If you have ever wanted to learn reverse engineering but had no idea where to start, this is probably the best free series out there.
Applied Reverse Engineering by @daaximus covers basic architecture, the stack, exceptions and interrupts, x64 assembly, control-flow tracing, and more still coming including hooking techniques, ROP, heuristic analysis, and C++ class reconstruction.
Written for people who have opened a debugger a handful of times and got lost. Starts from zero and actually makes sense.
https://t.co/Cu40nKRBg5
#ReverseEngineering #WindowsInternals #InfoSec
Yay for FILES! IMO this is really about ASCII more than file systems. Today's observations from computing history…
The original "binary" files—that is non-human readable, extensions of data structures—are rooted in constraints of limited storage up until the 1980s.
If you peruse Knuth volume 3 you will find a ton of wild algorithms that are hard to place—such as sorting with two tapes as shown below. That's because efficiently writing to permanent storage was an entirely different problem from efficiently reading (and rewriting or outputting) from it. The limits of RAM, disk/tape, and cache required data to be read/written basically when you had it. These algorithms were insanely complex and designed to avoid randomly accessing data.
Fast forward to the first word processors (and spreadsheets) and they were quite limited by RAM and disk space (and speed.) One of the cool innovations by Charles Simonyi at Xerox PARC was a memory/storage structure that essentially added a virtual memory subsystem tuned to the needs to maintaining runs of like-formatted text ("piece table".) This structure (and Charles) made its way into the original PC Word and then Mac and WinWord as the famous .DOC format.
This innovation enabled word processors of the day to "easily" work on files that could not fit in RAM, which was an obvious requirement. BTW, those who used the original 256K MacWrite quickly became familiar with what happened when exceeding the page limit (not pages per se but combination of formatting, text, and runs) and the sudden "eating" of your work late on Friday night. This led to a massive amount of engineering around seemingly trivial tasks such as how quickly could you page down in a document while reading the .DOC from disk and then rending on screen. A common "torture test" for a word processor was opening a large 100 page document and immediately CTL+END to see how quickly that could function, or CTL+HOME and then page down and seeing if display kept up with the scroll bars and the like.
Spreadsheets (XLS) were quite constrained to physical memory until DOS added "EMM" and later Windows virtual memory. The nature of recalc required the whole sheet to be resident. This limitation was frustrating for people using 1-2-3 as a spreadsheet. The original spreadsheets had *theoretical limits" of 256 columns (the origin of column "IV" in Excel) and 2048 rows—one single sheet, no tabs too. But if you had a lot of text like in a database you'd run out of memory long before that. Also the data structures were not particularly sparse until Microsoft spreadsheets came along. This was part of the reason the data structures were essentially the memory map of the spreadsheet.
These formats morphed into what some believed was an unfair competitive advantage for Word and Excel. Ironically (or more correctly free of malice), it was precisely because these were essentially in-memory representations of the applications that simply "converting" was not an option. Any conversion required a 1:1 mapping of not only the feature but the implementation of Word/Excel by the reader of files. That led to a sea of interchange formats such as RTF, BIFF (BIF) within XLS, and even for a while SGML.
The arrival of universal virtual memory as well as RAM that could hold the whole document led to an ability to simply read in the whole file and operate on it in memory. That in turn made it much less daunting to develop interchange formats based on ASCII and XML which could be used by default without sacrificing functionality. Still that led to challenges like where to store native images or embedded documents and so on, which only made these "files" more complex for people. In the end, this might have made it easier for machines but the hope of being human consumable was long lost.
BTW, everything above also applied to programs themselves. Prior to virtual memory the actual executable (for Word for example) was technically limited to available RAM (on a segmented 16 bit address space.) What I describe below was originally done for Fortran on IBM mainframes and the history of COMMON variables dates to this sort of memory/disk/code management.
