FlashLib update: we now support ANN search with IVF-Flat — up to 6.5× faster than cuVS on real-world vector workloads (SIFT-1M) while matching recall.
LEANN now supports FlashLib as a backend: 26× faster build, 29× faster single-query, and 298× faster batch search. Huge thanks to @YichuanM for the help!
We’re also opening Discord / Slack channels — join us to suggest new operators you want to see, and hardware backends you want FlashLib to support next!
Slack: https://t.co/BiH46PvPbH
Discord: https://t.co/6sfTJKkLtG
happy to share another quality tech report w/ the wider research community 🫶
great read for ppl who want to see all the details for methods + infra for scaling up pretraining & RL, esp detailed discussion about data which is often kept vague by other labs
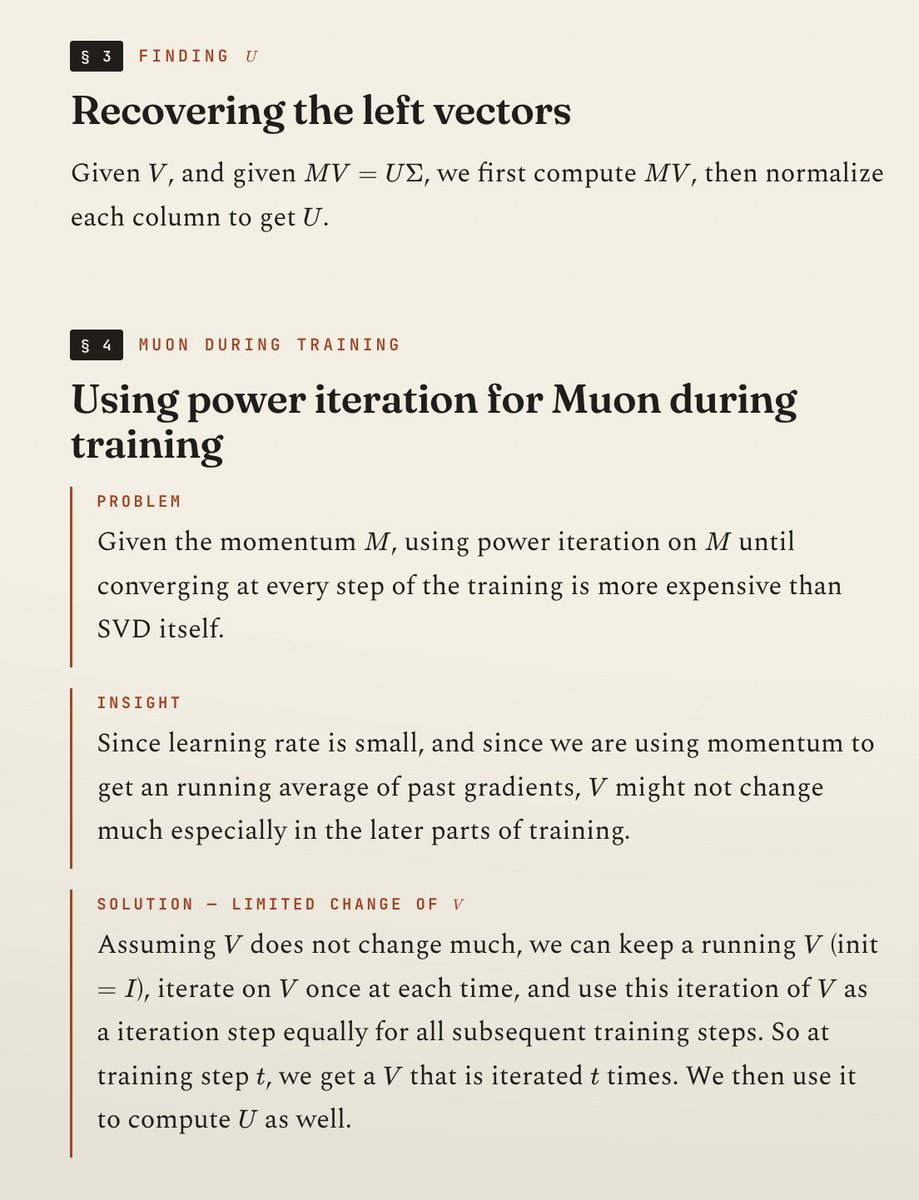
I am a big fan of Jianlin Su's blog because it always starts from first principles in mathematics, rather than "ML tricks", to approach a typical ML problem (eg. training-free MoE load balancing).
Here is me trying to "reinvent" one such blog which provides an elegant alternative to compute Muon, by filling in all the derivations that the blog skips for a less math-savvy audience (besides being entirely in Mandarin).
The goal of the blog is to find a way to compute a essential component of Muon, ie. the left and right singular value matrices U and V for the gradient G, **individually**. In the standard form, Muon really just needs their product UV^T, hence the standard way to compute it via computing a low-rank polynomial of G many times ("Newton-Schulz"). But there are more variants of Muon to control the properties of model updates if we can get both individually, hence the blog's proposal to revisit some fundamental linear algebra techniques for the computation.
The methodological takeaway from the blog's thought process is that there are three components to breaking down a ML problem: (1) how to be able to compute something (power iteration), (2) how to compute it fast (cholesky decomposition), and (3) how to compute it accurately given finite floating points (repeated orthogonalization). The goal of reading inspiring blogs like this is, in Feynman's term, to be able to "reinvent" them at any time to grasp the fundamental approach of doing similar work.
