Robostral can now follow natural language instructions. It responds to voice commands and pointing. It is also getting better at fine-grained manipulation where precise force control matters. It generalizes to new objects and tasks not present in the training data.
NEW RELEASE:
Today we're releasing CortexMAE: a family of fMRI foundation models trained on 2.1K hours of open fMRI data.
We're also releasing Brainmarks: an open benchmark suite for evaluating fMRI foundation models.
Full paper is on arXiv (accepted to ICML 2026)
A thread:
Would you like to join the research effort on JEPA and World Models easily?
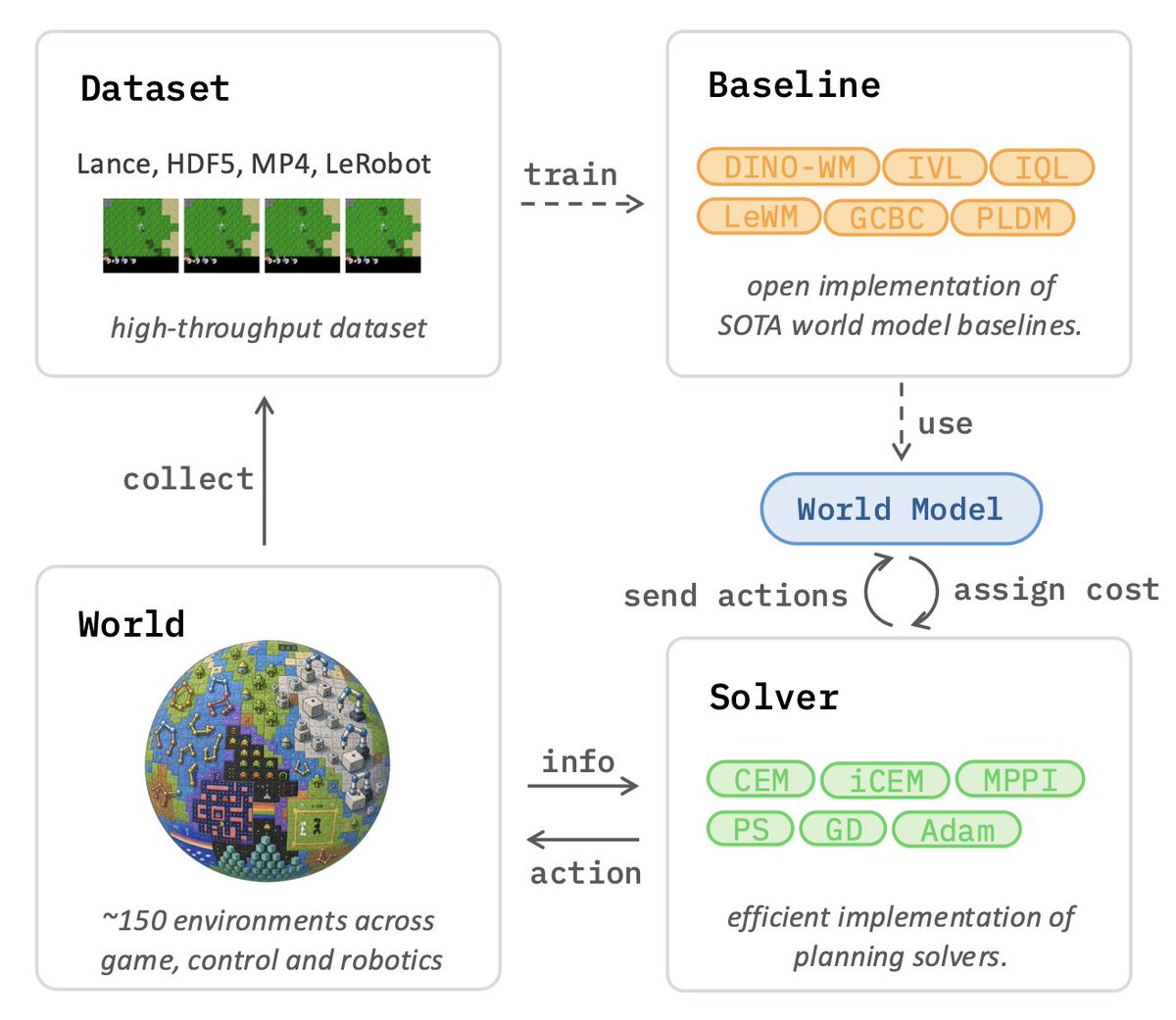
After a full year of hard work, we’re excited to finally release stable-worldmodel:
an open-source, scalable platform built to accelerate JEPA & World Model research!