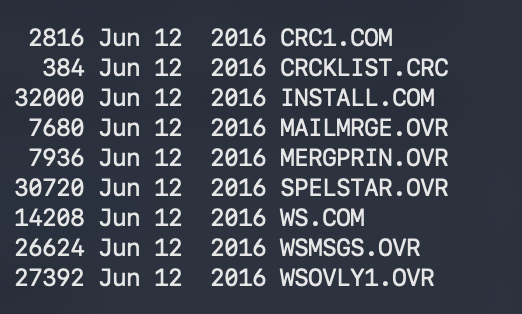
On 64K CP/M machines "overlays" became the tool used for most commercial software. An overlay is a *relocatable* chunk of code that could be read into memory as needed. So for example on WordStar on CP/M limited to 64K (but sold with as little as 16K) you can see https://t.co/q2J6DI9K0H under 16K and then assorted OVR or overlay files (OVL, OVR, or .00n files on disk). For example, when you invoked spell checking (no squiggles but a modal command) the overlay manager (code written by WordStar people) would read in SPELSTAR.OVR and load it with relocation into a part of RAM. After spelling it would get kicked out and maybe replaced with MAILMRGE for mail merge.) All of this was a manual effort in development and tons of work. The programmer had to basically keep track of what was where.
You could think of these overlays as a proprietary executable format not unlike .DOC, even if they were essentially yet-to-be-linked OBJ files.
As late as Office 4.x this process continued using proprietary tools and processes to work on the segmented 16bit architecture of Windows. This was viewed as a competitive advantage.
Even as late as Office 97 we had tools in development that would tune the code to provide better locality of code use so that we were not swapping out for basic tasks. A big reason for this was not only limited memory (there was something of virtual memory on 16 bit Windows) but the speed of using this swap file was low. As an example, using Word or Excel and invoking a rarely used command like mail merge or the complete Format Cell dialog you would often see a noticeable lag as that code was "paged" into memory. Picking the scenarios and sequences we swap tuned was a whole exercise for the team across development, testing, PM until we developed automated tools (a Microsoft Research project!)
So while it might be the age of files, particularly in ASCII, it is fun to look back and see why we did not have the age of files so much sooner. Of course Unix always had text files and virtual memory, but such was the luxury of expensive computing in commercial labs and academia :-)
"Microsoft LEGO" was one of the strangest and most secret optimizations we ever used at Microsoft, because it happened after the compiler was done, after the linker was done, after the .exe or .dll already existed, and in many cases after the developers themselves thought the build was finished.
And then, late at night, some secret internal tool would quietly take the binary apart, rearrange its organs, sew it back together, and ship something faster, smaller, and more memory-efficient than the program we had actually written.
And the best part is that almost nobody outside Microsoft knew it was happening. It’s been almost 30 years, but it’s time to tell you about it...
@othm_g@TaxAlphaInsider Wealth management is an industry that is a business that does not have skin in a game. No matter how much customer wins or loses, only wins are taken by wealth management but loses only client participate in.
There’s Never Been a Better Time to Study Computer Science: Even as AI progresses, coders aren’t doomed. https://t.co/jCEjfFzM26 // Never thought I'd see this here, but here it is.
The article asks and answers the question about the value of a CS degree. I think this isn't quite the right question. In fact we've been asking this since CS departments were created in the 1960s and 70s and evolving ever since. Is Computer Science a discipline to be studied independently or a tool used in every discipline, and what is the ratio between those two.
Many CS departments were rooted in math as much as electrical engineering. In the 1960s as many departments were formed the question was always about "affinity"—is CS closer to math or to electrical engineering. Many schools saw the affinity with EE and the major/department was even EECS and course requirements included taking the intro sequences of EE courses. Those students did stuff with wire and multimeters.
Where I went to school, Cornell, the department was somewhat conflicted and while it was physically housed in the Engineering Quad, students in the Arts & Sciences school could major in it. Engineering students ended up taking more physics and chemistry than Arts students, and graduates were BS or BA depending on what school they were from. Employers didn't care and we never talked about it. Our common requirements included more abstract theory than other EECS-rooted departments. Other fields like Physics had unique engineering disciplines such as Applied Engineering Physics with CS being unique among those cross-registered majors. Just a few years ago, Cornell created a stand alone "College of Computing" that straddles the entire university.
