Pulled the trigger today and switched 100% of Lindy traffic to DeepSeek v4, churning from Anthropic models.
Saves us millions of $ and we're actually seeing an *increase* in performance on many core use cases. Transformative for the business.
Krisp - it's not cool to lose my call recordings. And support experience made it even worse. That's not a way to treat paying customers. @krispHQ@davitb
How do we automate business analytics with Claude?
New blog post covering our best practices for skills, data foundations, and evaluations when building agents to perform data analysis:
https://t.co/mfEJMAQFBU
Workflows are the biggest upgrade to Claude Code’s capabilities since skills and subagents.
I dove deep into it with @sidbid to figure out best practices, examples and more. I’m particularly excited about the non-technical tasks it enables for Claude Code.
been asking others at Anthropic how they stay in the loop with Claude and fully understand the work being done
this is one of my favorites from Suzanne:
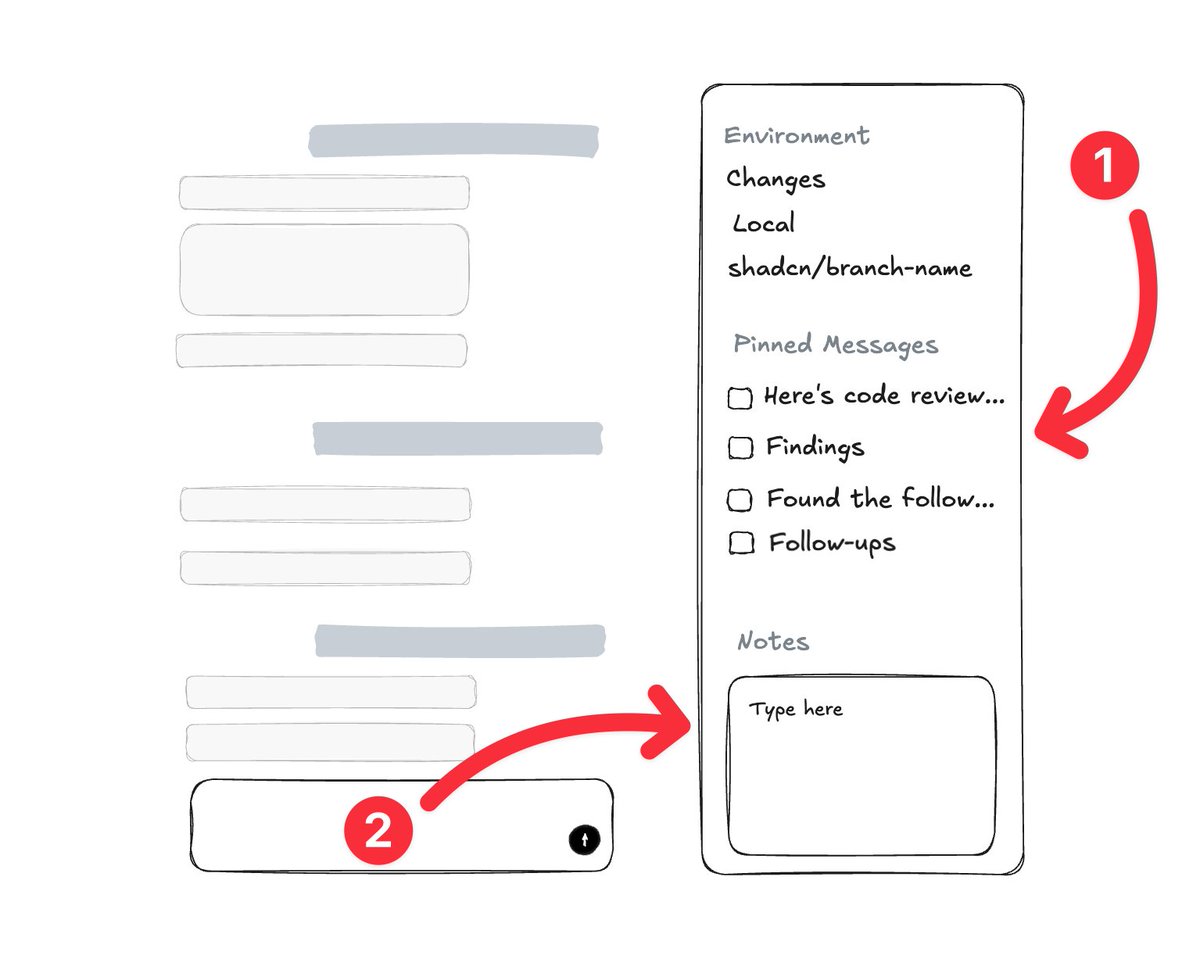
I want the following in Codex, Cursor, and OpenCode...
