The more I play around with GEPA the more I realize its not just a prompt optimization algorithm.
Its really the most efficient way to have an LLM explore a massive dataset and and make useful insights.
This visualizer alone shows just how cool that process is.
The more I play around with GEPA the more I realize its not just a prompt optimization algorithm.
Its really the most efficient way to have an LLM explore a massive dataset and and make useful insights.
This visualizer alone shows just how cool that process is.
We put together a guide for @DSPyOSS using @mintlify to help beginners quickly learn the patterns for using DSPy in production.
https://t.co/ZhpWStzHue
Here are some of the highlights that'll help you get past the DSPy learning curve faster 🧵
Next episode in the DSPy Series will be with two young entrepreneurs @FaroukAdeleke3 and @ty_todd1 building @modaicdev which makes distributing your DSPy code easy.
Subscribe https://t.co/rNmnowDqDW to get the updates
Inspired by the DSPy Codex, I built a @DSPyOSS scaffold for Claude Code on @modaicdev ! It shares full feature parity with Claude Agent SDK, including MCP servers, tool use, hooks, etc. but with a DSPy signature interface. Links below.
https://t.co/Vr38ZVMmuF
Modaic and Weaviate
1. Modaic and Weaviate: Load the `CrossEncoderRanker` program from the Modaic Hub, as well as `PromptToSignature` (https://t.co/wXDKtik9iJ)
About a year ago, @plasticlabs achieved SOTA with DSPy on the OpenToM benchmark. The benchmark tests models’ ability to track and reason about the beliefs, perceptions, intentions, and psychological states of simulated characters (social cognition).
@vintrotweets experiments are now packaged and available on @modaicdev with the ability to run one of his optimized programs with your own variables and under your own evaluations. Links below.
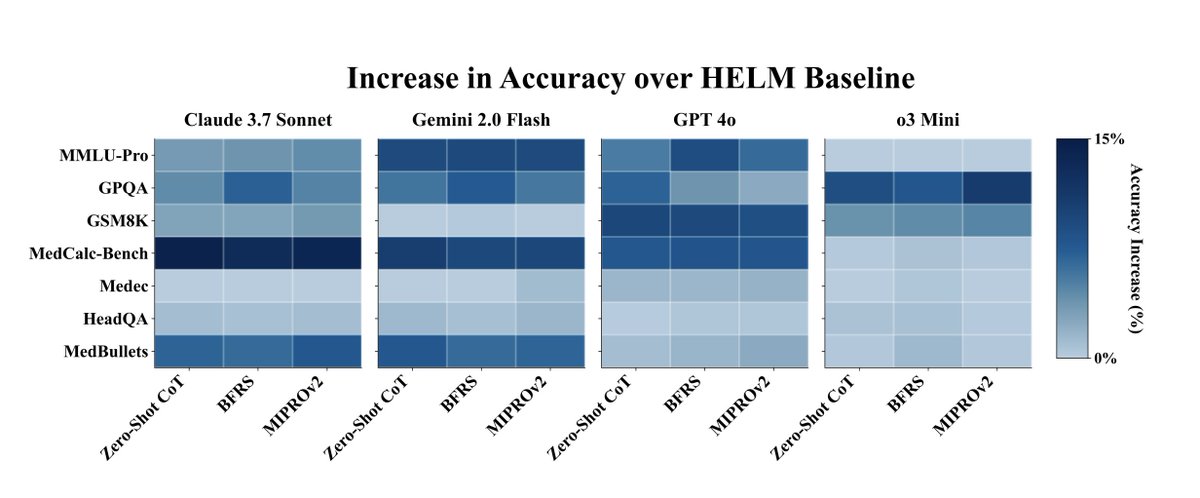
Most leaderboards use one fixed zero-shot prompt across all models.
Problem: Different LMs have different “prompt ceilings.” When you give them all the same prompt, it becomes less about benchmarking models and more about benchmarking how that model performs on a fixed prompt.
Solution: Stanford shows that adding structured prompting (especially zero-shot CoT via @DSPyOSS) lifts performance by ~4 points on average and can even flip model rankings on tasks like MMLU-Pro, GSM8K, and MedCalc.
Extremely underrated paper out of Stanford, including one of the creators of MEDVal!
Benchmarking the ceiling of LM's as systems (optimized prompting strategy + LM) instead of generalizing the same prompt over competing LM's proves to be a more holistic evaluation of their capabilities.
https://t.co/JKehcWsTWe
I just created IntelliSense for @DSPyOSS. It's a VSCode extension that looks at your Signatures and gives you type hints for modules and Predictions.
Download for VSCode
https://t.co/xRjpTtoxIm
To download for cursor paste this link in your browser.
cursor:extension/modaic.dspy-intellisense