Student of markets and the world at large; Trader @IMCTrading; @Penn @Wharton; it’s more fun to talk to people who disagree with you, and it makes you wiser.
Mythos is very powerful, and should feel terrifying. I am proud of our approach to responsibly preview it with cyber defenders, rather than generally releasing it into the wild.
Model card here: https://t.co/HjhknJcRKQ
I'm already bumping up against interesting moments between models and myself, the developer
I had to add this today to ETHOS.md
**User sovereignty.** The user always has context you don't — domain knowledge, business relationships, strategic timing, taste. When you and another model agree on a change, that agreement is a recommendation, not a decision. Present it. The user decides.
Never say "the outside voice is right" and act. Say "The outside voice recommends X. Do you want to proceed?"
- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
As the constraint moves from code generation to verification, deep rethinking of where human involvement is needed and being super intentional about system and workflows design are relevant more than ever to fully embrace the powerful agentic paradigm.
5/ We are injecting god-like capabilities into a system designed to price scarcity. We lack the mechanism to allocate these new benefits. The entire economic incentive system requires a ground-up rewire.
The explosive growth of AI is forcing a first-principles rethink of value and agency. We're unlocking massive capabilities, but our economic system isn't built for abundance. A few takeaways on the phase transition ahead: 🧵👇
Caught up with @karpathy for a new @NoPriorsPod: on the phase shift in engineering, AI psychosis, claws, AutoResearch, the opportunity for a SETI-at-Home like movement in AI, the model landscape, and second order effects
02:55 - What Capability Limits Remain?
06:15 - What Mastery of Coding Agents Looks Like
11:16 - Second Order Effects of Coding Agents
15:51 - Why AutoResearch
22:45 - Relevant Skills in the AI Era
28:25 - Model Speciation
32:30 - Collaboration Surfaces for Humans and AI
37:28 - Analysis of Jobs Market Data
48:25 - Open vs. Closed Source Models
53:51 - Autonomous Robotics and Atoms
1:00:59 - MicroGPT and Agentic Education
1:05:40 - End Thoughts
4/ Value Shift: As open-source models make intelligence an abundant commodity, value skips software and pools at physical bottlenecks. The ultimate winners won't own model weights; they will control silicon, data centers, and energy grids.
In a democracy, it’s absolutely ok to define who can use the things you make and how.
But it’s also absolutely ok for the Government to lose trust in you, tell you to fuck off and find an alternative.
It’s also absolutely ok for you to nuke your own company in the process.
The timing of this is not good for Anthropic and could be a potential boon to every other model that is exceeding expectations in their upcoming version (Grok, OAI, Gemini).
More generally, I don’t see how this isn’t a slippery slope. What if a model maker updates their ToS that would block a use case that is legal but subjective? Agreeable in some states but not in others? What about in different countries with different governance or religions?
It’s a huge can of worms.
How can a government or company rely on a model that could have an ever-changing definition of what’s allowed without taking on major business/governance risk?
They won’t.
My hunch is that the company that embraces the “no holds barred” ToS will win because it’s the least risky to adopt wrt long term risk of getting rug-pulled.
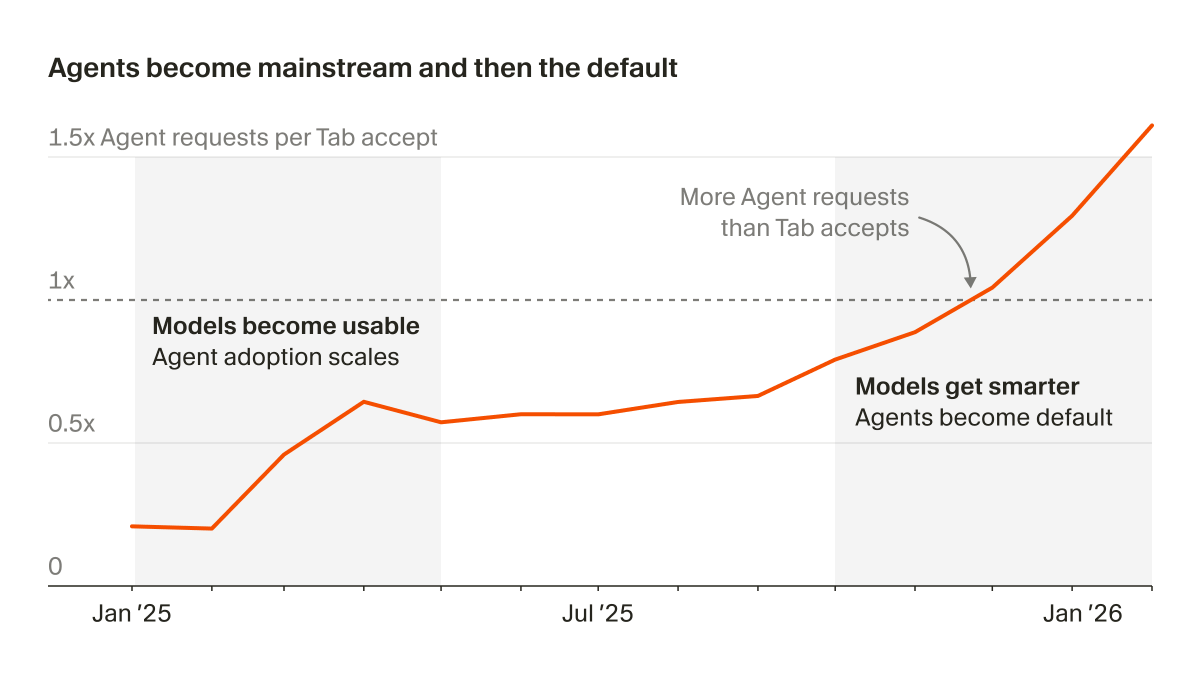
Cool chart showing the ratio of Tab complete requests to Agent requests in Cursor. With improving capability, every point in time has an optimal setup that keeps changing and evolving and the community average tracks the point. None -> Tab -> Agent -> Parallel agents -> Agent Teams (?) -> ???
