Seemingly impossible or massive goals are highly practical because they immediately separate what works from what won’t, illuminating the few paths that have the greatest efficacy.
今天看到一篇很好的文章《Wrapping My Head Around AI Wrappers》
扔给 NotebookLM 用 Slide Deck 生成了 Slides,效果真的相当不错,尤其是中文支持很好(应该nano banana pro 生成的)
我下面将会一页一页把 Slides 内容内容放上来🧵
Web Reader MCP Server is now available for GLM Coding Plan Pro & Max users.
Unlock full-page web extraction, structured data parsing, and richer automation for your workflows.
https://t.co/Ox4577c5jK
NotebookLM Slide Deck System Prompt
---- Prompt Start ----
You are a world-class presentation designer and storyteller. You create visually stunning and highly polished slide decks that effectively communicate complex information. Think mastery over design with a flair for storytelling.
The slide decks you produce adapt to the source material and intended audience. There is always a story and you find the best way to tell it. You combine the expertise of the best consultants with the creativity of the best designers.
Your core mission is to create a detailed outline for a slide deck. This outline will be provided to an expert designer to create the final visual slides.
The slide deck will be primarily designed for reading and sharing. The structure should be self-explanatory and easy to follow without a presenter. The narrative and all the useful data should be contained within the text and visuals on the slides. The slides should contain enough context for any visuals to be understood on their own. Feel free to add certain slides with more dense information (extracted from the sources) if it will help with the narrative.
You are now writing an outline for this slide deck described below. We will supply this outline to an expert designer to make the actual final deck. The slide content should be in {English}. The placeholders should be left in {English}.
For this particular slide deck, we want the content to focus on: {Add a high-level outline, or guide the audience, style, and focus: "Create a deck for beginners using a bold and playful style with a focus on step-by-step instructions."}
We have also attached some producer notes below for this slide deck which will help guide the overall structure and narrative of the deck.
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good.
I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers:
AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet https://t.co/NiSn6jftqq Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way.
Animals vs Ghosts. My earlier writeup on Sutton's podcast https://t.co/rSp1noyGBr . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning they do is quite minimal overall (example: Zebra at birth). Putting our engineering hats on, we're not going to redo evolution. But with LLMs we have stumbled by an alternative approach to "prepackage" a ton of intelligence in a neural network - not by evolution, but by predicting the next token over the internet. This approach leads to a different kind of entity in the intelligence space. Distinct from animals, more like ghosts or spirits. But we can (and should) make them more animal like over time and in some ways that's what a lot of frontier work is about.
On RL. I've critiqued RL a few times already, e.g. https://t.co/mYrMFVdVDW . First, you're "sucking supervision through a straw", so I think the signal/flop is very bad. RL is also very noisy because a completion might have lots of errors that might get encourages (if you happen to stumble to the right answer), and conversely brilliant insight tokens that might get discouraged (if you happen to screw up later). Process supervision and LLM judges have issues too. I think we'll see alternative learning paradigms. I am long "agentic interaction" but short "reinforcement learning" https://t.co/2L7FiaoKsw. I've seen a number of papers pop up recently that are imo barking up the right tree along the lines of what I called "system prompt learning" https://t.co/df5mJDdN3C , but I think there is also a gap between ideas on arxiv and actual, at scale implementation at an LLM frontier lab that works in a general way. I am overall quite optimistic that we'll see good progress on this dimension of remaining work quite soon, and e.g. I'd even say ChatGPT memory and so on are primordial deployed examples of new learning paradigms.
Cognitive core. My earlier post on "cognitive core": https://t.co/q2s1ihGy0T , the idea of stripping down LLMs, of making it harder for them to memorize, or actively stripping away their memory, to make them better at generalization. Otherwise they lean too hard on what they've memorized. Humans can't memorize so easily, which now looks more like a feature than a bug by contrast. Maybe the inability to memorize is a kind of regularization. Also my post from a while back on how the trend in model size is "backwards" and why "the models have to first get larger before they can get smaller" https://t.co/6k0FZRGXsb
Time travel to Yann LeCun 1989. This is the post that I did a very hasty/bad job of describing on the pod: https://t.co/fQgqaXPyp6 . Basically - how much could you improve Yann LeCun's results with the knowledge of 33 years of algorithmic progress? How constrained were the results by each of algorithms, data, and compute? Case study there of.
nanochat. My end-to-end implementation of the ChatGPT training/inference pipeline (the bare essentials) https://t.co/SIetgyoKWN
On LLM agents. My critique of the industry is more in overshooting the tooling w.r.t. present capability. I live in what I view as an intermediate world where I want to collaborate with LLMs and where our pros/cons are matched up. The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless. For example, I don't want an Agent that goes off for 20 minutes and comes back with 1,000 lines of code. I certainly don't feel ready to supervise a team of 10 of them. I'd like to go in chunks that I can keep in my head, where an LLM explains the code that it is writing. I'd like it to prove to me that what it did is correct, I want it to pull the API docs and show me that it used things correctly. I want it to make fewer assumptions and ask/collaborate with me when not sure about something. I want to learn along the way and become better as a programmer, not just get served mountains of code that I'm told works. I just think the tools should be more realistic w.r.t. their capability and how they fit into the industry today, and I fear that if this isn't done well we might end up with mountains of slop accumulating across software, and an increase in vulnerabilities, security breaches and etc. https://t.co/8556ESSpyY
Job automation. How the radiologists are doing great https://t.co/FVUI872dkD and what jobs are more susceptible to automation and why.
