"Every idea is a bad idea until all of a sudden it's a good idea. It's just who doesn't quit the soonest." Rebel's Emily Hosie on the mission statement that builds companies.
Here's a teaser of our Mac-1 model.
> 6.6B model
> runs locally (on any Mac)
> requires 7GB RAM (12GB ideal)
> can use 487 MacOS native tools
> perform multi-tool chained tasks
> reasoning: ON
> output: ~65 tok/s
We built a robust application layer around the model to make UI/UX MacOS native. The "model-focused" SaaS era is here.
Stay tuned for more.
Step-By-Step LLM Engineering Projects Roadmap
- Build a tokenizer
- Learn embeddings
- Implement RoPE / ALiBi
- Hand-wire attention
- Build MHA
- Build a Transformer block
- Train a mini-former
- Compare objectives
- Build sampling
- Speculative decoding
- KV cache
- MQA / GQA / MLA
- Long context
- FlashAttention
- Hardware budgets
- Toy MoE
- Sparse model trade-offs
- State-space / linear attention
- Diffusion language models
- Data pipelines
- Synthetic data
- Scaling laws
- SFT / DPO / RLHF / GRPO
- Quantization
- Serving stacks
- Eval harnesses
- RAG
- Tool use / agents
- Vision-language adapters
- Interpretability
- Red-team suite
- Full capstone model system
One request:
Choose an Opensource AI lab when you make it
Opensource is where humanity gets to keep the tools
DM me when you've made it ;)
Apple dropped a paper called "Embarrassingly Simple Self-Distillation Improves Code Generation" in April.
Their official repo runs on vLLM + Nvidia (makes sense for speed).
Not MLX on Apple Silicon.
So obviously I had to try the opposite. 💪 🧵
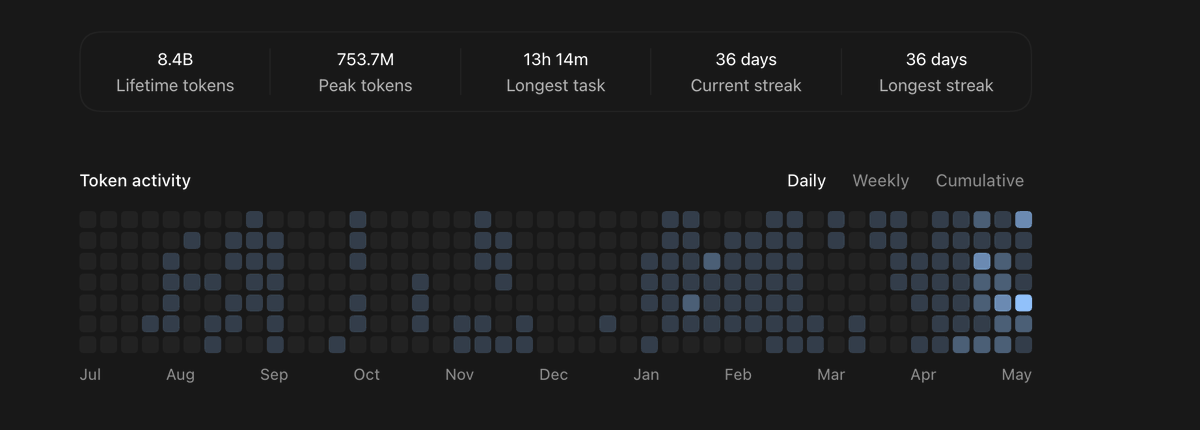
Switched primarily to Codex around end of April. 8.4B tokens 🫥. This is close to 20% of the tasks, we need more compute and tokens ( this is with maxing out Claude Code 20x as well) . Not even running openclaw or Hermes. Just coding , qa 😱
who knew lora would be the way we reach continual learning. It opened up customization in diffusion. Now it comes to llm, probably it is a starting point for what is next to come.
🏹5 Days of Trajectory.
Day 3 - An Open Source Training Stack for Continual Learning
Building the platform for continual learning requires both partnering with pioneering AI companies, as we showed on Day 2 with Harvey, and working toward frontier research, which we are highlighting today.
Continual learning means models that improve hourly from real production use. But with the size of frontier models, this becomes quite difficult. A Qwen-397b would need to spin up and tear down repeatedly across six GPU nodes, and that's valuable time gone.
Our contribution is Continual LoRA (C-LoRA): many lightweight adapters running at once on one shared base model. Our insight centers on where the parallelism lives: instead of splitting one giant job across nodes, we load-balance many small jobs over a single base.
The result: 2.81x experiment throughput over single-tenant training, with no regression on rewards.
We built this together, with @anyscalecompute, @NovaSkyAI, and generous support from @GoogleCloud and @GoogleStartups. We've open-sourced on SkyRL as one of the first multi-LoRA, RL training platforms, so that every team can get to continual learning faster.
We’re very excited to see what you build, please reach out!