📄: https://t.co/gnxGvens5A
Introducing the newest Coral board, for efficient, on-device AI!
Check out the demos in the video:
- On-board speech translation
- Natural language controlling hardware
- Vision & sound generating music
new release for text-to-cad, an open source CAD harness and skills for codex / claude:
- mechanism validation (go from text prompt to functional mechanical design)
- parameters + animations for step files
- extended sdf, srdf, urdf support
3k stars, 10k downloads, we cooking
What hardware actually powers open-source AI?
Not benchmarks.
Not vendor marketing.
Real-world community usage.
We’re launching @huggingface Hardware:
→ trending GPUs & CPUs
→ VRAM distribution
→ inference hardware trends
→ what the OSS AI ecosystem really runs on
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Le #CERN rend open-source sa librairie de composants électroniques pour le logiciel KiCAD. Disponible via Gitlab, elle contient des données pour plus de 17000 composants électroniques, y compris des symboles schématiques et des empreintes de circuits.
https://t.co/BJvm3mtp7O
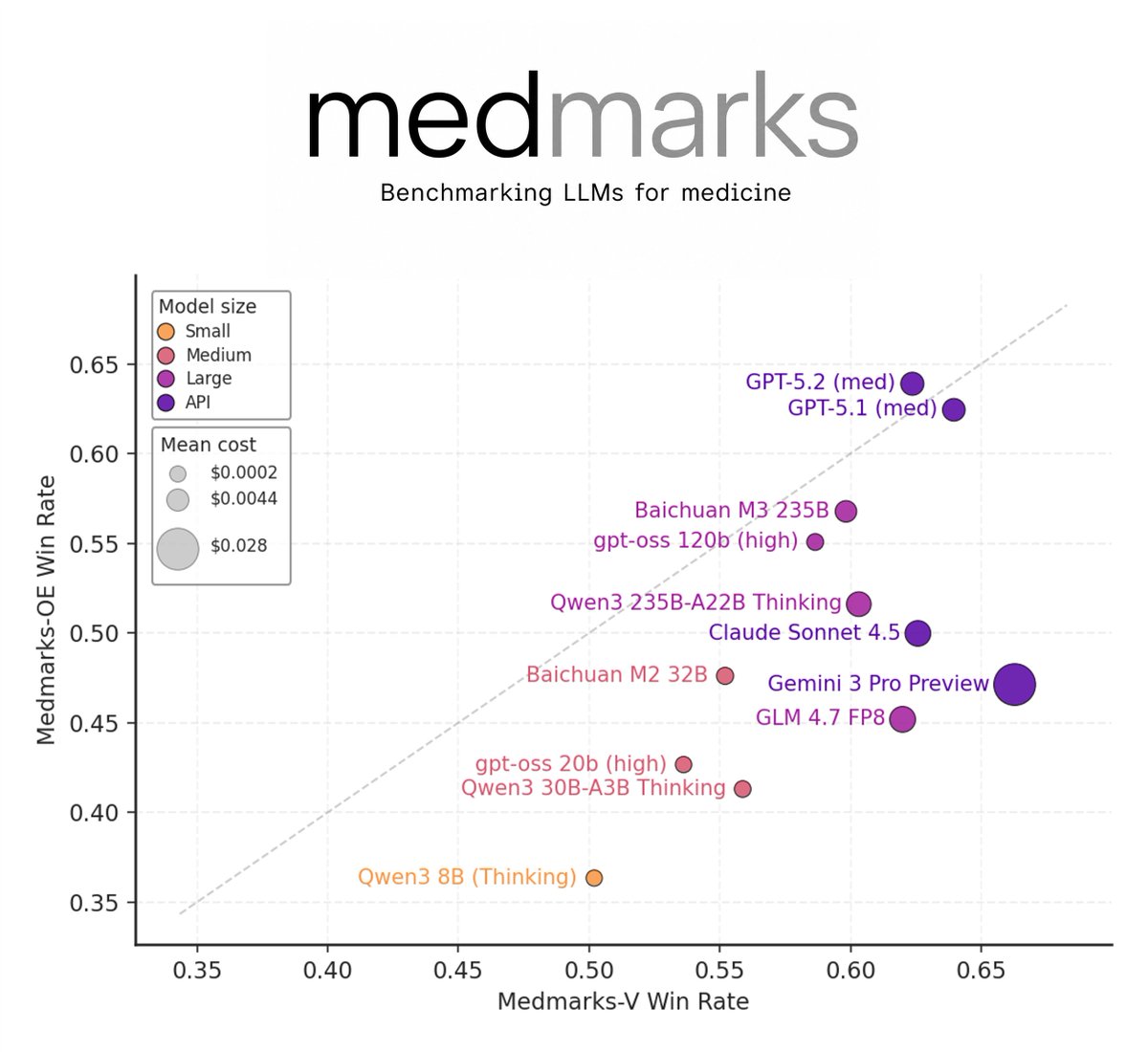
We're excited to release Medmarks v1.0 + a technical report!
This is an update to our Medmarks benchmark suite, the largest open-source automated suite for evaluating the medical capabilities of LLMs.
