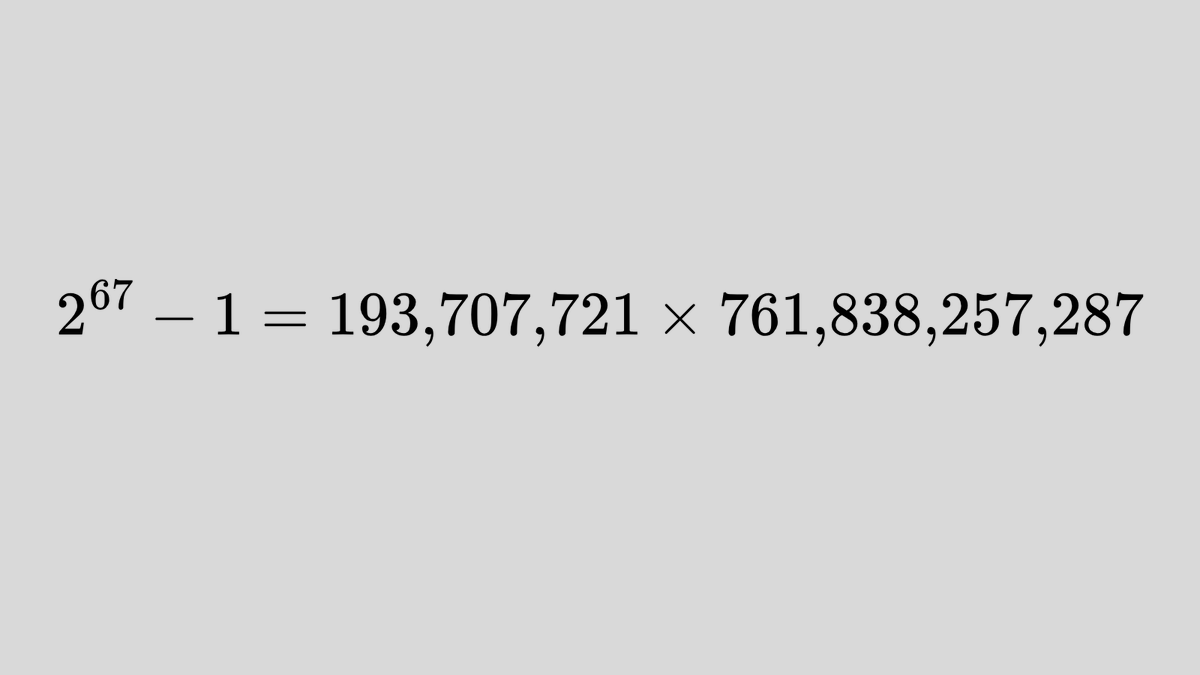Mathematician | I am a PhD candidate at @IIMAS_UNAM. I research some intersections between logic and computability | Professor at @FIUNAM_MX and @fciencias
The Calculus of Randomness: How Itô's Integral Tamed the Chaos of the Universe
There is a kind of mathematics that lives in the space between prediction and surprise. Not the clean, deterministic world of Newton — but the messier, more honest world where stock prices jump without warning, molecules collide in a fog, and a robot learning to walk stumbles in ways no equation quite anticipated.
This is the world that Kiyoshi Itô decided to tame.
The Man Who Listened to Noise.
The year was 1944. The Second World War was grinding toward its end. Most mathematicians were occupied with ballistics, cryptography, or survival. Kiyoshi Itô, a young Japanese mathematician working at the Cabinet Statistics Bureau in Tokyo, was doing something almost whimsical by comparison: trying to make rigorous sense of random motion.
The problem had deep roots. In 1827, the Scottish botanist Robert Brownobserved pollen grains suspended in water moving in an erratic, jittery dance — not because they were alive, but because water molecules were bombarding them from all sides. Einstein and Smoluchowski later gave this Brownian motion a physical theory; Norbert Wiener gave it a rigorous mathematical one in the 1920s, constructing what we now call the Wiener process — a continuous random path that is nowhere differentiable. It wiggles so violently at every scale that it has no slope, no tangent, no derivative in the ordinary sense.
And this was the problem. Describing how a system evolves under randomness requires differential equations. But differential equations require derivatives. And Brownian motion has no derivative.
Itô's insight: what if we build a completely new kind of integral, designed specifically for functions of random processes? His landmark 1944 paper did exactly that, opening an entirely new branch of mathematics: stochastic calculus.
What Makes It Different?
In ordinary calculus, integration sums up infinitely many small pieces. The Riemann integral captures area under a curve; the Lebesgue integral handles even wildly irregular functions. Both assume the thing you're integrating is predictable enough to be approximated — and they work beautifully for smooth physics.
