Neural PDE solvers have seen exciting progress! 🌊
But despite growing adoption, we still don’t know 𝘄𝗵𝗲𝗻 we should use them instead of classical solvers. 🤔
Our new paper has a surprising finding: the harder the PDE task, the more cost-effective learned solvers become. 🧵👇
After interviewing for Research Scientist roles at DeepMind, Isomorphic, Meta, Cohere and more, I wrote up everything I learned. Technical prep, logistics, negotiation, and emotional breakdowns. Check out my guide: https://t.co/eLh20ggMHW
1/ NEW PAPER. Why do larger networks train better?
"Because they contain more candidate subnetworks that can learn the task" → lottery tickets
This explanation uses an appealing but misleading metaphor🧵
We propose an intuitive alternative grounded in theory: escape dimensions
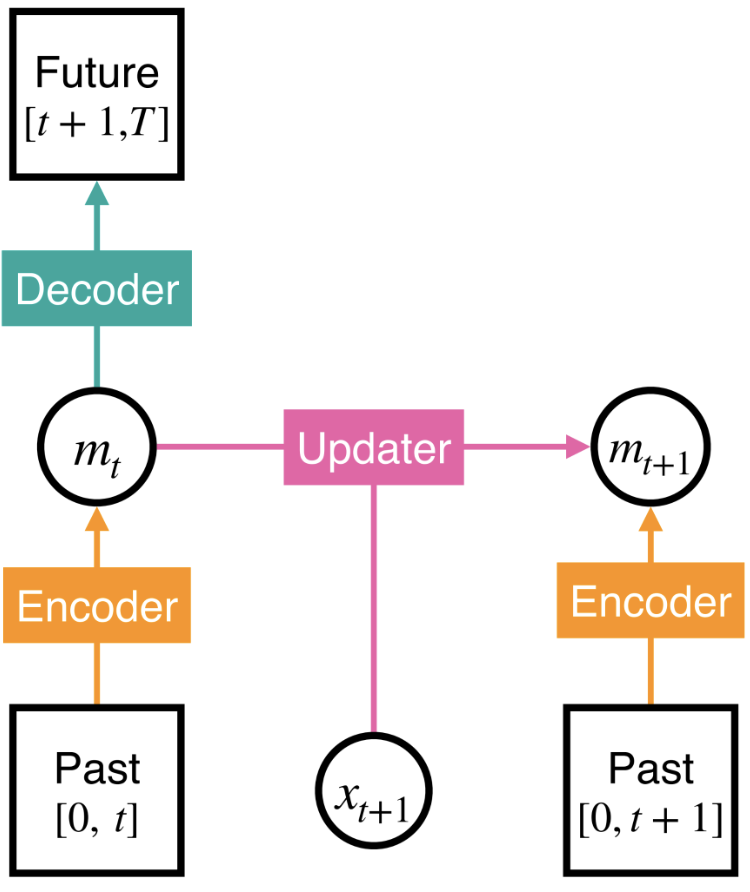
What should be remembered: a compressed representation of the past that predicts the future (predictive state).
How to update memory: predict the next predictive state.
We never really knew how to train nonlinear RNNs well… BPTT struggled with vanishing grads (no long-range memory) and sequential rollout (hard to parallelizable).
What if instead an oracle told us the optimal memory state m_t at each step? Then the RNN could do one-step supervised learning on (m_t, x_{t+1}) → m_{t+1} labels.
We call this Supervised Memory Training (SMT): a replacement for BPTT that trains RNNs without unrolling them. SMT is time-parallelizable and solves vanishing gradients.
Website: https://t.co/BvctWJlPad
arXiv: https://t.co/5xR0mUVymp
This might explain why REPA works: aligning DiT representations to DINOv2 may just be helping the model form these morphogen-like spatial gradients earlier and cleaner. One injects good representations, the other reveals them — same coin, two sides. Going further — what's the principle behind RAE?🤔
For the past years my research focus was on unifying models and training paradigms across modalities. Today I'm excited that we're releasing our latest model aligned with this theme:
Gemma 4 12B, a dense encoder-free model which processes raw text, image, and audio inputs!
1/
On-Policy Distillation is the most active new research direction being explored in RL for LLMs. Had the chance to discuss how it works with Dwarkesh and why it fits so nicely into large-scale pipelines.
For the past two years we've studied a decades-old problem in fluid dynamics: why do some turbulent systems grow 3x faster in the real world than simulations predict?
With some tabletop fluids experiments and a physics foundation model, we finally have some results!!!
👇
Introducing Strong Stochastic Flow Maps
TLDR: Stochastic Flow Maps where we learn the stochastic solution path.
Work led by Sam McCallum, @zwblasingame, with Timothy Herschelll, @AlexanderTong7, and @JamesFosterBath
Arxiv: https://t.co/Hy8WWZOnjE
Code: https://t.co/PMe6RoqyZA
For me, the coolest finding is that Muon optimizer is crucial for Parallax to move beyond Softmax Attention.
Lesson — don't evaluate new architectures solely under AdamW, you'll miss the good ones.
paper: https://t.co/yAqClXrJUz
code: https://t.co/D4pgIr1wM7
For the origin of Parallax, check out the LLA paper at ICLR 2026:
paper: https://t.co/85OzoOQlnF
code: https://t.co/eqMYZ0U6qO
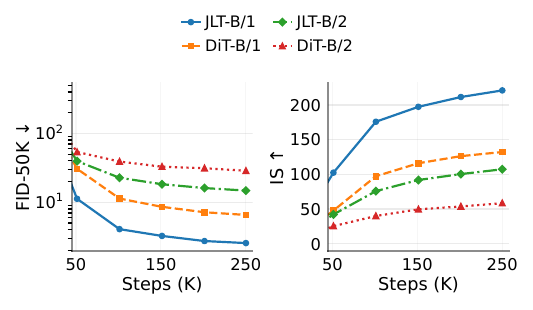
Everyone focused on JiT's move to pixel space. Today, JLT asks a different question:
Can the benefits of clean prediction survive entirely within latent space?
FID: 6.56 → 2.56✅ JLT learns to predict latent x directly, rather than velocity target v.
Check our JLT:🧵
"Learn from your own latents, not tokens: A Sample Complexity Theory"
This paper explains why data2vec and JEPA can learn with much less data.
They showed that when data has hidden hierarchy, token prediction becomes harder as the hierarchy gets deeper. But latent prediction keeps the learning problem simple at every level.
Which suggests that models may learn faster when they stop predicting raw tokens and start predicting their own abstractions.
really excited to finally release this one.
guidance is critical for getting flow and diffusion models to do what we want, but most methods in the literature are heuristic and work for unclear reasons. the field likes to frame it as reward-tilted sampling, yet what people run in practice is often nowhere close to that.
here we take a different angle, deriving guidance from first principles as an optimal control problem. existing methods drop out as coarse approximations, and the flow map emerges as the fundamental ingredient for effective guidance.
our approach is training-free, and reaches state-of-the-art performance across diverse benchmarks at up to 70x fewer NFEs.
amazing work by @jrrhuang, justin, kartik, and sheel.
stay tuned for more on the finetuning side!
For over a decade, we’ve accepted that end-to-end backprop is the only way to train deep networks. But holding the entire network in memory all at once is why AI training is hitting a resource wall.
We found a new way to break the network into blocks and train them independently. The trick? Treating the network’s forward pass like a diffusion model denoising a signal.
This reinterpretation slashes the memory needed to train deep models. In our #ICLR2026 paper (https://t.co/PK5h0mqQSo), we matched end-to-end performance across ViTs, DiTs, and LLMs. We did this while training just one isolated block at a time.