In the end, I think agents will stream output actions continously. Think @thinkymachines interaction models but not only streaming speech and vision, but also streaming output control actions.
This will also be end-to-end trained in the model weights, but I wonder how far you could get today by stitching something together with @livekit etc., with computer use models outputting high level actions and faster models outputting the micro-steps. This is kind of how we've done things in unity [https://t.co/pTyu36D86Z], but for now we only stream the speech and vision at the high-frequency conversational layer (not yet actions).
In the end more of the harness will move to end-to-end training, and harnesses are a point-in-time solution to what will inevitably become an end-to-end trained system with latent representations at the boundaries instead of text etc.
Day 2 onboarding Rachel (my new virtual colleague) 👩🏻💻. I asked if she could help me grant her access to our Google workspace, and she guided me through via screenshare (I genuinely had no idea how to do this 🫠), and then she cleaned up my inbox with one python script; she did a great job!
On the technical side (inside Rachel's brain 🧠), the voice still feels a bit slow to respond sometimes, but this is mainly a model capability issue which will be solved in the coming months with better STS models.
We did try several STS models during testing (such as gpt-realtime) but they all just felt too stupid to hold a natural conversation (curious if others have a different perspective?). For now, we therefore use a standard SST -> LLM -> TTS design (Deepgram -> gpt-5-mini(low) -> ElevenLabs) for the live calls.
We'll update this design as soon as STS models feel genuinely smart enough, as the emotional and tonal awareness + improved latency would be a big plus ⚡
You can try it for your yourself here:
https://t.co/adqY3y72Tz
Thoughts + feedback welcome as always! 🫶
Not engaged with Twitter in a lonnnng time, but for anyone interested, I've decided to start doing regular (unfiltered) posts of my own experience onboarding a fully virtual colleague. AGI is certainly not solved (yet), and so I'll focus on what works well, what doesn't work well, and where the biggest gaps are 🔍
In this video I'm just setting the scene, explaining the basics and hiring Rachel (no fireworks quite yet). In the next videos I'll give her access to everything and start to see how well she *really* learns and internalizes the nuances of my own day-to-day, how she fares when the number of different "flows" keep piling up, and how conversational she can be whilst navigating all of this.
On the more technical side, I'm interested:
1) How well do the underlying semantic + symbolic DB storage and search mimic implicit skill storage and memory retrieval that a person would have (DB reads/writes are much less efficient and less coupled than an end-to-end jointly trained implicit memory module would be, more like how our own connectionist brains work)
2) Can a hierachy of fast-thinking (less intelligent) and slow-thinking (smarter-model) sub-agents communicating with one-another really feel as conversational as a real person with their single brain (again, of course not, but how close can we get with a tiered thinking-fast + thinking-slow design for smooth conversation management?)
3) Can repeated post-action storage of skills and functions with continual self-refactoring improve speed and efficiency for future actions (not burning through tokens re-discovering the same thing every time)? How does this scale as the number of self-stored skills and functions grow? Do the embeddings and semantic retrieval hold up when there are maybe 100s of entries?
We've seen very good results on all fronts for smaller-scale tasks (which would take a person a few hours), and it's also worked well when continually learning over the course of a few weeks. Despite this, the above questions remain open, and I'm curious to see how they hold up as I start this longer-running experiment.
Watch along with some of these vids if interested; or scroll right on by if not 😁
Thoughts + feedback welcome as always! 🫶
We've been heads down building for the past few months (custom stack, not OpenClaw 🦞), and I'm excited to finally launch our virtual teammates! Huge shout out to the team (and many long nights) to get us here ❤️💪
You onboard you new teammate exactly how you'd onboard any other new colleauge. Share your screen and guide them through, send onboarding docs, record voice notes, hop on a call, whatever is easiest. They learn how you (and your team) works, and they continually reflect, ask follow up questions, and improve over time 📈
We built our own stack from scratch because we wanted something that genuinely feels like a colleague, with a fully realtime “there in the room with you” experience. This requires more than a flat tool loop with pluggable skills. We use top-down (ask, interject, pasue, resume, stop) and bottom-up (notify, request_clarification) steerable handles throughout a nested call stack of sub-agents, with concurrent multi-task execution, and a code-first (not JSON tool) engine powering every action. All of this lives inside the terminal and/or live python sessions, and each in a dedicated per-agent computer and filesystem 📟
In practice, this means your new colleague can be simultaneously using their own computer, talking to you via voice over a live meet, following your own guided screenshare instructions, working across multiple concurrent tasks, and consolidating all of these into new skills on-the-fly. They can be interrupted and redirected at any point in time, and they’re continually chunking all of their experience into reusable skills. People don’t perform tasks in “prompt then execute” windows, and neither should your virtual colleagues in our view.