But integrate with respect to a Wiener process and you hit a wall. The Wiener process has infinite total variation: the total path length of a Brownian particle over any time interval is infinite. The path is so jagged that ordinary integration simply doesn't converge.
Itô's solution was to use left-endpoint approximations — always evaluating at the beginning of each time interval, before seeing what the random process does next. This encodes something conceptually deep: you're integrating from the perspective of someone who doesn't know the future. An investor. A controller. A learner.
This choice produces the crown jewel of stochastic calculus, Itô's Lemma:
df(X) = f'(X) dX + ½ f''(X) (dX)²
That second term — a curvature correction with no counterpart in ordinary calculus — is the signature of Itô's framework. Brownian fluctuations are so rapid that second-order terms survive in the limit. Randomness itself contributes to the drift. Classical intuition breaks here, deliberately.
The Equation That Priced a Trillion Dollars.
Itô's results sat quietly for nearly two decades, known only to a small community of probabilists. Then, in 1973, Fischer Black and Myron Scholes (building on Robert Merton) used Itô calculus to derive a formula for the fair price of a financial option. The Black-Scholes equation falls directly out of Itô's Lemma, with Brownian motion modeling random stock price fluctuations.
The result was not merely theoretical. It became the engine of the modern derivatives market — valued at hundreds of trillions of dollars at its peak. Black and Scholes received the Nobel Prize in Economics in 1997. Itô received the inaugural Gauss Prize in 2006, at age 90, for the mathematics underlying all of it.
Writing Physics in the Language of Noise.
Itô's framework allows us to write stochastic differential equations (SDEs) — equations of motion that explicitly include random terms:
dX = μ(X, t) dt + σ(X, t) dW
The drift μ captures the deterministic trend; the diffusion coefficient σ controls how much noise enters at each moment; dW is pure Gaussian randomness. This single equation describes the spread of heat in disordered media, the evolution of interest rates, gene regulatory networks, spacecraft dynamics, and neural firing — and now, increasingly, the behavior of learning algorithms.
Itô Calculus Enters the Machine.
- Diffusion Models and Generative AI:
The image generators, audio synthesizers, and video models of recent years are built on diffusion modeling — and the core idea is Itô calculus directly. In the forward process, a training image is gradually corrupted by Gaussian noise: a discretized Brownian motion. In the reverse process, a neural network learns to undo this corruption step by step, recovering sharp images from noise. The mathematical backbone is the Fokker-Planck equation and the theory of score-based generative models, both descendants of Itô's framework. The reverse-time SDE was made rigorous by Brian Anderson in 1982 using Itô calculus. Every modern diffusion model — DDPM, Score SDEs, consistency models — is, at its heart, an applied stochastic differential equation. When Stable Diffusion draws you an astronaut on a horse, it is solving an SDE backward in time.
- Stochastic Gradient Descent:
Training a neural network uses stochastic gradient descent (SGD) — weight updates computed on random mini-batches rather than the full dataset. The noise is not a bug; it often helps find better solutions. The continuous-time limit of SGD can be modeled as an SDE:
dθ = -∇L(θ) dt + σ(θ) dW
Itô calculus provides the tools to analyze this — explaining why higher learning rates can escape sharp minima, why mini-batch noise acts as an implicit regularizer, and how loss landscape flatness relates to generalization. This is an active research frontier, with groups at MIT, Stanford, and DeepMind regularly invoking SDEs and Fokker-Planck equations to explain why deep learning works.
- Reinforcement Learning:
When the action space is continuous — a robot joint, a rotor, a trading strategy — the natural framework is stochastic differential equations. Stochastic optimal control, built entirely on Itô calculus, produces the Hamilton-Jacobi-Bellman (HJB) equation, the cornerstone of optimal control theory, derived directly via Itô's Lemma. Every modern continuous-control RL algorithm is, mathematically, an approximation to solving an HJB equation. The exploration tools of RL — entropy regularization, Langevin dynamics — are also Itô's tools.
- Bayesian Deep Learning:
Stochastic gradient Langevin dynamics (SGLD) trains Bayesian neural networks by injecting Gaussian noise into gradient updates to mimic a Langevin SDE, achieving approximate Bayesian inference at scale. Its correctness is guaranteed by Itô calculus.
A Strange Beauty.
There is something philosophically striking about all this. Itô calculus is a mathematics built not around certainty, but around honest uncertainty — every evaluation made with respect to the information available right now, and not a shred more. This is perhaps why it is so naturally suited to learning systems, which are also, at their deepest level, about acting wisely under incomplete information.
Kiyoshi Itô spent his career at Kyoto University, living quietly and publishing with characteristic modesty. He died in 2008, at 93, having lived to see his 1944 paper become the foundation of finance, physics, and the nascent science of machine learning.
