Open sourcing Microcode! Microcode is a context-efficient, general purpose terminal agent fully powered by a packaged `dspy.RLM()` program. Set your own OpenRouter API key via and choice of models. Supports MCP servers too with @MaximeRivest mcp2py.
Because the CI/CD of the RLM engine is exposed through @modaicdev, per-user or per-codebase prompt optimization is plug and play.
If you set the --verbose flag, it pretty prints the RLM's trajectories as reasoning or code within it's REPL.
@nbaschez We’ve also found that giving Claude access to start and stop an app with multiple daemons and access to read logs is crucial for longer self directed exploration. Any reason you like pm2 over docker?
@lateinteraction 💯. Python is often my object code, and my human intention from reading and writing in the multi turn code agent setup is the only important part and is often lost in PR comments.
I know I especially don’t record praise of what the agent got right that I was worried about
Also a big fan of GEPA! If you’re optimization runs are taking a long time you should take a look at our k-way proposal function called GEPA+. It reduces metric runs by 30-40% while improving relative accuracy by 2-5% depending on tasks!
https://t.co/603AmYLSOD
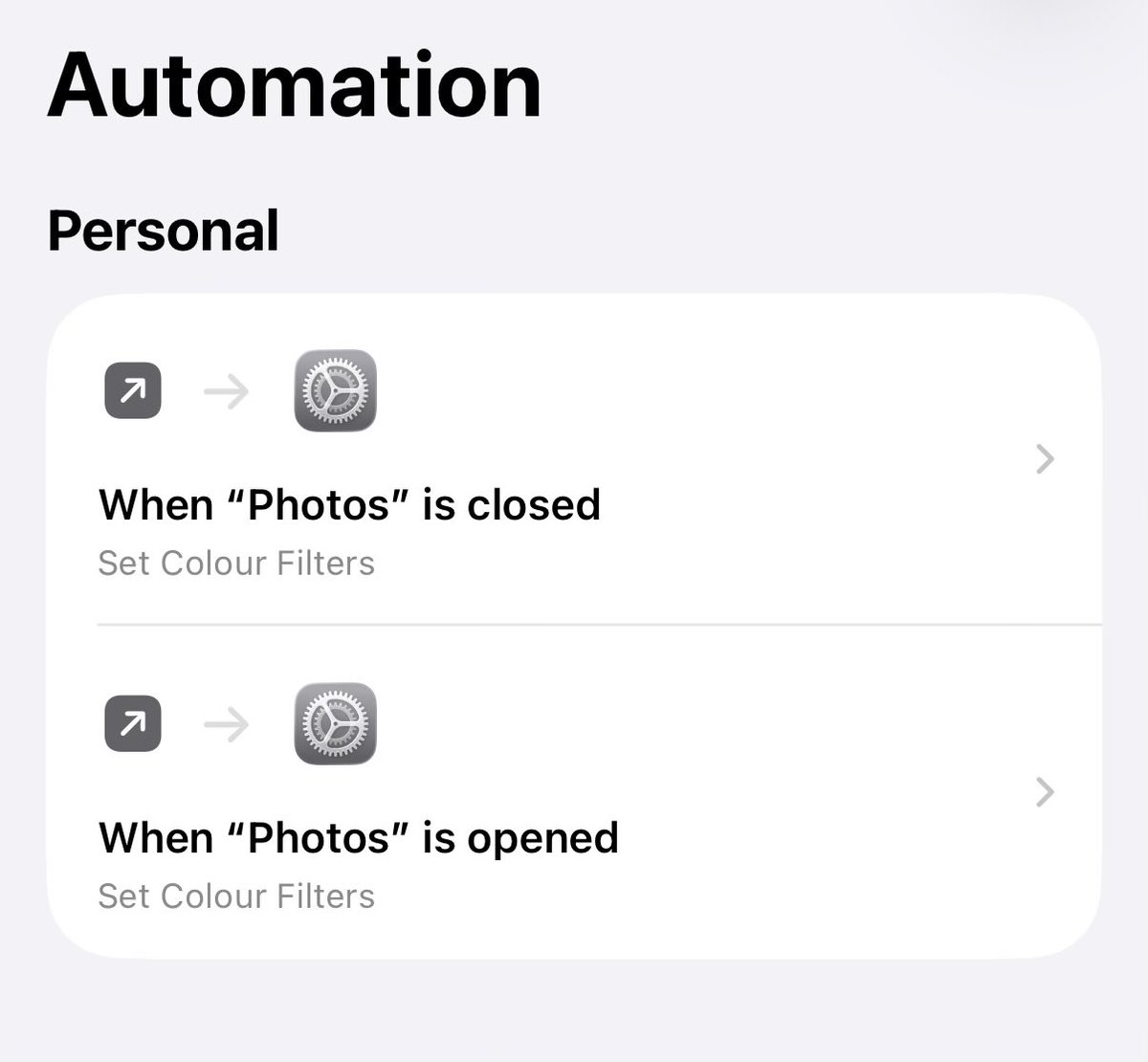
This! Sometime last year I made the switch, the default is greyscale and it automatically turns to colour when I’m looking at photos and back when I close it!
100% would recommend
@chrisbolas@noah_vandal@DSPyOSS As I’d explained a bit farther down, you want a dense model if you only have 8GB before you hit slow disk (micro sd), and gpt-oss is a MoE, most of your experts aren’t going to mix in, so a dense model like Qwen3 4B Thinking 2507 utilizes memory more
@JoshPurtell I have found that GEPA is extremely sample efficient. I got from 7% to 50% accurate on chat to sql for qwen3 0.6B on a MacBook in a day. And 7% to 28% in one pass through my <300 item dataset with a Qwen3 4B reflection LLM https://t.co/dwt6WBKWhf
DSPy on a Pi: Cheap Prompt Optimization with GEPA and Qwen3
“It took me about sixteen hours on a Raspberry Pi to boost performance of chat-to-SQL using Qwen3 0.6B from 7.3% to 28.5%. Using gpt-oss:20b, to boost performance from ~60% to ~85% took 5 days.”
@noah_vandal@DSPyOSS With under 1GB to spare! But gpt-oss:20b (in Ollama) has weights of ~12GB and takes another few gigs of inference memory so I mostly had my four cores going full time on the 16GB Pi 5. Qwen 4B optimizing Qwen 4B would be even smaller. On a MacBook it is within an afternoon :)
@karanjagtiani04@DSPyOSS No manual tuning! That’s the whole point :) I just made a pretty basic prompt with some bland facts about the data (multiple rows per paper, one per author, read only, call out content policy violations) and GEPA did the rest, and DSPy was super easy to use to separate concerns
DSPy on a Pi: Cheap Prompt Optimization with GEPA and Qwen3
“It took me about sixteen hours on a Raspberry Pi to boost performance of chat-to-SQL using Qwen3 0.6B from 7.3% to 28.5%. Using gpt-oss:20b, to boost performance from ~60% to ~85% took 5 days.”
@lmeyerov Those piles of boring features that are getting automated are all closer to each other than making the initial proofs of concept so it’s easy to imagine that coding agents will get better at them, and that iterative polish is an iceberg of work, esp re compliance
For this reason, I’ve heard tech “debt” referred to as a “unhedged call option”: the downside of the loan is unknown when you take it out. Who knows what’s lurking in that code no one understands. https://t.co/vEr1oNoKQW