Who's distilling from who now?
Query:
> 你是什么模型
> What model are you?
Sonnet Response:
> I am an AI assistant developed by *DeepSeek*, based on the *DeepSeek* model.
How can I help you? 😊
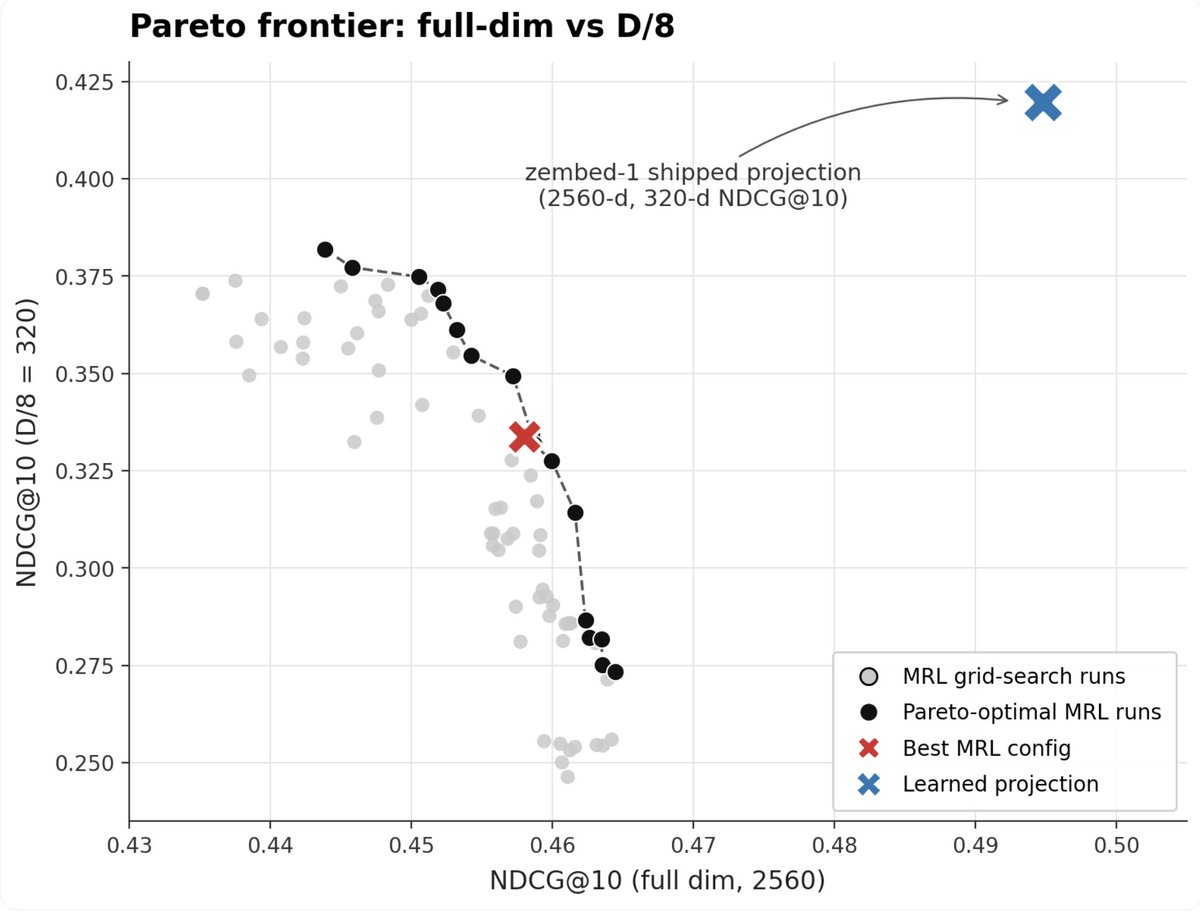
The full-dim win is the part that surprised me, but it makes sense once you think about what MRL is doing during training. Those prefix losses constrain the entire vector, not just the truncated end, so the encoder never gets to fully optimize for full dim. Pull that off and let a separate projection handle the truncation, and you get a better representation at every size.
Is Matryoshka dead?
Every frontier embedding model uses MRL.
But we tested it across a full hyperparameter sweep and it's lossy at every dimension.
A small projection matrix trained on top of zembed-1 beats MRL across the board. Including at full dim.
Results:
zembed-1 @ 160 dims > OpenAI @ 1536 dims
zembed-1 (no MRL) > voyage-4 (MRL)
@ZeroEntropy_AI
retrieval quality and context engineering are definitely the biggest bottlenecks. searching, compressing, and recalling are the last 20%, but the 80% of the effort to get right.
never doubt that a small focused team of engineers can beat the big labs
@ZeroEntropy_AI has been a core part of our architecture at @hyperspell since before we did yc
betting on them early was one of the best calls we made
My newest gbrain-evals just dropped - this is how gbrain does vs other options. https://t.co/yRWm72QEgf is SOTA for reranking and embedding cost, speed, and retrieval success.
GBrain beats MemPalace by 1% on LongMemEval and beats Vector RAG by 38%
https://t.co/nIk93HFTHb
Thank you @garrytan 🙏
None of this happens without @ycombinator believing in us early
Insanely proud of this team!
6 people shipping like 60 @ZeroEntropy_AI
A 6-person team is building task-specific AI models that are 4-8x faster than anything from OpenAI or Anthropic. 500K downloads on HuggingFace. No hype. Just better engineering winning on the merits.
This is what "make something people want" looks like in the model layer.
https://t.co/nsf8b31xha
zembed-1 is finally here!
🔥 The world's best embedding model, by @ZeroEntropy_AI
It outperforms @OpenAI , @GeminiApp , @Alibaba_Qwen , and Voyage's latest embeddings on 100+ languages, and across verticals.
Available now via our API/SDK, @huggingface, and @awscloud Marketplace.
Full launch post in the thread for benchmarks and more about our secret sauce 👀
We're building the entire retrieval stack... and we're just getting started.
🤫 PS: We're giving out free credits to try it, just comment on the post or DM me!
We are very excited to release zerank-2, @ZeroEntropy_AI 's newest reranker model. 🔥
It shows major improvement on the 5 most common RAG failure modes below.
Existing rerankers consistently fail on seemingly “simple” tasks:
🔢 Comparing numbers and date: “Biggest deals closed after 04/2024.”
🗄️ Aggregation: “Top 10 objections of customer X?”
🌍 Multilingual: Major pain point, especially non-English to non-English.
🙏 Instruction-Following: “Find the *counterargument* of the claim in the transcript”
🥇 Calibrated scores: You ask "what should I cook for dinner?", and "I am allergic to nuts" scores too low for your threshold.
Many rerankers overfit public benchmarks, and don’t generalize to these real issues. zerank-2 outperforms existing rerankers considerably on all of these failure modes, in real production environments.
With zerank-2, you get:
* 15% improvement vs Cohere rerank 3.5 on Arabic/Hindi (Miraql dataset)
* +12% NDCG@10 on sorting tasks (new open-sourced eval set)
* +7% vs Gemini Flash on instruction-following (MAIR dataset)
* $0.025/1M tokens, 150ms p90 latency at 100KB
🤗 We are open-sourcing the model weights, along with new challenging eval sets on @huggingface. Our Elo-inspired training methodology is already open-source!
We're starting a series of technical deep dives to explain various failure modes zerank-2 fixes, with concrete prod examples, methodologies, and benchmarks.
First technical deep dive in the comments.