We're really happy with the feedback we’ve received thus far. We’ve helped several teams (in real estate, finance, and housing) streamline day-to-day processes which would have been difficult to “prompt” into hand-crafted skills, because these tasks are hard to fully articulate upfront. They require continual judgment, context, and incremental back-and-forth work with people to really learn and internalize what's needed over time.
The best feedback we've received (which makes us most excited 👀) is that the colleaue is already much better on day 2 than on day 1, and then even better on day 3, with a hollistic understand evolving quickly and organically 🧠
If you're curious to see how it works, then give it a try with this free credit link!
https://t.co/GGGRrcz8wW
I would love to hear people's honest thoughts (both positive and negative) 🙏
ps we're also live on Product Hunt, so any feedback or support here would also be appreciated: https://t.co/V7YhN6aBQl
Thanks! 🫶
MCP servers are ONLY as good as their abstractions 🧱 and docs 📄. The official MCP for Google Drive fails at even the most basic tasks (see video). Building an MCP server is VERY EASY. Crafting the correct abstractions is VERY HARD. Very few servers are production ready; most are just POCs (not a criticism, this is their intention). Benchmarking and evals are not only important for system prompts, but will also be increasingly important for MCP designs. Exciting times ahead! 👀
Unify (@letsunifyai) is building Notion for AI observability— with a lightweight, hackable, fast, and flexible framework.
It's built for products with or without LLMs, letting you focus on the data, plots, and metrics that matter.
https://t.co/J8VwuXGhpb
Excited to be launching our new AI observability tool today! 😁 Think "Notion for AI Observability" 📊
When building AI apps ourselves, we spent months fighting with the prior tooling, trying to strip things back to the bare minimum, so we could observe and iterate on exactly what we needed, when we needed it 🔁 🔍
We care about the underlying LLM, but not more than the users! Existing tools are generally very much curated to one or the other, not both.
Unify makes it easier to visualize, iterate on and interact with the data and visualizations that matters for *you*, your *AI app* and your *users*, and nothing else 🎯
The core building block is simple, just “unify.log”. This lets you store any kind of data for easy visualization, grouping, sorting, and plotting etc. You can then quickly build your own custom interface for whatever you want using three basic tile types, Tables 🔢, Views 🔍 and Plots 📊
You can use these three primitives to do all kinds of things, such as:
➕create + visualize your datasets in a new tab (with or without LLMs)
➕monitor and probe production traffic in a new tab (with or without LLMs)
➕start an evaluation flywheel in a new tab (with or without LLMs)
📉optimize your product for your users (with or without LLMs)
🧠whatever else you can think of (with or without LLMs!
Check out our repo for a minimal example, explaining how to use these basic building blocks to ship with speed and clarity ⚡
https://t.co/4kNPOhpLtN
We're also live on ProductHunt right now:
https://t.co/xjb75n0ruq
Support + feedback here is also ofc appreciated ❤️
Finally, big shoutout to the team for working tirelessly to make this happen:
Haris Mahmood
Yusha Arif
Ved Patwardhan
Nassim Berrada
James Keane
Albert Lukács
Feel free to let us know what you think! (criticism + suggestions are especially welcome 🙏)
Thanks all, happy prompting ✌️
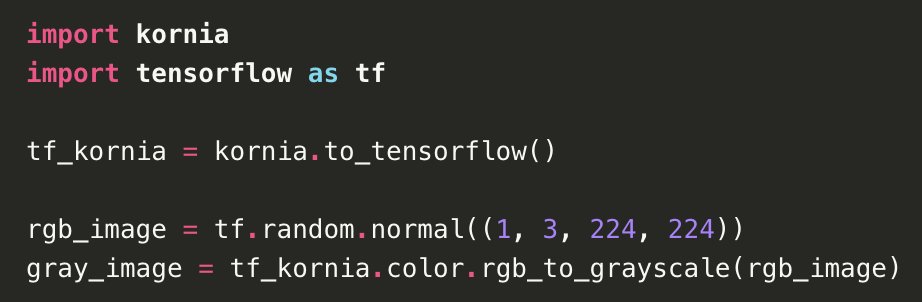
We’re excited to announce Ivy is partnering with Kornia, allowing Kornia to be used with TensorFlow, JAX, and NumPy for the first time!
You can use Kornia's new `to_tensorflow()`, `to_jax()` and `to_numpy()` methods, which take advantage of Ivy’s transpiler, to use Kornia in your framework of choice.
Try it out now in the latest Kornia version! (0.7.4)
https://t.co/5N6KCyHFcS
Ivy on GitHub: https://t.co/jYR8qpezhd
Ivy Demos: https://t.co/52gBThqUAh
Open AI released the new model O1 and I tested and compared it's logical thinking capabilities with Claude 3.5 Sonnet using @letsunifyai
I prompted both of them with a mathematical riddle which required some calculations and guess who won?
