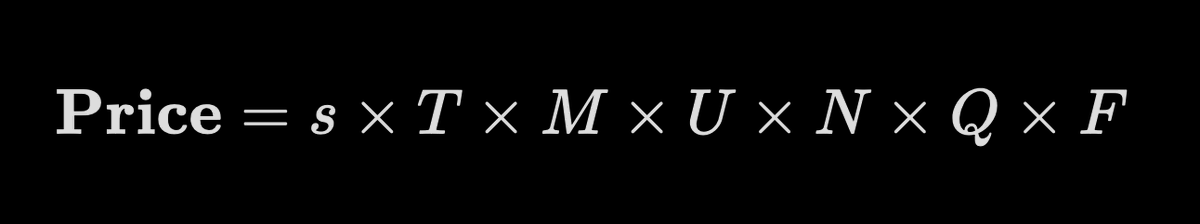1/ excited to announce COMPOSITE-STEM, a new benchmark of 70 scientific tasks sourced from experts on @PortexAI
Agents may soon assist in R&D, but evals are a critical step in building the trust needed to get there. We've open sourced this dataset to help advance agent evals ⤵️
6/ integration with harbor
All COMPOSITE-STEM tasks are fully harbor compliant.
Harbor is an open source agent eval framework developed by the team behind TerminalBench. We've natively integrated Harbor within the Portex Datalab.
https://t.co/neu4Uzq2Oj
@r0ck3t23 But RL environments are still data... bottleneck has just shifted to designing rubrics & evals for harder-to-verify tasks in knowledge work (law/finance) & frontier scientific research. You still need experts in the loop to define objective criteria for rewarding success.
Amazing couple days of conversations at the @PyTorch Conference in SF - very clear that evals & data sourced from subject-matter experts will play a critical role in advancing AI performance in economically valuable settings.
Day 2 of #PyTorchCon 🔥
What a ride. Talked with folks using #PyTorch to fine-tune models for drug discovery, cancer research, autonomous vehicles and, of course, customer support!
Thanks @PyTorch for having us!
IMO — Ilya is wrong
- Frontier LLMs are are trained on ~200 TBs of text
- There's ~200 Zettabytes of data out there
- That's about 1 billion times more data
- It doubles every 2 years
The problem is the data is private. Can't scrape it.
The problem is not data scarcity, it's data access.
The solution is attribution-based control (article below)
"Unlocking a Million Times More Data For AI"
8/ The lack of any reliable data valuation framework is a massive blocker to surfacing novel datasets for AI.
Auctions are remarkable engines for pricing non-alike goods. The data economy deserves the same foundation, and it’s worth building.
1/ AI isn't just a compute race anymore. It's a data race too. Labs are paying top dollar for differentiated, high-signal data.
It's clear now is the time to experiment with new approaches to valuing and incentivizing the creation of frontier AI data.
https://t.co/4MyJIRHGGY
AI has kicked off a gold rush for data, with OpenAI alone projecting $8B in data-related expenses by 2030.
The challenge now is finding a reliable way to value data in this era.
Our latest on data valuation techniques:
https://t.co/QJ3vpmf6tH
7/ We've also started exploring a data valuation framework with some of our early users on the Datalab. We're still refining it, but it takes into account a dataset's key features like uniqueness, quality, modality, freshness etc.
Noticing a trend?
Specialized models continue to beat foundation models on task performance, cost, and latency.
The emerging design pattern for agents is a foundation-model-brain that can invoke the most optimal tool for a given task.
GPT-4b micro is a model trained exclusively on specialized biological data.
It was used to reverse cellular aging with a 50x improvement in efficiency relative to previous approaches. A testament to the power of narrow AI + specialized data.
Amazing overview by @rowancheung: