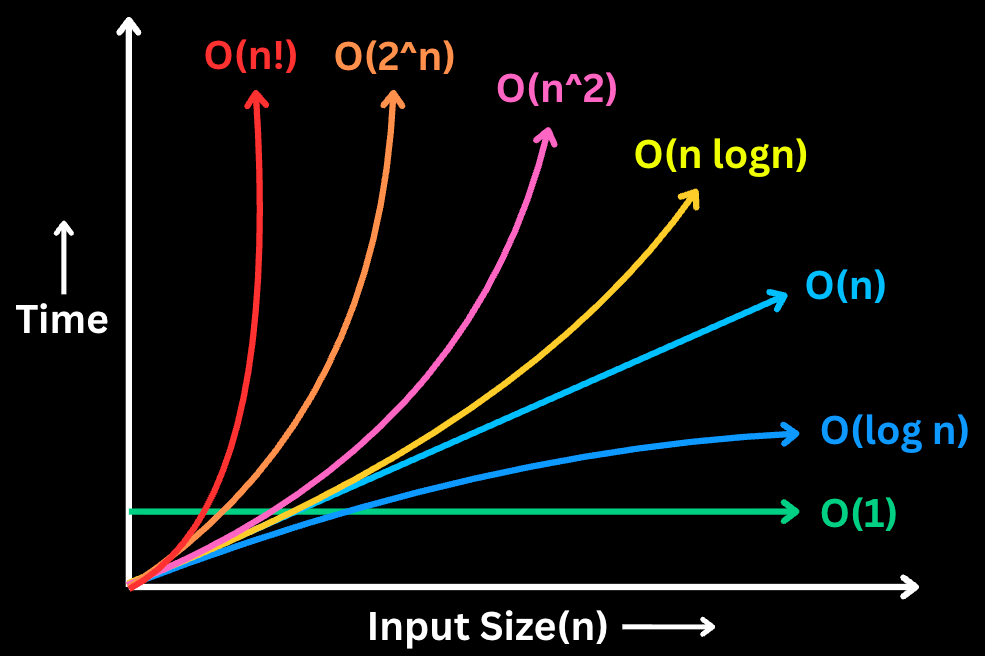
7 must-know runtime complexities for coding interviews:
1. 𝐎(1) - 𝐂𝐨𝐧𝐬𝐭𝐚𝐧𝐭 𝐭𝐢𝐦𝐞
- The runtime doesn't change regardless of the input size.
- Example: Accessing an element in an array by its index.
2. 𝐎(𝐥𝐨𝐠 𝐧) - 𝐋𝐨𝐠𝐚𝐫𝐢𝐭𝐡𝐦𝐢𝐜 𝐭𝐢𝐦𝐞
- The runtime grows slowly as the input size increases. Typically seen in algorithms that divide the problem in half with each step.
- Example: Binary search in a sorted array.
3. 𝐎(𝐧) - 𝐋𝐢𝐧𝐞𝐚𝐫 𝐭𝐢𝐦𝐞
- The runtime grows linearly with the input size.
- Example: Finding an element in an array by iterating through each element.
4. 𝐎(𝐧 𝐥𝐨𝐠 𝐧) - 𝐋𝐢𝐧𝐞𝐚𝐫𝐢𝐭𝐡𝐦𝐢𝐜 𝐭𝐢𝐦𝐞
- The runtime grows slightly faster than linear time. It involves a logarithmic number of operations for each element in the input.
- Example: Sorting an array using quick sort or merge sort.
5. 𝐎(𝐧^2) - 𝐐𝐮𝐚𝐝𝐫𝐚𝐭𝐢𝐜 𝐭𝐢𝐦𝐞
- The runtime grows proportionally to the square of the input size.
- Example: Bubble sort algorithm which compares and potentially swaps every pair of elements.
6. 𝐎(2^𝐧) - 𝐄𝐱𝐩𝐨𝐧𝐞𝐧𝐭𝐢𝐚𝐥 𝐭𝐢𝐦𝐞
- The runtime doubles with each addition to the input. These algorithms become impractical for larger input sizes.