We added 10 benchmarks (20→30) and 15 models (46→61) to the leaderboard!
DS4 running on DGX Spark (GB10 / CUDA), private branch for now. 12 tokens/sec, the memory bandwidth is limited in this system, at 270GB/sec. But prefill is ways more alighed to M3 Max at ~200 t/s. I'll release when more mature, but it is almost sure that it will get merged.
I wrote Deep Learning with Python to be the definitive guide to how deep learning works and how to best make use of it. Tens of thousands of people got their career start via this book. 120,000 copies sold, and downloaded by millions more.
And now it's free to read online: https://t.co/3CbcQ7hmjp
Just updated our paper on on-device LLMs for clinical decision support.
Paper: https://t.co/c4O4KQFocz
Here's why I think this matters:
We've been asking the wrong question. The debate around LLMs in medicine has been "how accurate are
they?", but the harder problem is deployment. Patient data can't leave the hospital. Most clinics don't have the bandwidth or budget for cloud inference at scale. The real question is: can a model that runs locally, on modest hardware, actually be trusted for clinical decisions?
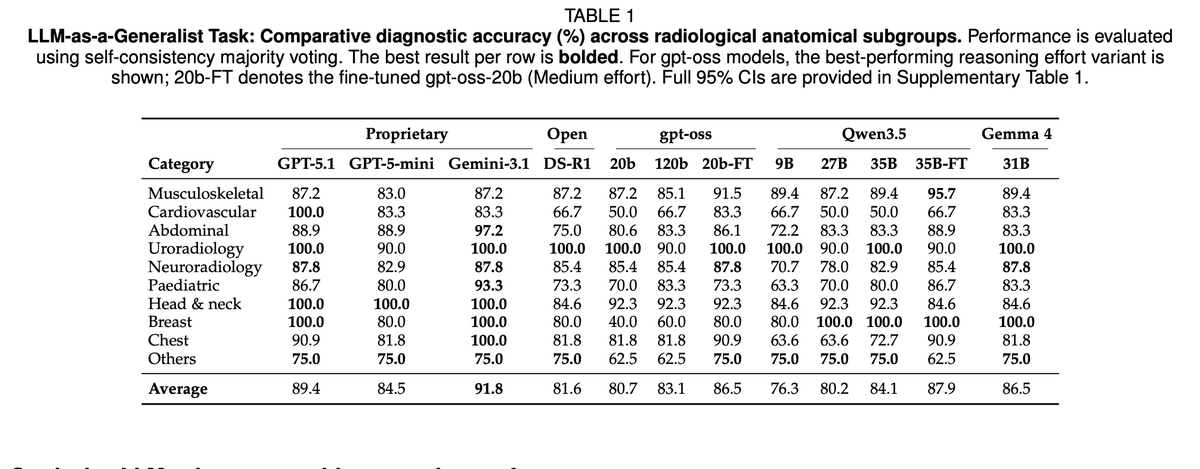
After benchmarking 188 models across general disease diagnosis, ophthalmology, and clinical judgment simulation — the answer is yes.
