Together with @AlexSmechov, we are releasing Opir: an efficient family of multi-task safety classification models for toxicity, jailbreaks, hate speech, and harmful content.
https://t.co/Fo2apovAMG
For a deep dive into the data collection and generation methodology, benchmark results, model architecture, and taxonomy, check out the paper:
https://t.co/Jp6eNiOS4z
We are excited to share our new paper:
“GLiNER-Relex: A Unified Framework for Joint Named Entity Recognition and Relation Extraction.”
https://t.co/rblN2vvnsH
Relation extraction is becoming increasingly important as GraphRAG, knowledge graph construction, and agentic memory systems emerge. We believe GLiNER-Relex can become a faster, more reliable, and flexible alternative for extracting structured knowledge from unstructured text.
🌍 Meet SoTA Multilingual Classification Models at 140k tokens/s
We’re excited to release a new line of GLiClass models focused on the combination that matters most in practice: strong multilingual performance, zero-shot flexibility, and high inference efficiency.
We optimized the model implementation, introduced a new scoring mechanism, and improved our synthetic data generation approaches. All of it allowed us to achieve results better than those of all cross-encoders and GLiNER-based models we tested so far, while being many times faster.
This release includes 3 models with 100M, 300M, and 1.7B parameters, enabling them to run from mobile devices to production jobs on GPU machines.
The models were explicitly fine-tuned on 20 languages and can generalize beyond them, thanks to encoders pre-trained on 100+ languages. The model has strong cross-lingual abilities, meaning that your labels and input text can be in completely different languages.
On modern GPU hardware, our base model reaches up to 140k tokens/sec throughput, and remains highly efficient across larger label sets thanks to our single-pass classification architecture.
In addition to topic classification, the models support safety classification, sentiment analysis, and intent classification.
🔗 Find all models @huggingface : https://t.co/Bn951252Go
@Pranav2278 Thanks for your interest in GLiClass. It was introduced in 2024 with a focus on sequence classification. The package supports various pooling and scoring strategies. Additionally, GLiClass implements various training strategies, including PPO-inspired ones.
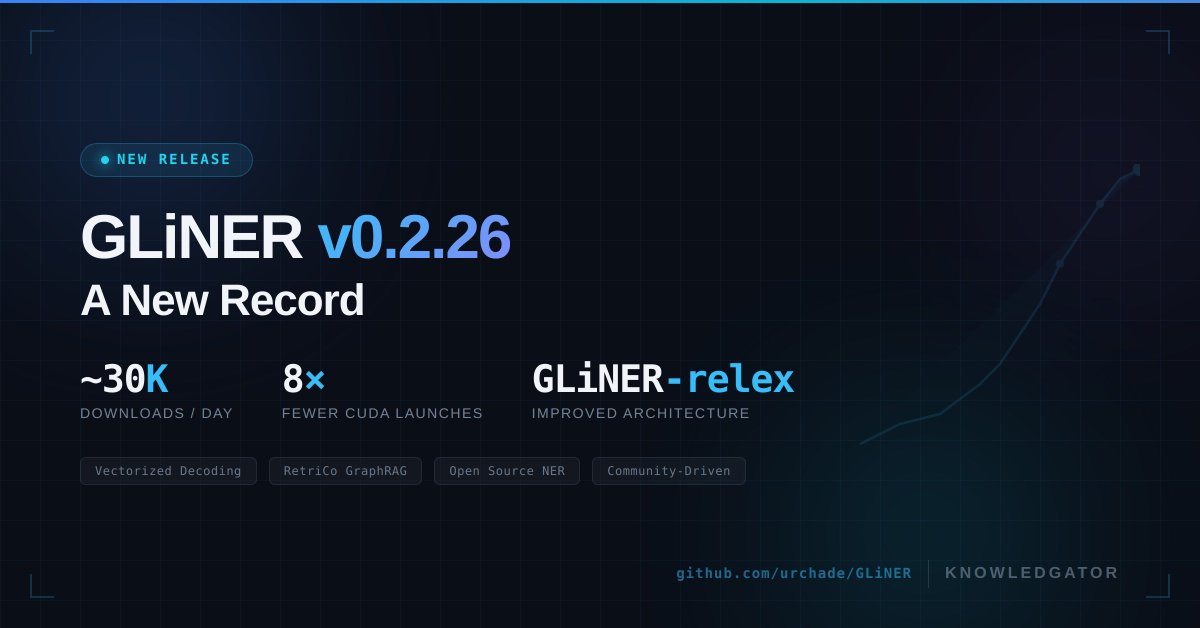
GLiNER just hit a new record 🚀
We just released a new version of the package, and GLiNER reached almost 30k downloads per day. I couldn't be prouder of this milestone and the community behind it.