- Example: Generating all subsets of a set.
7. 𝐎(𝐧!) - 𝐅𝐚𝐜𝐭𝐨𝐫𝐢𝐚𝐥 𝐭𝐢𝐦𝐞
- Runtime is proportional to the factorial of the input size.
- Example: Generating all permutations of a set.
♻️ Repost to help others in your network.
It is dangerously easy to build a neural network today without actually understanding how it works.
We live in an era of 'import torch'. You can train a model in three lines of code, but the moment you need to debug a collapsing loss function or a vanishing gradient, syntax won't save you. You need first principles.
I recently went through this notebook collection by Simon J.D. Prince, and it is the antidote to tutorial hell.
Instead of just showing you the code, it forces you to visualize the mechanics:
1./ The Math => It builds the intuition for shallow networks and regions before adding complexity.
2./ The Optimization => It doesn't just use an optimizer; it compares Line Search, SGD, and Adam so you see why they behave differently.
3./ The Modern Stack => It connects the dots from basic backpropagation all the way to Self-Attention and Graph Neural Networks.
Move from running code to engineering systems => this is a goldmine.
Building a GenAI app?
Don’t just plug in a model - design it to scale, adapt, and evolve.
Here’s your blueprint for future-ready GenAI systems. 👇
1. Modular Architecture
Separate UI, orchestration, models, and storage to swap parts independently. Use LangChain or LlamaIndex to build pipelines.
2. Context Engineering
Layer system prompts, memory, and retrieved knowledge to optimize generation. Use chunking and summarization to stay efficient.
3. Retrieval-Augmented Generation (RAG)
Connect vector DBs like Pinecone or Weaviate and use hybrid search (dense + keyword) for domain-specific relevance.
4. Low-Latency Design
Cut load times and delay using model distillation, quantization, and async I/O.
5. Agent-Based Systems
Use CrewAI, AutoGen, or LangGraph for task decomposition and tool execution via specialized sub-agents.
6. Tool & Plugin Integration
Enable LLMs to run code, hit APIs, or use external tools through OpenAI function-calling or LangChain routing.
7. Streaming & Feedback
Improve experience with real-time streaming via WebSockets and user feedback for continuous refinement.
8. Memory Management
Support both session and long-term memory using Redis, Postgres, or vector DBs for persistence.
9. Smart Deployment
Use K8s or serverless runtimes (like AWS Lambda) to deploy GenAI apps with dynamic scaling.
10. Observability
Track usage, hallucinations, and prompts using tools like LangSmith or WhyLabs for LLM monitoring.
[Explore More In The Post]
Good GenAI apps aren’t just about prompts, they’re engineered for performance, adaptability, and scale.
Generative AI is not magic, it is math that creates.
From generating art and code to simulating human creativity, every GenAI model works differently, but with one shared goal: creation from data.
Here is a simple breakdown of the five major types of Generative AI models shaping today’s AI revolution 👇
1. Diffusion Models
Learn by adding and removing noise from data to create realistic outputs.
Used in image and art generation tools like DALL·E 3, Stable Diffusion, and Midjourney.
2. GANs (Generative Adversarial Networks)
Use two neural networks - a generator and a discriminator, that compete to produce lifelike data.
Power deepfake videos, face synthesis, and AI art.
3. Variational Autoencoders (VAEs)
Compress data into a compact representation and decode it to generate new versions.
Used in image reconstruction, anomaly detection, and creative design.
4. Autoregressive Models
Predict the next word, note, or pixel based on previous ones in a sequence.
Used in text generation, music composition, and time-series forecasting.
5. Transformers
Use self-attention to understand relationships across sequences for highly contextual generation.
Power modern AI systems like GPT, Claude, and Gemini for text, code, and image generation.
Generative AI Is Redefining Creativity
Each model type brings a new layer of intelligence, from reasoning to imagination.
Learn how these models work, and you’ll understand the core of AI’s creative power.