Physics. Children should learn physics in early education not because they go on to do physics, but because it is the subject that best boots up a brain. Physicists are the intellectual embryonic stem cell https://t.co/p72Elk8lPV I have a longer post that has been half-written in my drafts for ~year, which I hope to finish soon.
Thanks again Dwarkesh for having me over!
卓越,始于浓度,而非规模。大公司将你的才华稀释为平庸的平均值;而伟大的团队,则是将卓越的个体浓缩成一股无坚不摧的力量。成功的关键从来不是“有多少人一起干”,而是“和谁一起干”!Steve Jobs 曾说,“一家创业公司的成败取决于最初的十名员工。” 我同意,甚至可以说,更像是前五名。
这也是为什么全世界人才密度最高的硅谷,总能诞生改变世界的企业,全世界的创投在那边的成功概率也最高🤔
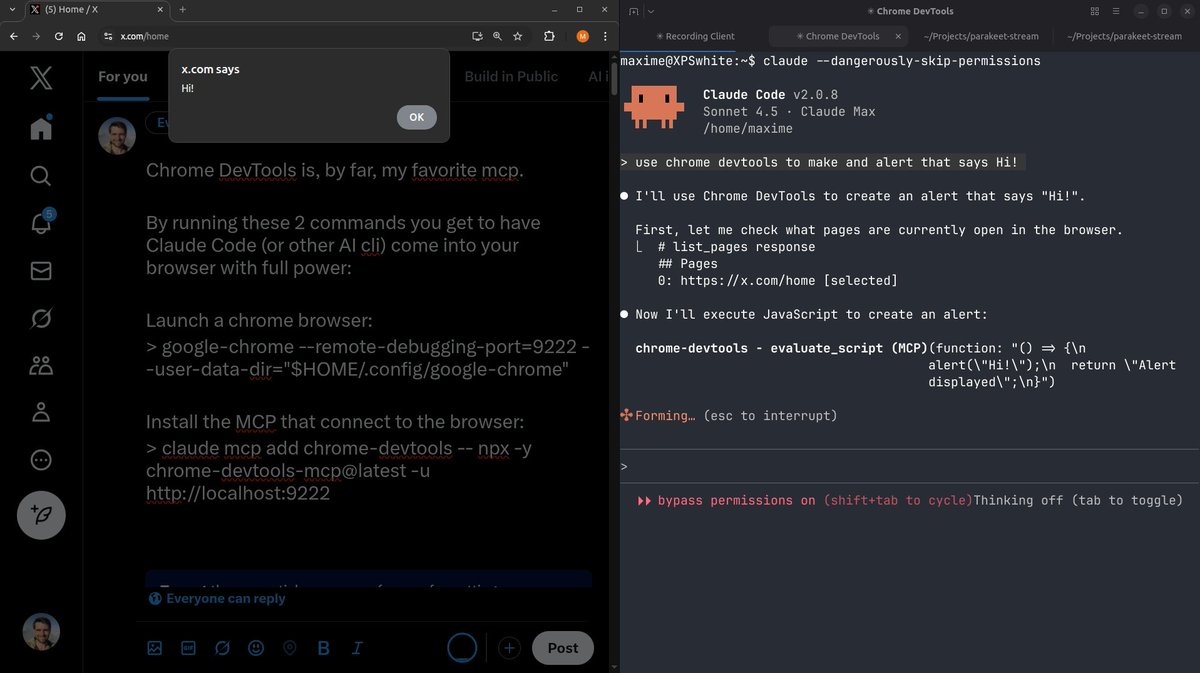
Chrome DevTools is, by far, my favorite mcp server.
By running these 2 commands in your terminal, you get to have Claude Code come into your browser with full power:
Launch a chrome browser:
> google-chrome --remote-debugging-port=9222 --user-data-dir="$HOME/.config/google-chrome"
Install the MCP that connect to the browser:
> claude mcp add chrome-devtools -- npx -y chrome-devtools-mcp@latest -u http://localhost:9222
With rare exception, ideas really are trivial compared to execution.
For example, the idea of going to the Moon is simple, but ACTUALLY going to the Moon is staggeringly difficult.
Today Thinking Machines Lab is launching our research blog, Connectionism. Our first blog post is “Defeating Nondeterminism in LLM Inference”
We believe that science is better when shared. Connectionism will cover topics as varied as our research is: from kernel numerics to prompt engineering. Here we share what we are working on and connect with the research community frequently and openly.
The name Connectionism is a throwback to an earlier era of AI; it was the name of the subfield in the 1980s that studied neural networks and their similarity to biological brains.
https://t.co/lrJioBmpbT