This release is packed with meaningful improvements: Performance wins
▪️ Vectorized CPU-path preprocessing and decoding hot loops
▪️ Vectorized relation decoding, replacing costly .item() calls with torch.where
▪️ Batch-level span decoding — reducing CUDA kernel launches from B*8 to ~8
Architecture & quality:
▪️ Restructured repo and updated documentation
▪️ Improved GLiNER-relex architecture and decoding
A huge thank you to @MaxWBuckley for inference optimizations. Vivek for building an evaluation pipeline for new relation extraction models, Bryan Bradfo for improving documentation, and @urchadeDS for his review. Every single contribution matters.
These improvements unlocked something bigger; we built RetriCo, a super-efficient GraphRAG system powered by the new GLiNER-relex models.
For us at @knowledgator , open source is how we build technologies. It's how we collaborate with developers worldwide. It's what makes our work meaningful. We believe open information extraction technologies are essential for decentralizing power in AI. The tools for understanding and structuring the world's knowledge shouldn't be locked behind closed doors.
Come build with us:
🔗 GLiNER: https://t.co/OlhEALt5pw
🔗 RetriCo: https://t.co/WT8JqjIl99
🔗 GLiNER Community: https://t.co/tPTeN2SjYx
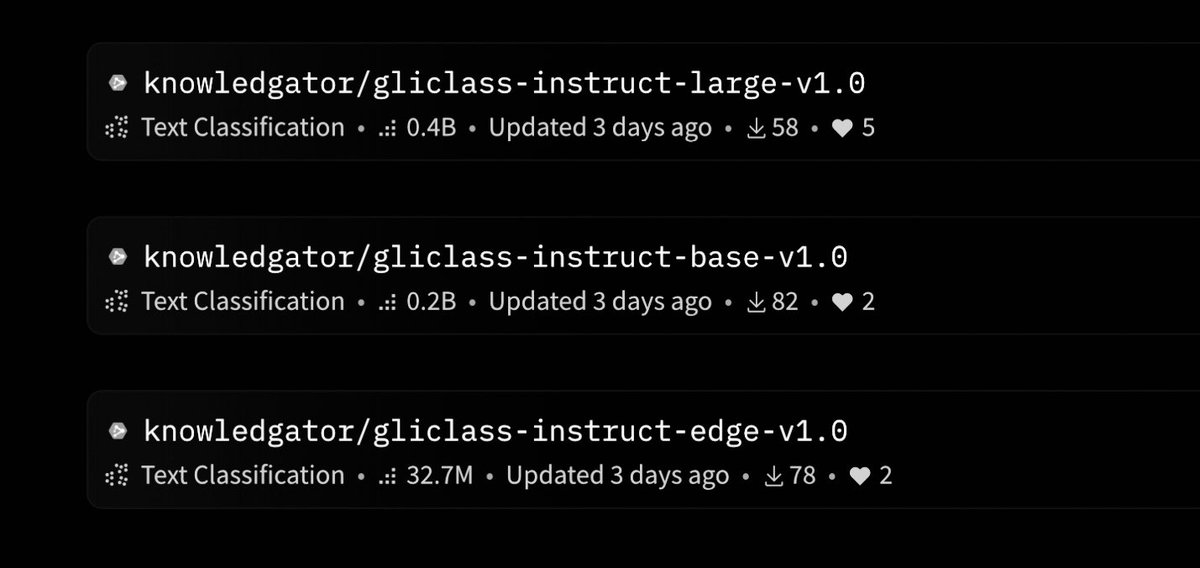
Building on GLiClass-V3, GLiClass-Instruct extends the encoder-first backbone with instruction conditioning for real zero-shot workflows. The architecture remains the same, but adds hierarchical labels, few-shot examples, label descriptions, and task prompts to control behavior without fine-tuning. Latency stays stable as taxonomies scale, and V3 maintains ~0.72 average zero-shot F1 (large) while preserving the throughput advantages of the underlying design, positioning it as infrastructure for large-taxonomy classification and guardrail workloads.
🧠 One lightweight model to classify, verify, and guard — introducing GLiClass-Instruct
GLiClass started as a fast zero-shot topic classifier rivaling cross-encoders at a fraction of the cost.
But topic classification wasn’t enough.
Today we’re launching GLiClass-Instruct: a multitask model that can handle various tasks via sequence classification.
