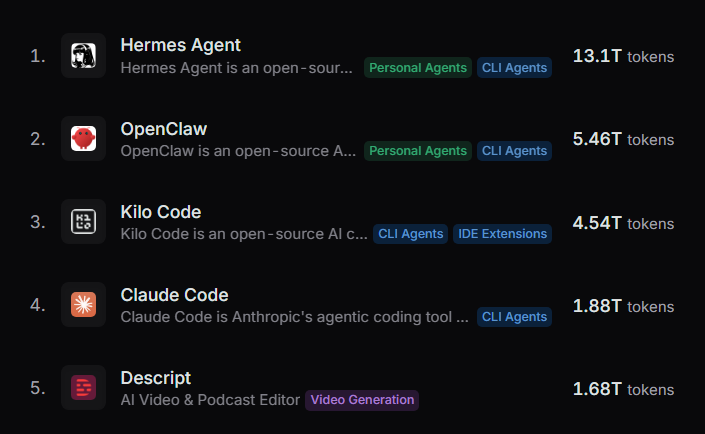
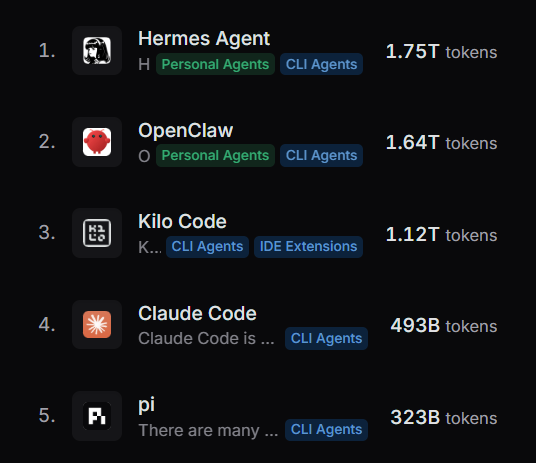
@kelstar_@NousResearch@OpenRouter Not sure why that would impact the rankings in this way. But further update now; Hermes Agent is now #1 on the monthly global charts too, and is so far ahead that it has more usage than OpenClaw, Kilo Code and Claude Code combined.
@anko_979@BlackHC It’s a common misconception that it was pulled, it wasn’t, it’s placement in the code of conduct was simply changed from the preface of the code of conduct to the ending section of the code of conduct where it still exists today.
Roughly related but I don't think they intend to use any GDPval score as evidence for AGI being achieved. They say in the paper themselves that it's largely work that is only a time-horizon of a few hours and the context is much more assisted than a real job. GDPVal is also far easier and more saturated than something like RemoteLaborIndex which comprises of real Upwork tasks (but still not typical employment positions)
Current GDPVal SOTA is over 80%
Current RemoteLaborIndex SOTA is less than 5%
@daniel_mac8@deredleritt3r In Microsofts October 2025 blog post about their latest partnership terms with OpenAI:
"Once AGI is declared by OpenAI, that declaration will now be verified by an independent expert panel."
@deredleritt3r@daniel_mac8 "Economically valuable work" is further defined by people internally at OpenAI as the jobs tracked by the US bureau of labor statistics. So I suppose it's a majority of those jobs that they mean.
@deredleritt3r In Feb 2026, Sam Altman said at a Stanford hackathon:
“If you are a sophomore now, you will graduate into a world with AGI in it"
Sophomores in Feb 2026 are set to graduate around mid-2028. I believe this is the first and only time he's stated such a near-term AGI prediction.
@ChaosEmergent@haider1 GPT-4.5 started training ~may 2024, almost exactly 2 years ago now. (Based on official OpenAI statements that mentioned starting training on their new next generation model at the time, along with corroboration from WallStreetJournal and others)
@zephyr_z9 That quote is not true to what he said. His statement was directly opposite of the what you created within your quotations. Here is his actual quote about that topic: "Even by 2028, I don’t expect that we’ll get systems as smart as people in all ways"
@juristr L9: You have the AI itself write the optimal coordination layer on the fly for spawning, routing and managing agents programmatically, in the way that works best for a given project and your preferences.
@otium33@BasedBiohacker@bryan_johnson He has already publicly talked about results of his personal peptide experimentation prior to doing his shroom experiments.
@haider1 It's been confirmed that some devs outside of OpenAI had early access to GPT-5.4 for atleast "a few weeks" prior to public release.
Exhibit A:
This model is absolutely insane.
I’ve been using it for a few weeks, and it’s the first model that made the impossible feel possible for me.
Particularly the pro version , it’s capable of solving even the hardest problems.
