Next year probably. Plus we will have open source neural rendering models that take low poly simulators (being built and expanded 24/7) and provide super high quality customizable styles in real time. We will be vibe coding games and simulations that make current gen look like n64
@andreintg This is the future of all media. Simulations that run on traditional programming/data structures while rendering is handled by small AI models. This will be the future of of video games and interactive simulations, even TV like media
🚨 Kimi K2.7-Code is actually insane
>#1 on Program Bench
>#1 on MLS-Bench Lite (multi-step ML research)
>Refreshing to see honest benchmarks instead of cherry-picked
After claude fable debacle i want OSS to win FR to save us from dystopian end
The silence from Sam and Elon (and everyone else leading AI labs) on Anthropic tells you a lot.
When the Pentagon cracked down on Anthropic, the rest of the squad said "that's setting a bad precedent"
But their silence this time around means they're all watching a FAFO moment.
Never interrupt your enemy when he's making a mistake.
And make no mistake about it, anthropic is the enemy of humanity.
Happy now, @DarioAmodei? You got your wish for government regulation after constant fearmongering to slow AI progress.
@AnthropicAI has done tremendous damage to AI advancement; they succeeded in realizing this nightmare scenario. It’s a sad & grave day for America & humanity.
Let’s discuss the scaling law of virtual cells.
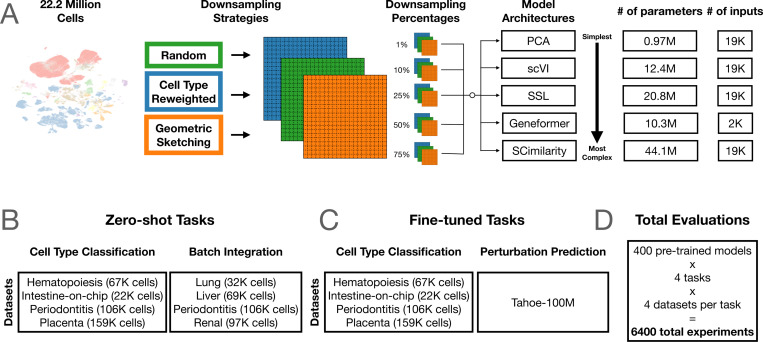
A Nature Methods paper (https://t.co/Sh4GYN0AK6) published yesterday is being interpreted by some as evidence that scaling laws do not hold for virtual cells. I read it in detail, and here are my 2 cents:
It is a useful benchmark, but not a direct test of scaling laws in causal single-cell foundation models or perturbation-native virtual cells.
The paper mainly studies PCA, scVI, Geneformer, and SCimilarity (which are relative small models) on observational atlas-style pretraining, with perturbation evaluation limited to a narrow Tahoe small-molecule/cancer-cell-line setting. These are important baselines on scFMs that focuses on learning cell embeddings, but they are not large-scale causal perturbation models (e.g, diffusion-based virtual cells, or other modern architectures designed natively for causal perturbation biology).
The metrics also matter. Cell-type F1 and batch-integration AvgBIO are reasonable atlas/embedding metrics, but they are also tasks that can saturate quickly. They are not direct measures of causal perturbation prediction, target ranking, rare differential-expression tails, OOD genetic perturbations, or generalization across biological contexts.
The “learning saturation point” in the paper is useful, but it is not really a scaling law. It asks: what is the smallest pretraining size that reaches within 95% of the best observed score on this benchmark? That is a helpful diagnostic, but it can be overinterpreted when the downstream task itself is saturated.
The perturbation result is, IMO, limited: a few selected Tahoe-100M small molecules across several cancer cell lines, evaluated with genewise R²/MSE. The paper itself reports that a “no-change” baseline beats fine-tuned models for most drugs, which says as much about the evaluation regime as about model scaling.
In fact, our scGPT work already showed three years ago that simply scaling the number of observational cells saturates quickly after a few million cells. So I agree with the warning: naive “more atlas cells = better virtual cell” is not enough.
But that is not the real scaling question.
In X-Cell, we study scaling across multiple axes: number of perturbation cells, number of biological contexts, perturbation diversity, and model parameters. On our Perturb-seq-scale data, we observe clear and encouraging scaling behavior. Similar trends are emerging from other perturbation-native virtual cell efforts as well.
The important question is not: can more atlas cells improve cell-type F1? It is: with larger Perturb-seq datasets, larger models, better architectures, and harder OOD splits, can we predict causal cellular responses across genes, combinations, doses, cell states, and contexts?
For X-Cell and the next generation of virtual-cell models, the goal is not just better embeddings. It is target ranking, rare DE tails, counterfactual biology, and prospective perturbation prediction.
So my reading is: this paper is a useful caution against naive scaling, not evidence that scaling laws do not apply to virtual cells.
The exciting regime is still open: scaling the right data, the right models, and the right objectives for causal cellular biology.
We need a version of this taking into account all the muscles and joints in human anatomy. We could use that so agents can design realistic animations for simulations and video games or train animation models that react to the environment
Still work to do on weight, gravity and the "paper legs" but I'm really impressed which this -- in this clip I'm moving the points around and the body responds with "realistic" movement.
@claudeai Fable is pretty incredible.
The Bitter Lesson for Biology — Adam Green on Scaling Laws for Virtual Cells
In this episode, the founder of Markov Biosciences, @adamlewisgreen, explains the "bitter lesson" for biology, the idea borrowed from Richard Sutton that large unbiased datasets and the right training objective tend to outcompete models with hard-coded rules and human priors.
We talk a lot about virtual cells, sources of bias in data, and his evidence that virtual cells pre-trained on plain observational data show clean scaling laws, getting monotonically better at predicting unseen perturbations as the models grow, and beating a state-of-the-art model built specifically for that task.
Our interview was about 3 hours long, but cut to 1.5 hours. My main goal was to understand Adam's perspective on virtual cells and his goal to "solve biology."
Search for "The New Biology" on YouTube, Spotify, and Apple Podcasts.
Timestamps:
00:00 — Cold open
01:58 — Clinical predictions from a virtual cell
05:38 — What is a "virtual cell"?
08:01 — The problems with single-cell RNA-seq
11:31 — The urns analogy
19:54 — Observational vs. perturbation
23:29 — The bitter lesson for biology
29:06 — Geometric Plackett-Luce
38:27 — Ablations and loss function
47:23 — Cells as specimens
59:26 — Antibody-Drug conjugates
1:11:16 — Will we ever understand the cell fully?
@theodorus5@Eric_Betzig Every enzyme exploits a combination of probabilistic rules (the interaction of electron clouds in residues) that collectively lead to repeatable behaviours. I would say they are pretty reliable
What's crazy to me is that Fable is blocked from life sciences broadly, nerfed even if you get passed the classifiers and filter level blocks.
The whole point of AGI/ASI is to cure all diseases. Everything else is just nice to haves. But Anthropic wants to close off that path.
I think Anthropic might be the worst company on the planet.
>Be Anthropic
>Don't trust humans with any cyber or bio outputs
>Nerf models on AI R&D so no one else can achieve RSI and compete
>Effectively Misanthropic
I am all in on AI for years & want AI to help humanity eliminate all diseases & reverse aging. I was so excited about Fable 5 releasing today. Yet, I can’t even say the word “cancer” to Fable 5, because I am a biomedical scientist! Anthropic is the only AI company that I fear!