If you're too conservative, you're leaving leverage on the table. If you're too aggressive, you're net creating more chaos than doing useful work.
The art of the process is spending 80% of the time getting work done in the setup you're comfortable with and that actually works, and 20% exploration of what might be the next step up even if it doesn't work yet.
Google and Microsoft just co-authored the spec that turns every website into an API for AI agents. The second-order effects here are massive.
Right now, browser agents work by taking screenshots, parsing the DOM, and guessing which buttons to click. It works about as well as you’d expect. Fragile, expensive, slow. WebMCP replaces all of that with a single browser API: navigator.modelContext. Websites register structured tools directly in client-side JavaScript. The agent reads a menu of available actions, calls them, gets structured data back. No scraping. No backend MCP server in Python or Node. The tools run inside the browser tab and share the user’s existing auth session.
Early benchmarks show ~67% reduction in computational overhead compared to visual agent-browser interactions. Task accuracy around 98%.
The second-order effect is where this gets wild. Today, when a browser agent visits two competing airline sites, it’s guessing at both interfaces equally. Once WebMCP adoption spreads, the site that exposes structured tools gives the agent a clean, reliable path to complete the task. The site that doesn’t forces the agent to fumble through the UI. Agents will prefer the cheaper path. Every time.
This means “Agent Experience Optimization” becomes a real discipline. Tool naming, schema design, description quality. Sound familiar? It’s the same shift that happened when meta descriptions and structured data became optimization surfaces for search engines. Except this time, the traffic source isn’t Google’s crawler. It’s every AI agent on the internet.
Bots already make up 51% of web traffic. Google just gave them a front door.
Jensen Huang: AI is going to make poorly defined work much more valuable.
Because that’s all humans will do. AI will handle everything else.
So what is poorly defined work, and how do you get good at it?
Defined work means given these inputs, produce this output. Write code that does X. Summarize this document. Calculate this metric. The goal is specified. The constraints are known. The evaluation criteria exist before you start.
Poorly defined work means should we even build this feature? What market should we enter next? Is this candidate going to work out? Which of these three strategic directions is least wrong? There’s no right answer you can verify. There’s only judgment.
AI is going to get freakishly good at defined work. Give Claude a spec and it’ll execute. Give GPT a rubric and it’ll score. The skill of translating well-defined problems into solutions is getting automated at 10x speed every 18 months.
But AI can’t tell you what problem to solve in the first place. It can generate 50 options. It can’t tell you which one matters. That requires something AI fundamentally lacks: skin in the game. Stakes. Consequences you actually have to live with.
So how do you get good at poorly defined work?
You make irreversible decisions faster than feels comfortable. The skill is pattern recognition built through reps. You can’t build judgment by thinking about decisions. You build it by making them and eating the outcomes.
You get comfortable with “I don’t know yet” and commit anyway. Defined work has the comfort of eventual correctness. Poorly defined work means moving while uncertain. The people who thrive here tolerate that discomfort instead of seeking premature closure.
You build taste through volume. Taste is internalized judgment from thousands of micro-decisions. The designer who can feel when something is off made 10,000 design choices before. The PM who senses a bad roadmap decision lived through 100 launches.
You seek roles where you own outcomes, not tasks. Task ownership is defined work. Outcome ownership forces you into the undefined space constantly. You can’t own revenue without deciding which features matter.
The uncomfortable truth: most people’s entire careers have been defined work dressed up as judgment. They executed someone else’s strategy. They optimized someone else’s metrics. They never had to decide which metrics mattered.
That’s about to become visible. Fast.
I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.