He once said he hoped his work would "find applications in many fields." The wish was granted — beyond anything he could have imagined, in a world wired with neural networks that owe their generative power, their training dynamics, and their capacity for uncertainty to the calculus of randomness he built alone, in a Tokyo office, while the world outside burned.
If you enjoyed this piece, consider subscribing for more long-form explorations of the mathematics and probability behind modern machine learning, deep learning, …
Primes look random but the Prime Number Theorem shows their count π(x) up to x grows asymptotically like x / ln(x).
The ratios π(x) / (x / ln(x)) and π(x) / ∫₂ˣ dt / ln(t), both approaching 1. This is formalized as lim_{x→∞} π(x) / ∫₂ˣ (dt / ln t) = lim_{x→∞} π(x) / (x / ln x) = 1.
It is used to estimate the number of primes available for generating cryptographic keys in RSA and similar systems.
The Logic Theorist was a computer program built by Herbert Simon, Allen Newell and Cliff Shaw. It's often called the first AI program.
It proved theorems from Principia Mathematica. For one theorem it found a proof shorter and more elegant than the one in the book. That program is 70 years old this year.
In 1903, Frank Nelson Cole, a professor of mathematics at Columbia University in New York, gave a rather curious talk at a meeting of the American Mathematical Society. Without saying a word, he wrote one of Mersenne’s numbers on one blackboard, and on another blackboard he wrote two smaller numbers and multiplied them together. Between them, he placed an equals sign—and then sat down. The audience rose to its feet and applauded, a rare outburst for a room full of mathematicians.
The Watts–Strogatz 'small world' paper was published on 4 June 1998.
In August 1998, I arrived at Cornell for my PhD, and there was so much excitement about this new paper and the rapid developments that followed. We had so many discussions about networks and complex systems.
Very excited to share our interview with @polynoamial on AI for math — the Erdős unit distance problem, saturating the IMO, the future of math research, and more!
Network visualization of the three-level hierarchical personality trait structure derived from Taxonomic Graph Analysis (TGA) of the IPIP-NEO inventory (N ≈ 149,000).
- The bottom level shows 28 narrow facets with dense empirical connections.
- The middle level displays six trait domains (Neuroticism, Sociability, Conscientiousness, Integrity, Openness to Experience, Impulsivity).
-The top level shows three meta-traits (Stability, Plasticity, Disinhibition).
Node colors correspond to the trait categories indicated in the legends; edges represent network-derived relationships across levels.
A mathematician at Bell Labs noticed that the scientists who won Nobel Prizes and the ones who never amounted to anything were equally smart, equally hardworking, and equally credentialed, and the only thing that separated them was a single question almost nobody is brave enough to ask themselves before they die.
His name was Richard Hamming.
He spent 30 years at Bell Labs, in the same building as John Tukey, Walter Brattain, and a long list of physicists who took home Nobel prizes for work they did down the hall from his office, including the legendary Claude Shannon.
His invention of error-correcting codes made modern computing possible. He has won the Turing Award. And all the while he was creating his own legacy he was secretly doing a study on the people around him.
The study was straightforward. 2 Teams. The legends and the lost. Same I.Q.s. Degrees same. Same desk hours. Same access to the world’s best resources.
And yet, at the end of 40 years in their careers, one group had changed entire fields, and the other group could not be remembered by their own colleagues five years after retirement. He wanted to discover what the actual difference was.
In March 1986, he stood before 200 researchers in a Bellcore auditorium and told them what he had seen.
He said it all came down to one question. And hardly anyone he ever met was willing to ask it directly.
He called it the Friday-afternoon ritual. He spent years blocking out his Friday afternoons and not doing anything productive with them every week. No experiments. No meetings. No deliverables.
He called it Great Thoughts Time. He sat down with a notebook and asked himself a couple of questions in order. What are the most relevant problems in my discipline? And why I am not working on either of them.”
Most weeks, the answer was the same, he said. For a week now he had marched confidently in a direction he did not think was the most important direction. He was a goer. He worked a bit. He was getting clean results that would publish in respected journals. (
And for five days straight he'd been lying to himself about whether any of it mattered.
The reason almost nobody does this ritual is because the honest answer is unbearable. The thing is that if you sit down on a Friday afternoon and say out loud that you are not working on the most important problem in your field, now you have to do something about it.
You have an immediate change in direction, or you have to keep lying to yourself every week from that point on. Most people choose the lie.
In the short term it’s cheaper, but over a career it’s more expensive.
Hamming took the ritual a step further in the Bell Labs cafeteria. He began approaching scientists he barely knew, asking them what they thought the most important problems in their field were.
A week later he would ask them why they had not worked on these problems. Eventually people wouldn't have lunch with him. “I had to keep finding new tables,” he said.
Nobody had a good answer for that, and being around someone who kept asking it made every meal feel like a performance review.