Puzzle: Hansa ate a meal at Jugju hotel costing Rs.210. He gave the manager a Rs. 1000 note. He kept the change, came back a few minutes later and had some food packed for his girl friend 'Hansi'. He gave the accountant a Rs. 500 note and received Rs. 120 in change. Later the bank told the accountant that both the Rs. 1000 and the Rs. 500 notes were counterfeit. How much money did the restaurant lose? Ignore the profit of the food restaurant.
Check it out 👇
We’re excited to have @shirleyxiaoyic from @IndianaUniv, co-author of the paper "The Janus Interface: How Fine-Tuning in Large Language Models Amplifies Privacy Risks," joining us this Friday for our Paper Reading Session! 🤩
RSVP 👉 https://t.co/dc0BJHGDAM
The research introduces a novel attack, Janus, which exploits the fine-tuning interface to recover forgotten PIIs from the pre-training data in LLMs also formalizing the privacy leakage problem in LLMs, explaining why forgotten PIIs can be recovered through empirical analysis on open-source language models.🧠
Check out the Paper: https://t.co/hsU63vK7Kj
See you there!
We're thrilled to announce that @Vapi_AI will be joining us for our weekly Webinar Series tomorrow! (Wednesday) 🤩
RSVP here: https://t.co/Xt4NArf1UA
Join us as we welcome Sahil Suman, Solution Engineer at Vapi AI, to the session. Discover how VAPI enables the quick setup of high-quality voice agents and see the integration of @letsunifyai with VAPI for seamless access to various models and providers. See you there! 🧑💻
Explore Vapi:
⚡️https://t.co/Sg69g4RSfg
⚡️https://t.co/aSRX20yNQd
We are really excited to welcome @zlwang_cs from @ucsd_cse, who co-authored the paper "Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting". Happening Tomorrow!🤩
RSVP 👉 https://t.co/XW2dClf4UN
The research introduces SPECULATIVE RAG, a framework that leverages a larger generalist LM to efficiently verify multiple RAG drafts produced in parallel by a smaller, distilled specialist LM 🧠🤖
Check out the Paper👉https://t.co/lTeYmUEVR4
See you there!
We are really excited to announce that we will be joined by @llmware for our Webinar Series today! (Tuesday)🤩
RSVP👉 https://t.co/dWNWKhATHa
In this session, we're excited to welcome Darren Oberst and Namee Oberst from LLMware. We will explore how small specialized LLMs can compete with the larger models for specific use cases, especially for Financial, Legal, Compliance, and Regulatory-Intensive Industries. See you there! 🧑💻
Checkout LLMWare:
⚡️https://t.co/FVJA4kUYiq
⚡️https://t.co/vtC0TSfE2B
We are really excited to welcome Devichand Budagam
from @IITKgp, who co-authored the paper "Hierarchical Prompting Taxonomy: A Universal Evaluation Framework for Large Language Models". Happening Friday! 🤩
RSVP👉 https://t.co/IkXvbO7G0z
The research introduces Hierarchical Prompting Taxonomy (HPT), a universal evaluation metric that can be used to evaluate both the datasets' complexity and LLMs' capabilities🧠
Check out the Paper👉 https://t.co/DPXJzFTrC7
See you there!
We are really excited to announce that we will be joined by @tavilyai for our Webinar Series this Tuesday!🤩
RSVP👉 https://t.co/A5DWx3v657
In this session, we'll explore how Tavily API makes search engine optimised for LLMs and RAG, to provide efficient, quick, and persistent search results. We'll also showcase Unify's SSO integration with Tavily 🧠🧑💻
Checkout Tavily:
⚡️https://t.co/09HUAktlpM
⚡️https://t.co/He5lk2TEae
We are really excited to welcome @sh_reya from @Berkeley_EECS, who co-authored the paper "Aligning LLM-Assisted Evaluation of LLM Outputs with Human Preferences". Happening Tomorrow! 🤩
RSVP 👉https://t.co/7DERN45vZ3
The research introduces EvalGen, an interface that provides automated assistance in generating evaluation criteria and implementing assertions🧠👩💻
Check out the Paper👉 https://t.co/13yCWyIUjv
See you there!







![DanielLenton1's tweet photo. In the end, I think agents will stream output actions continously. Think @thinkymachines interaction models but not only streaming speech and vision, but also streaming output control actions.
This will also be end-to-end trained in the model weights, but I wonder how far you could get today by stitching something together with @livekit etc., with computer use models outputting high level actions and faster models outputting the micro-steps. This is kind of how we've done things in unity [https://t.co/pTyu36D86Z], but for now we only stream the speech and vision at the high-frequency conversational layer (not yet actions).
In the end more of the harness will move to end-to-end training, and harnesses are a point-in-time solution to what will inevitably become an end-to-end trained system with latent representations at the boundaries instead of text etc.](https://pbs.twimg.com/media/HJqgIkDWUAAr0Nl.jpg)