Your agents can bypass logins on any website 🥷
Here's how to use Browser Use Profiles:
> Create a profile and start the setup
> Sync your local browser to Browser Use Cloud
> Spin up a cloud browser with your synced profile
Setup once, stay logged in.
Try it now ↓🔗
As an AI Engineer. Please learn
>Harness engineering, not just prompt engineering
>Context engineering, not just long prompts
>Prompt caching vs. semantic caching tradeoffs
>KV cache management, eviction, reuse, and memory pressure at scale
>Prefill vs. decode latency and why they optimize differently
>Continuous batching, paged attention, and throughput optimization
>Speculative decoding vs. quantization vs. distillation tradeoffs
>INT8, INT4, FP8, AWQ, GPTQ, and when quantization hurts quality
>Structured output failures, schema validation, repair loops, and fallback chains
>Function calling reliability, tool contracts, argument validation, and idempotency
>Agent guardrails, loop budgets, tool budgets, and termination conditions
>Model routing, graceful fallback logic, and degraded-mode UX
>RAG architecture: chunking, embeddings, hybrid search, reranking, and freshness
>Retrieval evals: recall, precision, grounding, attribution, and citation quality
>Evals: golden sets, regression tests, adversarial tests, LLM-as-judge, and human evals
>LLM observability as a first-class discipline: traces, spans, tokens, latency, errors, and drift
>Cost attribution per feature, workflow, tenant, and user journey not just per model
>Safety engineering: prompt injection defense, data leakage prevention, and permission boundaries
>Multi-tenant isolation, cache safety, and cross-user context contamination prevention
>Fine-tuning vs. in-context learning vs. RAG vs. distillation and when each is the wrong tool
>Latency, quality, cost, and reliability tradeoffs across the full inference stack
>Production failure modes: hallucinated tool calls, malformed JSON, stale retrieval, runaway agents, and silent eval regressions
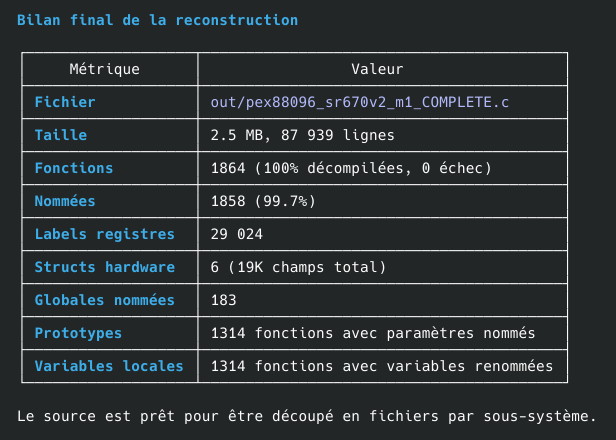
Tout est maintenant open-source.
Les agents LLM ont atteint un niveau où ils sont capables de prendre un binaire, le décompiler et reconstituer en autonomie le code source du programme.
Aucune compétence technique requise.
Suffit de leur donner les bons outils (ici, ghidra-mcp)
my read: not AGI solved yet, but the direction is real
the 'fly with Codex' energy is impressive because coding agents are becoming useful, autonomous and commercially relevant. But real AGI needs more than polished coding demos: robust world models, long-horizon reasoning, memory, verification, and the ability to operate reliably in messy real-world environments
a good benchmark would be something like deep-space autonomy: an AI capable of helping run an interstellar probe, Voyager-style, with limited compute, no real-time human help, strict energy constraints, and decades of reliability.
...so: huge progress, not AGI yet. We’re seeing early agentic systems that may become part of AGI, but “solved” is still too bold
google launches gemma 4 12b – nearly matches the 26b model on benchmarks, sometimes beats it, at less than half the memory footprint
what changed under the hood:
• vision. replaced the encoder with a lightweight embedding module (single matrix multiply + positional embedding + normalization). the llm backbone now handles visual processing directly
• audio. encoder removed entirely. raw audio signal is projected straight into the same token space as text
• inference. ships with multi-token prediction (mtp) drafters for speculative decoding, cutting latency
benchmarks (gemma 3 27b / gemma 4 12b / gemma 4 26b):
- gpqa diamond: 44 / 78.8 / ~80
- bbeh: 18 / 53 / 62 mmlu pro: 67 / 77.2 / 78
- livecodebench: 28 / 72 / 76
- docvqa: 83 / 94.9 / 93
- infovqa: 60 / 88.4 / 90
- mmmu pro: 65 / 69.1 / 72
runs locally on consumer laptops with 16gb vram or unified memory – including macbook m-series
demo source: google
follow @thehypedotnews for 24/7 ai news, analysis and breakdowns
Meet Gemma 4 12B!
A unified, encoder-free multimodal model designed to bring high-performance intelligence directly to your laptop, and released under an Apache 2.0 license.
Bridging the gap between edge efficiency and advanced reasoning. Here is what’s new with Gemma 4 12B: 👇
Devin Desktop is our first product launch that’s fully agent-neutral. You can run your own custom background agents directly from the desktop app, Devin, or even Claude Code / Codex. Part of Cognition being the Independent Agent Lab is working well with all of the agents - excited to do more in this direction.
Today, we announced plans to launch Spain’s first commercial robotaxi pilot in Madrid in partnership with @WeRide_ai. The service is expected to become available later this year through the Uber app, in partnership with the Madrid Regional Government. 🇪🇸
MOSS-TTS-v1.5 just reached #1 on Hugging Face Trending for Text-to-Speech, with 20.6K downloads.
A multilingual, controllable TTS model with stable voice cloning, long-form generation, and precise pause control.
MOSS-TTS-v1.5 is now officially supported by vLLM-Omni and SGLang-Omni.
Built by OpenMOSS-Team.
Try it:
GitHub: https://t.co/mSlALD6Fzy
Hugging Face: https://t.co/qTv7xu1MZ5
ModelScope: https://t.co/NzAXgAzagL
Qwen3.6 35B A3B can't fill out a paper form on its own. But give it NVIDIA's LocateAnything-3B — the #1 trending model on HuggingFace — as its eyes, and the two small models get it done together.
(The test: place each element at the right pixel position on a blank form image, not type into a field.)
Setup:
> Qwen is the brain (main model), LocateAnything is the eyes (helper model acting as a tool).
> I gave Qwen a new tool: ask "where's the email field?" and LocateAnything returns the exact x, y, width, height.
> The blue boxes on the screen are its detections. Look how tight they are — it nails every field.
Result:
> Qwen3.6 35B A3B + LocateAnything-3B: form completed, all info correct.
> Name, DOB, ID, gender, marital status, nationality, email, phone, address, postal code: all landed in the right field areas.
> Character-box alignment still a touch loose, but every value is where it belongs.
> 9m10s, 224.5k input, 24.3k output, 21 turns.
Why it matters:
> Qwen alone can't finish this test. Bolt on a 3B model that does exactly one thing > locate > and suddenly it can.
> A combination of small models can do the work of a single large one.