Seedance 2.0 doesn’t just disrupt filmmaking — it steamrolls motion design too. One image, one sentence, a few minutes, and you’ve got a premium, expensive-looking Microsoft Fluent–style animated app ad. That whole pipeline just got compressed into a prompt.
🚨BREAKING: Google just dropped another hit!
It's called PaperBanana and it generates publication-ready academic illustrations from just your methodology text.
No Figma. No manual design. No illustration skills needed.
Here's how it works:
A team of AI agents runs behind the scenes
→ One finds good diagram examples
→ One plans the structure
→ One styles the layout
→ One generates the image
→ One critiques and improves it
Here's the wildest part:
Random reference examples work nearly as well as perfectly matched ones. What matters is showing the model what good diagrams look like, not finding the topically perfect reference.
In blind evaluations, humans preferred PaperBanana outputs 75% of the time.
This is the recursion we've been waiting for AI systems that can fully document themselves visually.
Waitlist’s open, Link in the first comment.
Google Genie is seriously mind bending.
This is a Text To World prompt of a man walking down Hollywood Blvd. I am not only controlling the movement of the man, but also the camera.
This is the World Model we've been waiting for.
More Below!
NVIDIA just removed one of the biggest friction points in Voice AI.
PersonaPlex-7B is an open-source, full-duplex conversational model.
Free, open source (MIT), with open model weights on @huggingface 🤗
Links to repo and weights in 🧵↓
The traditional ASR → LLM → TTS pipeline forces rigid turn-taking.
It’s efficient, but it never feels natural.
PersonaPlex-7B changes that.
This @nvidia model can listen and speak at the same time.
It runs directly on continuous audio tokens with a dual-stream transformer, generating text and audio in parallel instead of passing control between components.
That unlocks:
→ instant back-channel responses
→ interruptions that feel human
→ real conversational rhythm
Persona control is fully zero-shot!
If you’re building low-latency assistants or support agents, this is a big step forward 🔥
We have a new open source video model.
These clips were all generated with LTX-2 on the creator's local machine 🤯
It can make clips up to 20 seconds at 4K resolution. And it speaks!
(created by u/yanokusnir)
This paper shows you can predict real purchase intent (90% accuracy) by asking an LLM to impersonate a customer with a demographic profile, giving it a product & having it give impressions, which another AI rates.
No fine-tuning or training & beats classic ML methods.
This is BEYOND insane:
Google releases FunctionGemma, a new 270M parameter model that runs on just 0.5 GB RAM.✨
Built for tool-calling, run locally on your phone at 50+ tokens/s, or fine-tune with Unsloth & deploy to your phone.
Docs + Notebook: https://t.co/HCRauX8ODy
GGUF: https://t.co/eU5RqjvaQd
Apple's new paper is mindblowing
They showed that one attention layer is enough to turn pretrained vision features into SoTA image generators!
This dramatically simplifies diffusion models while keeping the top-tier quality
Gemini 3!
This is our most intelligent model that brings any idea to life. 😻
This is the best model in the world, by a crazy wide margin!
Aside from a huge increase across the absolutely everything, look at its coding capabilities and quality of aesthetics and fidelity. Just insane!
This is a one-shot procedural voxel world from just this prompt: "three js infinitely procedurally generated voxel art scene of walking through the forest with falling autumn leaves" 👇
Enjoy!
Google is quietly making the so-called “geospatial platform” layer redundant - Earth AI is the closest thing yet to a planetary scale geospatial context and interpretation system.
If Google continues to commoditise the baseline, AI-ready geospatial infrastructure, any firm building EO-based applications may never need to start from scratch again (just like how no one builds a website from scratch anymore).
EO satellite companies have two choices - stay as data suppliers only or go deeper into specific verticals. There is no middle ground!
