LOAD BALANCING: Day 1/25
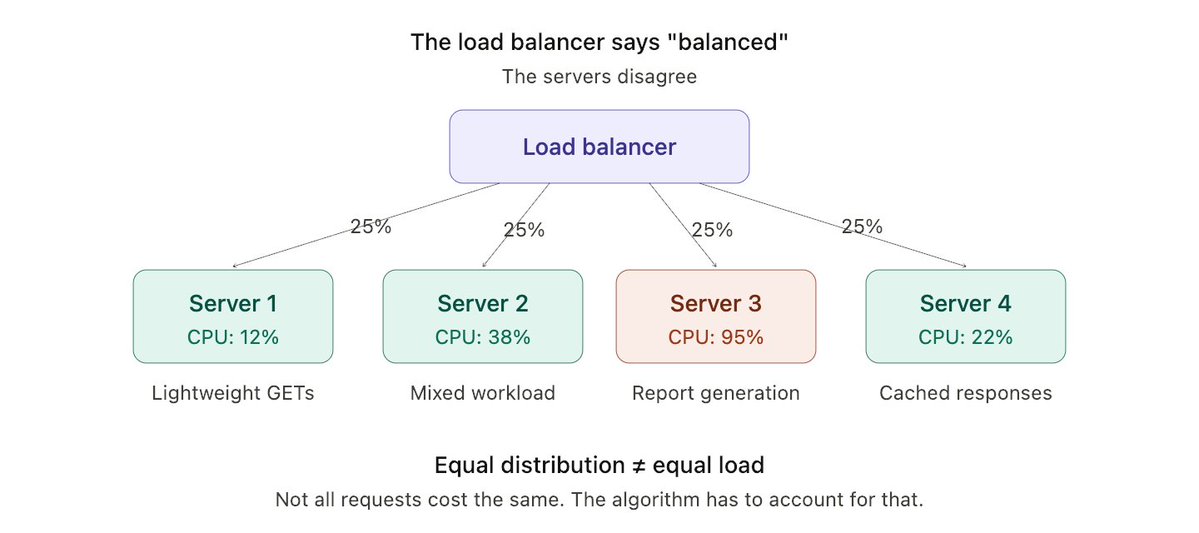
Your load balancer is lying to you.
It says traffic is "balanced." What it really means is: requests are being distributed. Whether they're distributed well is a completely different question.
I've seen a system with 4 servers where Server 3 was at 95% CPU while Server 1 sat at 12%. The load balancer said everything was fine.
A load balancer doesn't know what's happening inside your servers. It doesn't know one request takes 2ms and the next takes 12 seconds.
Your choice of algorithm, layer, and health check strategy is the difference between actual balance and the illusion of it.
Let me break it down. 🧵Your load balancer is lying to you.
New article: a visual tour of recent LLM architecture advances, from Gemma 4 to DeepSeek V4.
I focus on long-context efficiency tweaks like KV sharing, per-layer embeddings, layer-wise attention budgets, compressed attention, and mHC.
Link: https://t.co/KO81y3kTH7
We finally know why LLMs hallucinate. It's not the model. It's the geometry.
@OpenAI text-embedding-3-large: 91/3072 dimensions do real work.
@GeminiApp gemini-embedding-001: 80/3072 dimensions do real work.
~97% of your vector database is mathematically empty. Your RAG system is retrieving from noise.
@ashwingop and I present "The Geometry of Consolidation" - a proof that RAG compression has a hard floor no algorithm can beat, set by a single spectral number your embedding model cannot escape.
Every hallucination your RAG pipeline produces? This is why.
Paper + results: https://t.co/zut8pdoPbH
Introducing SubQ - a major breakthrough in LLM intelligence.
It is the first model built on a fully sub-quadratic sparse-attention architecture (SSA),
And the first frontier model with a 12 million token context window which is:
- 52x faster than FlashAttention at 1MM tokens
- Less than 5% the cost of Opus
Transformer-based LLMs waste compute by processing every possible relationship between words (standard attention).
Only a small fraction actually matter.
@subquadratic finds and focuses only on the ones that do.
That's nearly 1,000x less compute and a new way for LLMs to scale.
The Top AI Papers of the Week (April 19 - 26)
- Skill-RAG
- DeepSeek V4
- Autogenesis
- Attention to Mamba
- Stateless Decision Memory
- Self-Evolving Logic Synthesis
- Self-Generated World Knowledge
Read on for more:
Everyone is sleeping on this new OCR model!
- 85.9% (sota) on olmocr bench
- 90+ language support w/benchmarks
- 4B model (down from 9B)
- Full layout information
- Extracts + captions images and diagrams
- Strong handwriting, math, form, table support
100% open-source.