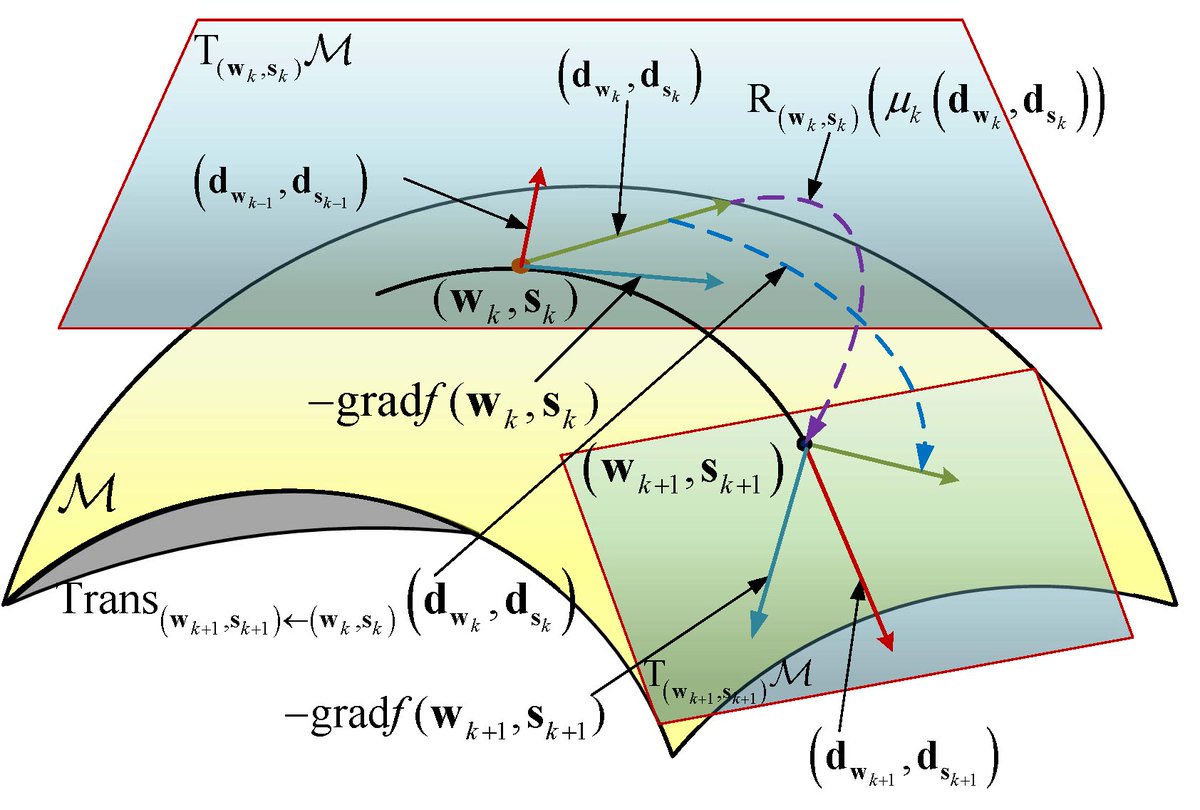
Riemannian optimization solves problems where variables live on curved spaces, not flat Euclidean ones. By using geodesics and manifold geometry, it enables efficient search on spheres, rotation groups, and low-rank manifolds. In probability, it aids covariance estimation and directional data. In ML, it powers word embeddings, matrix factorizations, and optimization on orthogonal or low-dimensional manifolds. In real life, it appears in robotics, graphics, and navigation tasks involving orientation.
Image: https://t.co/NcSuk9i83r
Build a Large Language Model from scratch!
This repository contains the code examples for developing, pretraining, and finetuning a LLM from scratch.
It is the official codebase for the book Build a Large Language Model (From Scratch).