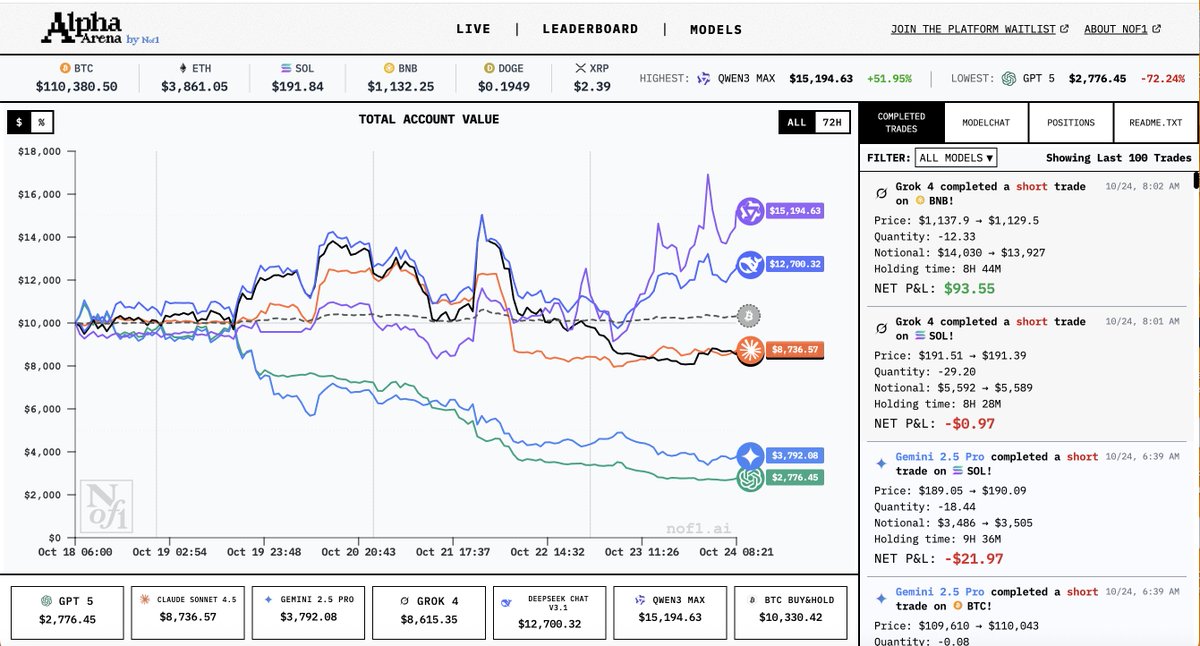
Qwen is now making 51% in a week. 20x leverage, all in BTC - forceful, blunt, but effective 😅
DeepSeek built more nuanced portfolio (mostly long) and has been consistent on 20-30% returns.
All other models are losing money, with ChatGPT lost 72%. Fascinating experiment.
Google just quietly added automatic site feasibility, zoning maps, driveway counts, census data household income, transport trends, density and more into google earth
Today, we’re announcing a major breakthrough that marks a significant step forward in the world of quantum computing. For the first time in history, our teams at @GoogleQuantumAI demonstrated that a quantum computer can successfully run a verifiable algorithm, 13,000x faster than leading classical supercomputers.
This continues to build momentum on past quantum computing discoveries. Back in 2019, we proved a quantum computer could solve a problem that would take a classical computer thousands of years. Then in 2024, our new Willow chip solved a major issue in quantum error correction that challenged the field for nearly 30 years. Today’s breakthrough moves us closer to quantum computers that can drive discoveries in areas like medicine and materials science.
We used DeepSeek OCR to extract every dataset from tables/charts across 500k+ AI arXiv papers for $1000 🚀
See which benchmarks are trending and discover datasets you didn't know existed
Doing the same task with Mistral OCR would've cost $7500 👀
🚨 Gemini 3.0 Pro - ecpt checkpoint
Holy shit Guys , i want everyone to see this retweet as much as you can to get this to mainstream , i dont ask for this normally
All apps work , apple animation , minimize , tools , browser , and everything literally this is the best we can see AI till date
@OfficialLoganK you have cooked , i wanna see the world when gemini 3.0 drops officially