We probably need a higher limit plan probably 50x or 100x, hitting limits on both codex 20x and claude 20x, only 5 days in. Ton more to do, not enough tokens 😅. Dreaming of the day, when there will be unlimited tokens and the bottleneck is us and our imagination. #codex #claudecode
using a good Skill, a CLI, and seeing Codex’s in-context-learning ability is a magical experience
point it to Harbor skills repo, Prime Intellect CLI, gave it an objective of what we wanted to RL and just watched it chug along figuring out the whole setup and debugging weird niche errors
us humans get the fun part of interpreting results, thinking through what’s happening, and deciding what to do next
agents training agents 🔥 humans guiding the process
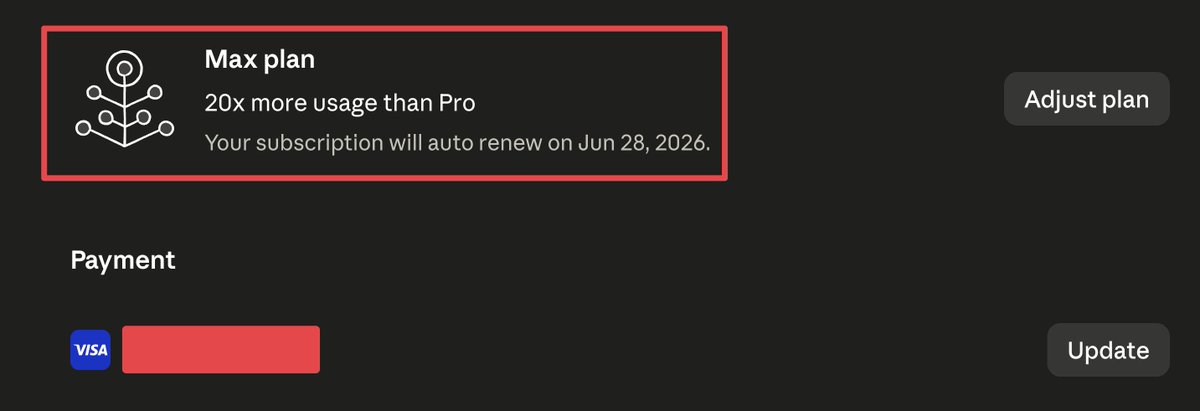
I just bought my 3rd $200 Claude Max 20x plan.
That's $600/month on Claude alone.
And it's the best money I spend.
UltraCode is insane.
Claude Opus 4.8 is better than GPT 5.5 in my honest opinion.
While everyone else cries about UltraCode burning their usage, I'm running all 3 plans in parallel as BridgeMind scales to $1M ARR.
Here's what people don't get.
I'm a real builder with a real SaaS.
I made over $50K in Stripe revenue the last 3 months.
$600 for unlimited frontier AI isn't an expense, it's the cheapest employee I'll ever hire.
Three Max plans means I never wait, never throttle, never stop shipping.
Cry about usage or go make money with it.
Your choice.
The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
If you work in the software industry and have time to read only one long-form post today, read this one.
If you have time to read two, read this one twice.
Highly #recommend
tl;dr: Stay off the yellow brick road that the frontier model companies are racing down. There is plenty of opportunity to solve hard problems elsewhere. Focus on areas where you can build the system of work (workflows), capture compounding, non-public data and deliver deterministic outcomes that customers need.
"you can outsource your thinking, but you can’t outsource your understanding"
easy to forget in todays AI era, worth remembering everyday as we all wield more intelligence!
Have been testing different versions of this , can attest quality of life have never been better and shipping speed have never been this better too.
Meta :
Codex app server / Claude code long lived token + VPS + remote control ( both codex and Claude ) + some secret sauce 😂🔥
a 28-year-old in Berlin runs a 7-agent software factory off a remote server
she approves checkpoints from her phone at midnight; her workspace has no desk, no city, no fixed machine - any screen is just a terminal
she quoted $28,000 for a scope a local agency priced at $74,000 and told the client 'minimum 6 weeks.' the agents shipped a validated PR in 19 hours
the agency was still revising their proposal
i've been running a version of this for the past few months. the setup sounds absurd until the first time it works, and then you can't go back
the factory lives on a remote VPS - always on, eight tmux panes, already mid-session. ssh in from whatever screen is nearby: laptop at home, phone on a train, tablet at a café at 1am. the environment never moves. you're just a terminal window connecting to something that was already running
agencies price the way they do because their overhead is structural. a $74,000 quote on a 6-week scope is real math: account managers, a senior dev who gets rotated to a bigger client by week three, revision cycles that exist because context lives in fourteen slack threads instead of one file
the factory collapses all of that into a CLAUDE.md
→ a 100-line markdown file at the repo root loads the entire project into every new agent session - stack, architectural rules, banned patterns - so no session starts blind and no context drifts between runs
→ agent one is read-only: maps the existing codebase, documents patterns, flags risks before any agent touches the code
→ agent two writes the user story and acceptance criteria, locking the exact definition of done before engineering starts
→ agent three produces the technical brief: data model changes, API shapes, a precise list of every file that will move - this locks before any builder runs
→ backend and frontend build in parallel but in isolation, each scoped to its own directories, so they can't reach across and corrupt each other's work
→ agent six writes acceptance tests against the original user story criteria before the implementation is considered complete
→ agent seven runs a final read-only audit: missing auth, tenant isolation gaps, any deviation from the brief gets flagged back into the loop before the pr is cut
→ three checkpoints pause the entire chain for human approval - story, spec, pre-merge - each one a 30-second phone tap when the upstream work was done right
the 19 hours is the output. what compressed was everything underneath: the pm relaying a question to an engineer who responds two days later, the architectural mistake that only surfaces after code is written, the context drift between sessions because the memory layer is a human brain instead of a file that loads before anything runs
the loop closes itself. validator flags a gap, builder fixes it, verifier confirms, pr is clean by morning
the agency sent their revised proposal at 9am. the pr had been merged for 14 hours
she approved the final checkpoint at midnight, 30 seconds on her phone. the agents were already done
the desk, the office, the fixed machine - she left them out
GPT IMAGE 2 is great , same with nano banana pro. Curious how long was the generation and what is the cost. Gpt usually takes close to a minute for an image and then costs close to 15 to 20 cents per image and even nano banana 2 is close to 8 cents per image.For a full site , isn’t it expensive. If any one has found a provider who provides amazing identity preserving vton and also really fast inference. Please hit me up.