1. Pinned Messages: Let me pin assistant messages to the sidebar for things I want to keep track of but am not ready to address yet. Render as a checklist & jump navigation.
2. Notes: Give me a scratchpad for thoughts while working.
I do this with codex all the time. Ask it to review code for bugs and it will tell you all good, tell it there is a bug and it will LOOP AND LOOP and will find issues.
AI Blueprints is an 8-part field guide for leaders trying to ship AI.
This is Part 6: What Will Go Wrong
Short version:
*Before you start:*
- GDPR + EU AI Act: feeding customer data into cloud AI = third-party processing obligations. high-risk use cases (HR, credit, insurance) have specific requirements. non-compliance = fines up to €35M / 7% revenue. legal team involved from day one, not after launch.
- Vendor lock-in: data format, integration points, workflow dependency, knowledge lock-in. switching cost grows over time. after 18 months, practically impossible without rebuilding. own your data pipeline independently of the vendor. negotiate exit terms before you sign, not when you need to leave
*During POC and build:*
- Hallucinations: AI will state false things with complete confidence. will cite docs that don't exist, combine facts into fabricated "facts." during POC this is a measurement — how often, how badly, is it tolerable for this use case. in production this reaches customers and creates liability. any vendor claiming "we've solved hallucination" is the single most reliable red flag in the market
- Accuracy plateau:
0→80% is fast and cheap.
80→90% costs as much again.
90→95% costs as much as everything before combined.
95→99% may not be achievable.
Know where your use case sits on this curve BEFORE committing production budget.
- Employee resistance. they see AI as threat to jobs/expertise/status. address during design, not after launch. involve end users in evaluation, let them set the bar, address the job question directly and honestly. first visible error after launch destroys trust, usage drops, project becomes political — by then it's a death spiral, not a fixable problem
- Talent gap: you need ongoing AI expertise permanently. plan this into the build phase, not as an afterthought post-launch. "build it and hand it to IT" doesn't work.
*In production:*
- Production failures: gradual quality degradation nobody notices until users complain, catastrophic edge cases (offensive content, data leaks), dependency failures (API down, model deprecated). need monitoring baseline defined before launch and a response process for when things break. if you don't know what "healthy" looks like, you won't notice when it gets sick
*Meta-risk:*
- Doing nothing disguised as doing something. the organization runs a pilot, declares partial success, presents it to the board, and then... nothing scales. no production deployment. no real value delivered. but the checkbox is checked. "we're doing AI." this is the most common outcome and the most dangerous because nobody calls it a failure. it quietly consumes budget and opportunity cost while the organization believes it's making progress. the entire playbook exists to prevent this
AI coding made everyone a builder. The number of engineers stayed the same.
Shipping a demo is easy. Making it survive real users, real data, and real edge cases never was.
introducing howtoeval dot com. the no-bullshit guide to eval'ing AI agents.
from personal experience, and from working with the best companies in the world.
there's even a quiz. link below.
AI Blueprints is an 8-part field guide for leaders trying to ship AI.
This is Part 5: Budgeting for AI
Short version:
- AI costs behave like R&D, not software procurement. More variable, less predictable, with invisible categories that appear after you're committed
- Every estimate is wrong by 3-5x. Data uncertainty, model uncertainty, and integration surprises are genuinely unknowable upfront
- Multiplier rule: take the AI component estimate, 2x for data prep, +50% for integration, +30% for surprises
- Where the money actually goes, as percentage of total budget:
(1) API/model costs 5-10%
(2) data preparation 40-60%
(3) application development and integration 20-30%
(4) ongoing operations 20-30% of initial build cost annually
The thing that looks like the AI project — the model, the API — is the cheapest part.
- Your cheapest budgeting tool is the data audit from section 3 and the POC from section 4. Spend 10-15% of your expected budget on those upfront, and you convert unknowable costs into known costs before committing real money.