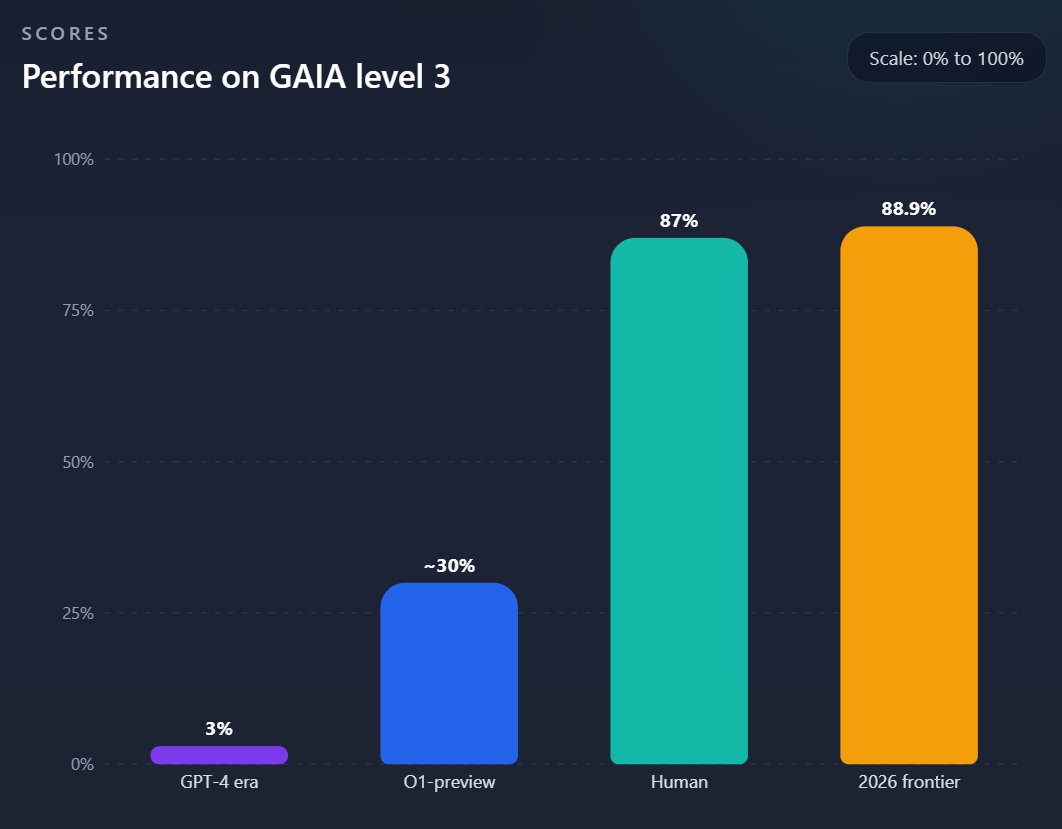
In November 2023, Yann LeCun, Thomas Wolf and others from Meta and Huggingface created a benchmark called GAIA, which described itself as: "A benchmark for General AI Assistants that, if solved, would represent a milestone in AI research." Most of the problem solutions were kept private, not released online.
It proposed 466 "real-world questions that require a set of fundamental abilities such as reasoning, multi-modality handling, web browsing, and generally tool-use proficiency."
On the hardest level, the average human score was 87%, while the leading systems scored less than 3%. 10 months later OpenAI released O1-preview, reaching ~30% on that level.
Now in 2026 the human baseline for the hardest level has officially been surpassed, the best agent systems are now scoring 88.9% on GAIAs hardest level (level 3).
@xundecidability @WaveTheoryAI The difference here is that GAIA is real world questions involving highly specific information that exists amongst human civilization across a diverse set of modalities, not an abstract puzzle.
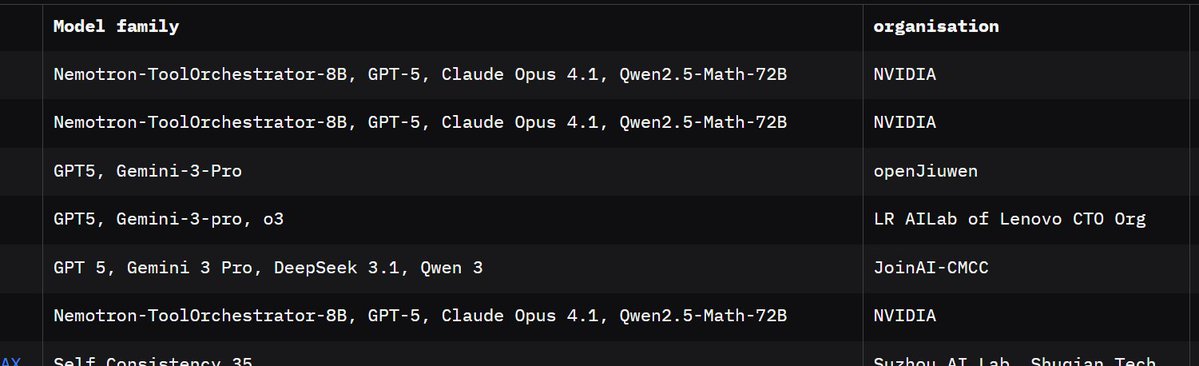
@nithin_k_anil The human baseline score was also matched/surpassed by GPT-5 and Gemini-3-Pro working together without any specialized orchestrator in the loop, and only scored ~2% below the top score by Nvidia. I imagine Opus 4.6, GPT-5.4 and Gemini-3.1 together would get an even better score.
The current highest level 3 score was achieved by Nvidia, leveraging a multi-agent system that includes Nvidias own tool orchestrator model. It scores 89.8% on Lvl 3 (even higher than the 88.9% typo I wrote above)
The public leaderboard can be seen here: https://t.co/nv4KWfiFYa