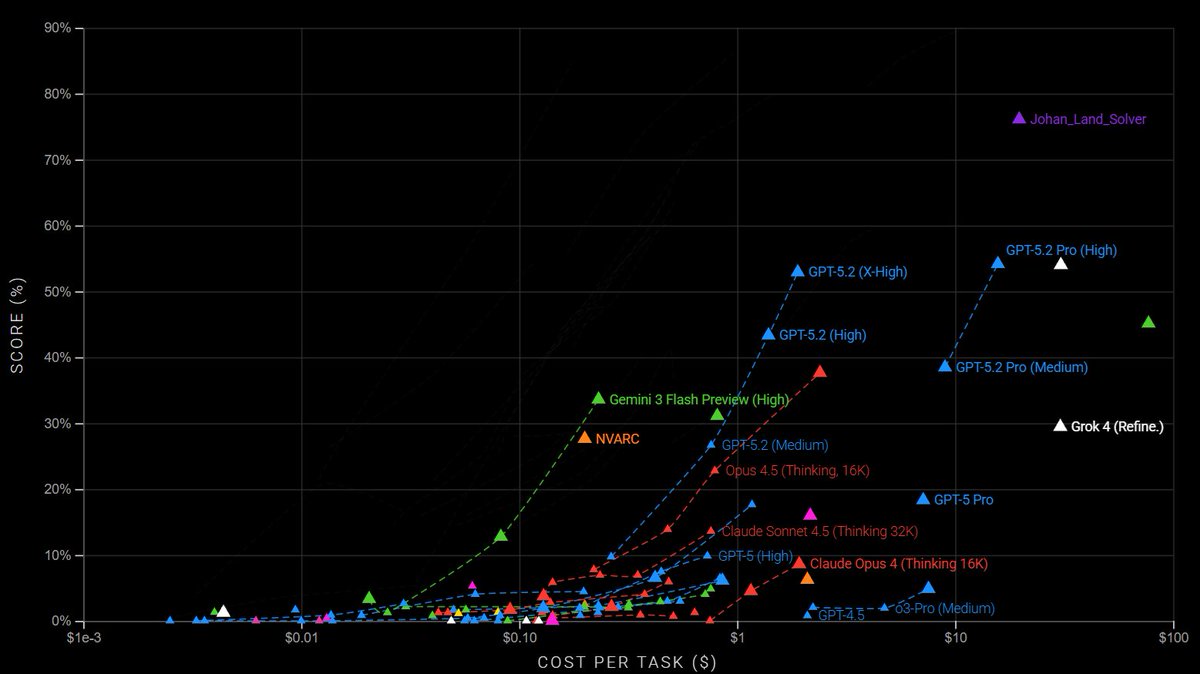
Just scored 76.11% on ARC-AGI 2 — beating public GPT-5.2 and Gemini-3-Pro baselines by >20%, and (as far as I know) the best publicly reported result so far.
Approach: what I’d call Multi-Model Reflective Reasoning
- Using GPT-5.2, Gemini-3, Opus 4.5
- Long-horizon/multi-step reasoning (~6hrs/problem)
- Agentic codegen (>100,000 python calls)
- Visual reasoning
- Council of judges
Fun fact: all solver code was written by Gemini-3-CLI.
Does this count as AI generating a new AI that beats the prior SOTA? 🤔
Full run + code (open source): https://t.co/8HZJV5XjIK
@GregKamradt , holiday break is over 🙂 semi-private when?
#ARCAGI #AIResearch
@thedjpetersen@ItsBrain4Brain@arcprize The code is open source: https://t.co/pqWRg79oqy
Do whatever you want with it :) I don't think I even put in any license in there so it's free for all!
No, but it's all open source. Maybe I should write a paper.
Essentially, it's gathering the reasoning traces for all possible solutions. Then it's exposing those to three different judges with slighly different roles. The judges then express their opinions after which a solution is picked.
@diegocabezas01 It's all public source: https://t.co/pqWRg79oqy
Check the v7 branch, that's the latest. Actually, go back a few commits and you'll find an even higher performing version - I had to dumb it down a bit for the submission.
@DeryaTR_ Next challenge is indeed ARC-AGI-3!
The beautiful thing about ARC-AGI is that they allow "hobbyists" like myself to fairly be benchmarked against the labs.
@joshlee361 Largely I agree. Few other things to it, but the key thing indeed is that different models/prompts/modalities/chaining generate diverse results. But then, you also need to "know when you know" and "know when you don't know" which is the other half of the problem.
@SuperbBias Diversity is the keyword indeed. Of the biggest insights I had was to induce diversity in the models by forcing them to thinking in different spaces and modalities.