- Pricing traps - these are mechanisms, not specific numbers, because they'll hit you at any scale:
(1) per-token pricing cheap at POC volume / brutal at production volume
(2) year-one discount / year-two real pricing (get year-two in writing)
(3) implementation fees that grow via change requests (get a fixed cap or very detailed scope)
(4) hidden infrastructure dependencies that appear nowhere in the vendor proposal
"Let's discuss pricing based on your needs" means pricing based on how much they think you'll pay
- ROI: don't calculate ROI on "AI" — calculate on the specific outcome. "save 4 FTE of manual review" is a business case. "be more innovative" is not. Breakeven timeline matters more than total ROI. Calculate "what if we don't" — the cost of continuing the manual process often makes a stronger case than the AI ROI itself
- Present ranges, not single numbers. It's more honest and more credible. Phase the budget with go/no-go gates. State assumptions explicitly ("this assumes CRM has an API — if not, add 15-20% to integration")
AI Blueprints is an 8-part field guide for leaders trying to ship AI.
This is Part 4: The POC Trap
Short version:
- POC should answer "should we invest?", instead most answer "can this technology produce an impressive output?" completely different questions.
- Anatomy of a dishonest POC:
(1) vendor-curated data
(2) vague success criteria
(3) evaluated by the people who built it
(4) edge cases excluded
(5) scale untested
(6) integration mocked
- The FOMO trial: company sees competitors "doing AI," vendor offers a free or cheap pilot, they jump in without a clear business question. The trial generates activity and excitement but no learning. It creates the feeling of progress ("we're piloting AI!") which actually delays real AI enablement.
- Every demo handles the easy 70%. the hard 30% is "next phase." but that 30% is where the real cost, errors, and user trust problems live
- Fixes:
(1) use your real messy data
(2) write specific success criteria BEFORE starting ("85% correct on 200 real queries, under 5% hallucination, judged by the person who does this today")
(3) define kill criteria too — what result means stop.
If you can't write these sentences, you're not ready for a POC
- Include adversarial testing. Give it to the skeptic on the team. Their evaluation is closer to reality than the project champion's
- Involve the people who actually do the work. From the START, in design, not just at the end for testing. operators and stakeholders know which edge cases actually matter, which steps are the real bottleneck, what "useful" means in their daily workflow.
- POC-to-production gaps:
(1) data goes from 1K to 500K docs
(2) users go from 5 friendly testers to 200 impatient employees
(3) errors go from "noted" to "reaching customers"
(4) integration goes from mocked to real
- The "partial success" trap: system works on 70% of cases, everyone declares success, assumes the remaining 30% will be closed in production. It won't.
AI Blueprints is an 8-part field guide for leaders trying to ship AI.
This is Part 3: Your Data Is Not Ready
Short version:
- Data prep IS the AI project.
Models are a commodity, APIs plug in easily. Your data is the variable that decides success or failure.
- Every company confuses "we have data" with "our data is usable by machines."
Humans read PDFs with context and institutional knowledge. AI takes everything literally.
- The four ways your data isn't ready:
(1) Format chaos. The same document type exists as PDF, Word, scanned image, email attachment. Each needs different processing.
(2) Structural mess. Your "customer type" field contains Enterprise, enterprise, Ent, Large, Type A, and blank. AI sees 6 categories.
(3) Tribal knowledge. The most valuable information lives in people's heads, not systems. Exactly what you'd want AI to learn, exactly what's not captured.
(4) Access nightmare. Data locked behind systems with no API, permissions set by someone who left, vendor platforms with export limits.
- The audit protocol. Do this BEFORE talking to any vendor:
(1) Pick ONE use case.
(2) Identify the exact data needed.
(3) Pull 100 records and look at them.
(4) Ask the person who knows this data best: "what's wrong with it?" – 20 minutes of their time saves weeks.
Walking into a vendor meeting knowing "our documents are 60% PDF, 30% scanned images, structured data has consistency issues" shifts the entire power dynamic.
- 60-80% of budget and timeline is data prep.
Vendors never mention this because it's your problem, not theirs.
- "Good enough" matters as much as "not good enough."
Perfectionism kills AI projects just like bad data does. Good enough means: consistently formatted, representative sample is pullable, a human reviewing it says "yeah, this is roughly right." You're aiming for consistent enough that the AI's mistakes come from AI limitations, not from garbage input. Stop cleaning, start building.
- Data prep doesn't end.
You're not cleaning a room – you're installing a cleaning system. New documents arrive, records change, formats evolve. The pipeline that prepares data is permanent infrastructure, not a project phase. This is an ongoing operational cost that belongs in the budget from day one.
- Start small.
One use case, one data source, get it clean, prove the concept. "Data lake first" = $2M and 18 months before any AI output.