Gemma 4 31B (@googlegemma) hits 86.5% on general diagnosis, beats GPT-5-mini, scores 100% on uroradiology and breast imaging, and runs at 18 GB. Qwen3.5-27B (@Alibaba_Qwen ) at 16 GB matches DeepSeek-R1 at 671B, that is one-twenty-third the memory, same clinical accuracy. Fine-tune Qwen3.5-35B with domain-specific reasoning traces and it reaches 87.9%, approaching GPT-5.1 (89.4%). No extra memory. No cloud call. No PHI leaving the building.
One thing that surprised me: 87.2% of errors across all models were clinically plausible differentials. the model picked a reasonable diagnosis, just not the right one. Above ~31B parameters, hallucination rate drops to zero. Errors start looking like the kind a careful clinician makes on a hard case, not the kind that would make you distrust the system.
There's also a pass@3 upper bound of 93.2% for fine-tuned Qwen3.5-35B. The model already "knows" the right answer in most cases. That's a verifier problem, not a model-size problem.
Gemma 4 and Qwen3.5 are the first generation where the local deployment story actually holds up under rigorous clinical benchmarking. That's a real milestone.
Huge shoutout to the team who made this happen: Alif Munim (@alifmunim ), Omar Ibrahim, Alhusain Abdalla, Jun Ma @JunMa_AI4Health (all equal contributors), Meng Wei, Shuolin Yin, and Leo Chen from @UHN AI hub. Proud of what this group built 🔥🔥
🤗🤗🤗introducing Hugging Science -- the home of AI for science 🤗🤗🤗
open models and datasets are the powerhouse of science (see the PDB), but finding the models and data you actually need for your breakthrough is hard af
you shouldn't need to scrape arxiv, own your own wetlab, fight a custom HDF5 parser, build a fusion stellarator, and beg for compute before you've trained a single epoch
so we're changing that
we've put all the best science on @huggingface in one place:
- 78GB of genomics data
- 11TB of PDE simulations
- 100M cell profiles
- 9T DNA base pairs
- 13M molecular trajectories
- 400k medical QA pairs
and much more, all open, and all ready for training (+ you can also now filter and search by domain, task, and keyword)
we've put together all the biggest releases from our partners at NASA, Google, OpenAI, Meta FAIR, Arc Institute, Ginkgo, SandboxAQ, Proxima Fusion, NVIDIA, Ai2, OpenADMET, InstaDeep, Future House, Polymathic AI, LeMaterial, Earth Species Project, Merck, and Eve Bio
if you're not sure where you fit in -- work on open challenges for problems that matter: including fusion stellarator design, ADMET, antibody developability, multilingual medicine, catalysis and materials, and scientific reasoning.
we're already changing how science gets done:
a fusion startup needed a benchmark for stellarator plasma confinement that didn't exist. @proximafusion shipped ConStellaration on Hugging Science: a leaderboard, dataset, and eval metrics, all in one place.
a drug discovery team wanted to predict hPXR induction. OpenADMET put up a blind challenge: 11,000+ compounds assayed at Octant, 513 held out, two tracks (pEC50 + structure). Anyone in the world can train and submit.
an antibody team at @Ginkgo released GDPa1, a developability dataset for stability, manufacturability, and immunogenicity prediction, with a live leaderboard scoring every submission.
if you know a problem the ML community should be working on, let us know. make a challenge! this is about putting all the tools for solving science in one place. so we can hillclimb!
→ https://t.co/T4l4r1lDz0
Welcome @anthropicai as a Corporate Patron sponsor of the Blender Foundation’s Development Fund! This support will be dedicated towards general Blender core development. More details at https://t.co/oiQeATUVW3 #b3d#DevFund