Notebook examples are included for each chapter:
Chapter 1: Understanding Large Language Models
Chapter 2: Working with Text Data
Chapter 3: Coding Attention Mechanisms
Chapter 4: Implementing a GPT Model from Scratch
Chapter 5: Pretraining on Unlabeled Data
Chapter 6: Finetuning for Text Classification
Chapter 7: Finetuning to Follow Instructions
Link to the repo in the comments!
How to build a RAG app on AWS!
The visual below shows the exact flow of how a simple RAG system works inside AWS, using services you already know.
At its core, RAG is a two-stage pattern:
- Ingestion (prepare knowledge)
- Querying (use knowledge)
Below is how each stage works in practice.
> Ingestion: Turning raw data into searchable knowledge
- Your documents live in S3 or any internal data source.
- Whenever something new is added, a Lambda ingestion function kicks in.
- It cleans, processes, and chunks the file into smaller units that the model can understand.
- Each chunk is embedded using Bedrock Titan Embeddings.
- The embeddings are stored in a vector database like OpenSearch Serverless, DynamoDB, or Aurora.
- This becomes your searchable knowledge store.
This stage can run continuously in the background, keeping your knowledge fresh.
That said, you need to be strategic about how you reindex your data.
For instance, if you are fetching data from a document and only one character was updated in it, you don’t want to reprocess the entire document every time.
So smart diffing, incremental updates, and metadata checks become important to avoid unnecessary cost and keep ingestion efficient.
> Querying: Retrieving and generating answers:
- A user asks a question through the app.
- The request flows through API Gateway into a Lambda query function.
- The question is embedded with Bedrock Titan Embeddings.
- That embedding is matched against your vector database to fetch the most relevant chunks.
- Those chunks are passed to a Bedrock LLM (Claude or OpenAI) to craft the final answer.
- The response travels back to the user through the same API path.
This pattern ensures the LLM is grounded in your actual data, not model guesses.
This setup is the most basic form of RAG on AWS, but the pattern stays the same even as your system grows.
You can add better chunking, smarter retrieval, caching layers, orchestration, streaming responses, eval pipelines, or multi-source ingestion, and the architecture still holds.
I have shared a visual that depicts 8 RAG architectures in the replies!
Also, the visual in this tweet on building a RAG app on AWS is inspired by ByteByteGo's post on a similar topic. I added more context to it for explainability.






























![goyalshaliniuk's tweet photo. Building a GenAI app?
Don’t just plug in a model - design it to scale, adapt, and evolve.
Here’s your blueprint for future-ready GenAI systems. 👇
1. Modular Architecture
Separate UI, orchestration, models, and storage to swap parts independently. Use LangChain or LlamaIndex to build pipelines.
2. Context Engineering
Layer system prompts, memory, and retrieved knowledge to optimize generation. Use chunking and summarization to stay efficient.
3. Retrieval-Augmented Generation (RAG)
Connect vector DBs like Pinecone or Weaviate and use hybrid search (dense + keyword) for domain-specific relevance.
4. Low-Latency Design
Cut load times and delay using model distillation, quantization, and async I/O.
5. Agent-Based Systems
Use CrewAI, AutoGen, or LangGraph for task decomposition and tool execution via specialized sub-agents.
6. Tool & Plugin Integration
Enable LLMs to run code, hit APIs, or use external tools through OpenAI function-calling or LangChain routing.
7. Streaming & Feedback
Improve experience with real-time streaming via WebSockets and user feedback for continuous refinement.
8. Memory Management
Support both session and long-term memory using Redis, Postgres, or vector DBs for persistence.
9. Smart Deployment
Use K8s or serverless runtimes (like AWS Lambda) to deploy GenAI apps with dynamic scaling.
10. Observability
Track usage, hallucinations, and prompts using tools like LangSmith or WhyLabs for LLM monitoring.
[Explore More In The Post]
Good GenAI apps aren’t just about prompts, they’re engineered for performance, adaptability, and scale.](https://pbs.twimg.com/media/G7BlGkobMAA_nBd.jpg)