Original blog: https://t.co/5ksKPICpMW
LLMs learn by predicting tokens. World models (JEPA, data2vec) learn by predicting their own abstractions. Which needs more data? For data with hidden hierarchy, we prove the gap is exponential. https://t.co/r2uuX0lBCu
🚀 How should LLMs sample on hard reasoning problems during post-training and inference where direct rollouts rarely produce a correct answer?
Best-of-N (e.g., GRPO) and tree search share two limitations:
🔻 Verification signals are sparse
🔻 Candidates stay within the model's own distribution
We introduce BES: Bidirectional Evolutionary Search — a search framework that couples forward candidate evolution with backward goal decomposition.
✅ Works for both post-training and inference.
Flash-KMeans was only the beginning.
Today, from the Flash-KMeans team, we are releasing FlashLib — a GPU library for fast, predictable, agent-ready classical ML operators.
Up to 26× on KMeans, 19× on KNN, 40× on HDBSCAN, 208× on TruncatedSVD, 47× on PCA, 147× on exact t-SNE, and 49× on MultinomialNB over state-of-the-art (cuML).
Blog: https://t.co/P31SGl0cyT
Code: https://t.co/9nkO2hmeOl
Our paper was accepted as a #ICML2026 Spotlight!
Reasoning in LLMs has improved largely by chaining local steps. But is that the whole story?
Humans occasionally make inferential "leaps" across domains, a faculty known as analogy.
We design a synthetic task to show how small Transformers acquire analogical reasoning, and find that the same signatures appear in pretrained LLMs.
arxiv: https://t.co/1WCizIKWly
code: https://t.co/82kOKCtJo7
My first PhD paper is out now in @Nature! Very grateful to have worked with the FutureHouse team on this, and a big shoutout to my co-first author @agreeb66 😀
The bitter lesson in 26 words:
Don’t be distracted by human knowledge, as AI has been historically.
Instead focus on methods for creating knowledge that scale with computation, like search and learning.
The future of Math is mathematicians and AI agents working together.
Very pleased to introduce @GoogleDeepMind's AI co-mathematician: a multi-agent system designed to actively collaborate with human experts on open-ended research mathematics.
Mathematicians testing the agent across areas as diverse as group theory, Hamiltonian systems, and algebraic combinatorics have reported impressive results.
In autonomous mode evaluation on the rigorous FrontierMath Tier 4 problems, AI co-mathematician scored an unprecedented 48% — a new high score among all AI systems evaluated.
Vision isn't an "add-on"—and we have the data to prove it. 👁️⚡️
Thrilled to share our new work on Transfusion-style models. We explored treating visual data as a first-class citizen from day one, from architecture to scaling behavior.
Check it out:
🔗 https://t.co/zONvWOFCuI
Happy to share that DR Tulu has been accepted to ICML as a ✨Spotlight✨!
We believe that co-evolving the agent and its reward metric can lead to more capable intelligence.
DR Tulu is a team effort. Huge thanks and congrats to all my amazing collaborators and mentors!
Reading @deepseek_ai 's v4 paper.... absolute hats off.
Every problem has a mathematical solution, nothing is left to chance.
I have so much respect for them, putting out months or years of efforts entirely for free, in the open for anyone to benefit. Real goats 🫡
Attention moves large matrices between SRAM and HBM:
To compute QK:
- distribute matrices to threads
- compute, and
- send the product to HBM
To compute softmax:
- distribute product to threads
- compute, and
- send output to HBM
Repeat for all layers.
Check this 👇
Introducing ml-intern, the agent that just automated the post-training team @huggingface
It's an open-source implementation of the real research loop that our ML researchers do every day. You give it a prompt, it researches papers, goes through citations, implements ideas in GPU sandboxes, iterates and builds deeply research-backed models for any use case. All built on the Hugging Face ecosystem.
It can pull off crazy things:
We made it train the best model for scientific reasoning. It went through citations from the official benchmark paper. Found OpenScience and NemoTron-CrossThink, added 7 difficulty-filtered dataset variants from ARC/SciQ/MMLU, and ran 12 SFT runs on Qwen3-1.7B. This pushed the score 10% → 32% on GPQA in under 10h. Claude Code's best: 22.99%.
In healthcare settings it inspected available datasets, concluded they were too low quality, and wrote a script to generate 1100 synthetic data points from scratch for emergencies, hedging, multilingual etc. Then upsampled 50x for training. Beat Codex on HealthBench by 60%.
For competitive mathematics, it wrote a full GRPO script, launched training with A100 GPUs on https://t.co/udm7xGpNzR, watched rewards claim and then collapse, and ran ablations until it succeeded. All fully backed by papers, autonomously.
How it works?
ml-intern makes full use of the HF ecosystem:
- finds papers on arxiv and https://t.co/brvCC7fLPa, reads them fully, walks citation graphs, pulls datasets referenced in methodology sections and on https://t.co/hrJuRkRyzi
- browses the Hub, reads recent docs, inspects datasets and reformats them before training so it doesn't waste GPU hours on bad data
- launches training jobs on HF Jobs if no local GPUs are available, monitors runs, reads its own eval outputs, diagnoses failures, retrains
ml-intern deeply embodies how researchers work and think. It knows how data should look like and what good models feel like.
Releasing it today as a CLI and a web app you can use from your phone/desktop.
CLI: https://t.co/l3K1PslZ1n
Web + mobile: https://t.co/orko5srL4H
And the best part? We also provisioned 1k$ GPU resources and Anthropic credits for the quickest among you to use.
HRT’s first ever intern class of 10 included:
• Jesse Zhang, cofounder/CEO of Decagon
• Alexandr Wang, cofounder/CEO of Scale AI
• Scott Wu, cofounder/CEO of Cognition
• Jeffrey Yan, founder/CEO of Hyperliquid
Insane!