✨ What’s new
• Hierarchical labeling for complex taxonomies
• Few-shot in-context learning (no fine-tuning)
• Natural language prompting for task control
• EWC to add skills without forgetting old ones
• 3× faster inference with FlashDeBERTa
🚀 New multi-task capabilities
Beyond topic + sentiment classification, GLiClass-Instruct now supports:
• Hallucination detection (is an answer grounded in context?)
• Rule-following verification (does content follow your guidelines?)
• Safety classification (prompt injections, jailbreaks, harmful requests)
These are key building blocks for agents, RAG pipelines, and LLM guardrails, where every input/output must be screened and verified at minimal latency.
🔗 GitHub: https://t.co/CBFlGtWBuN
🤗 Models: https://t.co/0njvJMfMeK
🌍 More: https://t.co/csn2Jnc3qD
🚀 Exciting news: GLiNER meets Transformers v5!
We’ve just released a new version of GLiNER, packed with major updates and improvements:
▪️ Transformers v5 support — fully compatible with the latest Hugging Face Transformers updates.
▪️ Improved FlashDeBERTa integration — train GLiNER much faster and handle longer sequences more efficiently.
▪️ New architecture types — introducing an advanced token-level subarchitecture that enables recognition of spans of any length. This was a game changer for our entity linking models. The new token-level type works for both uni-encoder and bi-encoder setups.
▪️ Span-constrained prediction — you can now provide input spans, ensuring GLiNER predictions are always constrained to them. This enables chaining multiple GLiNER models for more weighted and controllable results.
▪️ Plus several smaller fixes and improvements.
📦 Upgrade now:
pip install gliner -U
🔗 Resources:
• Entity Linking models: https://t.co/ODo0kbe3Ki
• Entity Linking framework (GLinker): https://t.co/fflcAxTpKb
• GLiNER repository: https://t.co/RKlhYqbswl
🙏 Huge thanks to all contributors, especially @bioMikeee for fixing bugs, @tomaarsen for helping navigate the Transformers v5 update, and @urchadeDS for the review of changes.
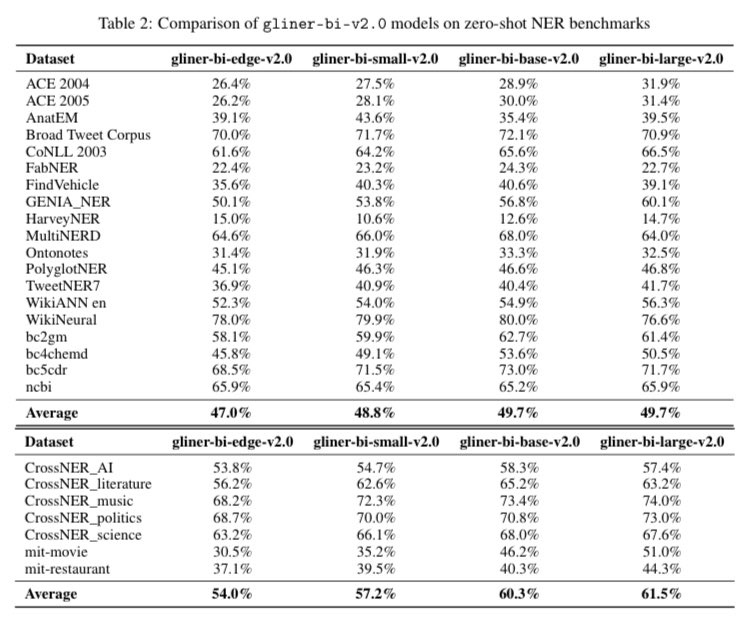
A solid release from Knowledgator: GLiNER-bi-V2, a bi-encoder upgrade to GLiNER for zero-shot NER.
Core change vs original GLiNER: the bi-encoder decouples text encoding from label encoding, so you can precompute/cache label embeddings and score against 1k+ entity types with near-constant inference cost (and constant text-encode memory regardless of label count).
Stack: ModernBERT-based text encoder (Ettin) + sentence-transformer/BGE label encoder, with optional cross-attn fusion.
The value is system-level efficiency: cheaper scaling, faster taxonomy iteration, and realistic million-entity linking via GLiNKER to Wikidata-scale KBs.
Numbers: 61.5 Micro-F1 (CrossNER, zero-shot) and up to 130× throughput at 1024 labels with precomputed embeddings. The 194M base reaches ~98% of the large model’s accuracy at ~2.6× higher throughput; Large adds ~+1.2 F1 at ~2–3× lower throughput.