The line that broke me is the line that most people skim over in the transcript. His words: If you do not work on an important problem you are unlikely to do important work.
That’s not motivational line. It is a rational one. You cannot make a great result from a problem that does not matter. Input restricts the output. The choice of the problem is the ceiling of the career.
The transcript has been freely available on the internet for almost 40 years. Stripe Press published the complete lectures as a book. Naval Ravikant quotes it all the time. It’s still given out to new hires at every serious engineering lab in Silicon Valley.
Most people will not run the ritual this Friday. They will be busy. They always are.
Alexander Grothendieck, seen here in 1954, was fascinated by hidden geometric structure. “If there is one thing in mathematics which fascinates me more than any other (and undoubtedly always has), it is neither ‘number’ nor ‘size,’ but invariably shape,” he wrote. Mathematicians are still grappling with the innovations he made half a century ago.
https://t.co/sRyENekMY5
I would recommend anything written by the great Yuri Manin, therefore, today, I will suggest you to read this fantastic paper (29 pages) titled 'The Notion of Dimension in Geometry and Algebra'.
In this one, Manin marries mathematics, physics, philosophy, history and much more, a refreshing read, for those used to dry formalism.
Yuri's view on mathematics deeply influenced mine, so give it go, I bet you'll like too.
Today, we share a breakthrough on the planar unit distance problem, a famous open question first posed by Paul Erdős in 1946.
For nearly 80 years, mathematicians believed the best possible solutions looked roughly like square grids.
An OpenAI model has now disproved that belief, discovering an entirely new family of constructions that performs better.
This marks the first time AI has autonomously solved a prominent open problem central to a field of mathematics.
The mathematician Alexander Grothendieck is revered in the world of math; outside of it, he’s known for his unusual life, if he’s known at all. But what were his actual mathematical contributions?
https://t.co/umGPWwJ6HC
At age 25, Kurt Gödel proved there can never be a mathematical “theory of everything.” In this week’s Qualia column, @nattyover asks experts how his ideas changed the course of humanity’s unending search for truth. https://t.co/UVDtVlYJkZ
If you've been struggling learning category theory, you might want to check out Paolo Perrone's 'Notes on Category theory: with examples from basic mathematics' available publicly on arXiv.
These notes were produced during a class given to a diverse set of scientists (including chemists and physicists), with knowledge in linear algebra being the only subject assumed to be known!
🔗👇
Ex-MIT researcher Isaak Freeman quits his PhD and drops the 50,000 H100 GPU roadmap to emulate a full human brain.
He mapped the entire path from 302-neuron worm to 86-billion-neuron human with connectomics costs now at 100 dollars per neuron and data acquisition via advanced microscopes as the only blocker left - digital humans just got a realistic timeline.
https://t.co/kGB5hOAQHC
Only one chance in this lifetime…
Like watching sunset at the beach from the most foreign seat in the cosmos, I couldn’t resist a cell phone video of Earthset. You can hear the shutter on the Nikon as @Astro_Christina is hammering away on 3-shot brackets and capturing those exceptional Earthset photos through the 400mm lens. @AstroVicGlover was in window 3 watching with @Astro_Jeremy next to him.
I could barely see the Moon through the docking hatch window but the iPhone was the perfect size to catch the view…this is uncropped, uncut with 8x zoom which is quite comparable to the view of the human eye. Enjoy.
How Feynman knew if he actually understood something:
"When I was in high school, I'd see mathematical processes that people used and I'd wonder if I could derive them from scratch. If I couldn't, I didn't understand them. I only understood something when I could build it back up from nothing."
That one sentence exposes why most people confuse familiarity with knowledge.
Here's the technique he actually used.
Feynman kept a notebook. Not for notes. For tests.
Every time he learned something new, he'd close the book, pick up a blank page, and try to explain the idea from scratch in plain language. No jargon. No formulas until he understood what the formula was actually doing. No borrowed phrases from the textbook.
If he got stuck, he didn't consider that failure. He considered it data. The exact spot where he got stuck was the exact edge of his understanding.
Then he'd go back, fill that specific gap, and try again.
He called it the difference between knowing the name of something and knowing something. Most education, he believed, was teaching people an enormous number of names. The names felt like knowledge. They weren't.
A physicist who couldn't explain quantum tunneling to a curious child didn't understand quantum tunneling. They had memorized a description of it. Those are completely different things, and the gap between them is where most people live permanently without realizing it.
The uncomfortable implication is this: the subjects where you feel most confident are often the ones most worth testing. Confidence and understanding are not the same signal. Confidence is what familiarity feels like from the inside.
The Feynman Technique is not a study hack. It's a diagnostic tool.
Run it on anything you think you know. The blank page will tell you the truth faster than any exam ever could.
If you can build it from nothing, you own it.
If you can't, you've only borrowed it.