Stanford just released a 1.5-hour lecture on “LLM Architecture.”
This is the exact thing systems engineers at Anthropic and OpenAI require to understand at a deep level.
Give it some time.
This might be the highest-ROI learning you do this month.
Ex-MIT researcher Isaak Freeman quits his PhD and drops the 50,000 H100 GPU roadmap to emulate a full human brain.
He mapped the entire path from 302-neuron worm to 86-billion-neuron human with connectomics costs now at 100 dollars per neuron and data acquisition via advanced microscopes as the only blocker left - digital humans just got a realistic timeline.
https://t.co/kGB5hOAQHC
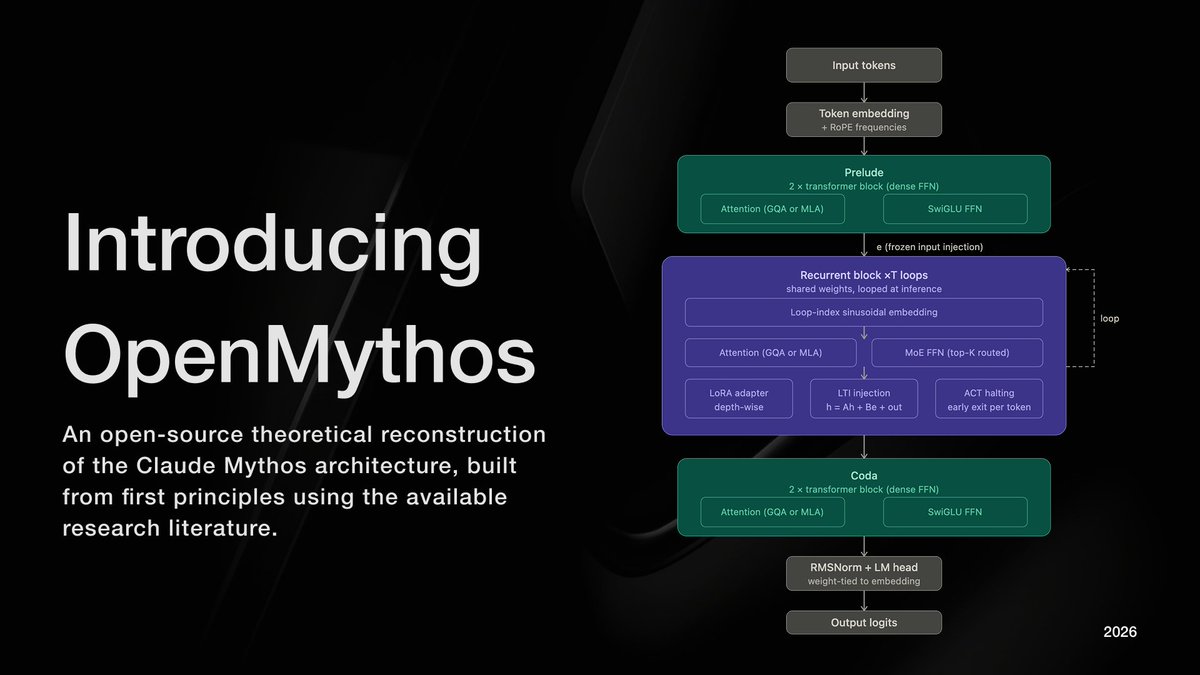
Introducing OpenMythos
An open-source, first-principles theoretical reconstruction of Claude Mythos, implemented in PyTorch.
The architecture instantiates a looped transformer with a Mixture-of-Experts (MoE) routing mechanism, enabling iterative depth via weight sharing and conditional computation across experts.
My implementation explores the hypothesis that recursive application of a fixed parameterized block, coupled with sparse expert activation, can yield improved efficiency–performance tradeoffs and emergent multi-step reasoning.
Learn more ⬇️🧵
Anthropic Fellows program: "Cross-Architecture Model Diffing with Crosscoders" unsupervised discovery.
Full paper: https://t.co/NWWC4ratcz found cool stuff like CCP alignment features in Qwen models, American exceptionalism in Llama, and more.
New Anthropic Fellows Research: a new method for surfacing behavioral differences between AI models.
We apply the “diff” principle from software development to compare open-weight AI models and identify features unique to each.
Read more: https://t.co/VAsu2PSgCX





































![KirkDBorne's tweet photo. [Download 585-page PDF eBook]
Game Theory: https://t.co/8NySL3GFmu
—————
#GameTheory #Gamification #Mathematics #Statistics #Probability https://t.co/OgBrQ0EitZ](https://pbs.twimg.com/media/HEJXSntbkAAB_eK.jpg)




