Meanwhile every single university department was "using" computers: Statistics, Physics, and more. At Cornell all the Agriculture majors and even the Hotel School took classes in BASIC or Fortran programming.
Universities have long used modifiers on majors to indicate they are "in between" such as Political Science or Food Science (is there a _science_ to politics? is food science a part of chemistry or culinary 'arts'?) To some this signified "soft" or "not really science" while to others this was a signal of interdisciplinary importance. The science modifier often indicates this "softness" of study. It isn't clear to me this has fundamentally changed after almost 60 years.
The rise of AI along with the more modern competitive nature of universities is causing a rush to create, new more marketable majors that include AI in the title. Universities move much faster now than they did with the rise of computing. When I was in school many programs were still figuring out what to do to have a computer science major and many (even) new computer science faculty were trained in EE or Math.
It isn't nearly as clear what these new majors mean as AI has rapidly diffused to every department. There's a legitimate question right now as to what knowledge is foundational versus tactical or transactional.
As the PC and productivity tools like Word and Excel rose—including programming tools like VB and Excel macros—the separation between using a computer and studying computer science became super clear. Taking courses in how to use a spreadsheet or word processor were abundant but not a major in college. Trade skills vs. foundational skills were clear. No one majored in spreadsheets, but you majored in Finance Business, or Economics and used a spreadsheet. No one majored in word processing, but you majored in English, Marketing, or History and used a word processor.
In the 1980s **the big question** about studying computer science was "what programming language to learn?" The brand new AP CS test used Pascal even as many departments were not yet teaching that and it was controversial. The field seemed defined by languages. The joke was if you earned a PhD then you probably created a new language. Most every research group developed a language. Writing a compiler was a rite of passage as was fighting over the "best" programming language. Think I'm kidding, this was one of the earliest USENET memes: "Real Programmers Don't Use Pascal" by the legendary Ed Post. I think just about every computer terminal room and grad student office had a line printer version of this posted. https://t.co/XBc5enMA1D
Departments hotly debated the choice of programming language and that choice came to define the rigor of a university. Pascal was good for teaching but no one used it in business where COBOL dominated and those building "systems" used C or those doing math used Fortran. If you got a specialized job in industry like building avionics you might use a language like JOVIAL or myriad others you would learn later at a company. It was also, importantly, viewed as the difference between studying "computer science" versus "computer programming." Science was a lifelong discipline. Programming was something like a trade-school skill.
My very first day of my very first class began with this very first statement from my professor (and later advisor), "In CS 100 you learn to program _into_ a language not _in_ a language." What he meant was we were learning the abstract skill of programming, not the bothersome syntax and paradigm of any single language. Thus my first programming language in school was not even the obscure language PL/1 (the union of Fortran and COBOL from IBM that mostly never took off) but an obscure research variant PL/CS that presumably made it more academic. When we complained about it not being practical, the department just said it didn't matter. I learned PL/1, Fortran, Ada, LISP, C, Pascal, ASM, and a half dozen other esoteric and forgotten languages, scripts, and libraries in the courses I took as well as COBOL during my internship. In addition we used at least a half dozen operating systems, a different one for each advanced course.
So today, this history is pretty important as the entire fields of "EECS" and programming are upended by AI. From 1980-2025 and even today, operating systems seemed to continue on the same path as all the textbooks and certainly whether you use Linux, Mac, Windows, iPhone, Android, or anything else you are using that foundation.
But architectures, processors, chips, networking, languages, even LLMs themselves are in an incredible state of flux. They are not improving on linear paths by any stretch. There are people inventing these new paradigms. Their knowledge and skills are rooted in computer science and EE. These skills are hardly going away. In fact the need for this foundational skill set is now greater than ever.
At the same time the rapid rise of LLMs and Agents has created an incredible demand for the skills to apply these tools/platforms to all the other work that goes on in society.
I double-majored in Chemistry. In the 1980s you didn't actually use a computer to major in chemistry, just goggles and test tubes. When you did use a computing device it was an embedded computer in a machine like a GC/MS. There was literally no programming done as a Chem major. That rapidly changed and in a few specialties—those closest to physics like molecular mechanics or physical chemistry—computing was rapidly becoming core. This was much like how Math was evolving.
AI is exactly like this today. I suspect that 2025 was the last year one could graduate college without a mandatory (implied or otherwise) use of AI, much like 1984 was the last year you could graduate college without using a word processor.
The question of this article is deep but also has an easy answer.
If you want to build the foundational tools for computing then become a computer science major where you'll be working on AI which will perfuse through the field the way programming languages did. If you want to apply AI to other fields then any course you take in those fields will use AI. And that use will look a lot like programming just as majoring in Math or Chemistry transitioned.
And most importantly, the specific AI model, user experience, features, and architecture will be wildly different 5, 10, 30 years into your career, whether you create the next foundation or just use it. I promise. Your major is not your lifelong toolset, but a lifelong foundation for learning.
I've been coding for 40 years. Here are the top 5 things I wish I knew when I started.
1. 90% of the job is debugging and fixing, not creating new code. Which is still fun if you're good at it.
I used to think programming was mostly writing fresh, clever stuff. In reality, most of your time is spent in other people's (or your own past self's) messy code, chasing down why something that "should" work doesn't. Get really good at debugging early. Learn assembly reading, call stacks, and kernel debuggers. It pays off hugely. The best engineers I saw were absolute magicians at this.
2. Manage complexity from day one (ie: don't write slop and "fix it later" if it goes somewhere).
Very early on, I'd hammer out code and refactor afterward. Big mistake. Now I start with clean, skeletal structure (minimalism first) and flesh it out carefully, with AI or not.
Messy code compounds and becomes unfixable. Upfront discipline on architecture, naming, and simplicity saves enormous pain later, especially in large systems like Windows.
3. Tools and processes matter more than you think
We suffered with basic diff/manual deltas instead of modern source control like Git. Branching, testing, and good tooling would have made porting and collaboration way smoother. Invest in your environment, automation, and reproducible builds early. Good tools amplify your output; bad ones (or none) drag everything down.
4. Understand the problem and existing code deeply before writing
Don't jump straight to coding. Map out the problem, study what's already there (you'll inherit a lot), and plan. Low-level knowledge (hardware quirks, alignment issues on different architectures like MIPS/Alpha) was crucial. Also: assert early and often. It forces clarity.
5. People, politics, and "the right tool for the job" beat pure tech arguments.
Brilliant engineers still argue endlessly. Sometimes it's about ego, not merit. Learn to spot the difference and "steer" the conversation rather than "winning" it.
Bonus from experience: Side projects like Task Manager (started at home because I wanted the tool) can become your biggest hits. Ship small, useful things often. If you're just starting, focus on fundamentals, patterns over syntax, and building resilience for the long haul. It's going to be a wild ride, but the fundamentals still matter.
@stevesi What about old office buildings which had offices on the inside? Converting to open spaces means everyone saw the window, even if just from distance
ESP32-S31 is officially released! 🚀 320MHz Dual-Core RISC-V, Wi-Fi 6, and even Gigabit Ethernet... but is it the right move for the next XIAO?
Don't let us guess—tell us! 👇 Read the full blog, join the Seeed Studio Open Roadmap and cast your vote:
https://t.co/O3R244rCAI
I'm writing a Dave's Garage episode on why new computers are slower than old ones (spoiler alert: it's the software).
After enjoying my obligatory photo of counting 6502 cycles like it was the olden days, let me know what you think is the biggest factor in why current code is so much slower than old code.
Here are my basic premises so far:
- We lost the hardware constraints that kept us honest
- No enforced CPU/RAM budgets, no daily benchmarks
- Abstractions without accounting for their costs
- Incentives shifted towards feature release speed
- Lowered perf standards, where "it works" is enough
- Dependency explosions in code
- AI is also a multiplier of mediocrity
What am I missing?