Un ingeniero de Netflix ha sacado algo tremendo.
¡Promete ahorrarte hasta el 95% de los tokens!
¿Cómo? Comprime tu contexto antes de enviarlo a la IA.
100% en local y compatible con Claude, Cursor, Codex...
24K estrellas en GitHub:
https://t.co/v4Ka8gmGV9
day 2 findings on this pipeline 🥹
> it works, got map@50=0.8028 on road sign detection against human annotations, with only 1.3k examples 🙌🏼 see results below
> Liquid rejects way more than Gemma-4 (530 vs 306 in hard document parsing, 1022 vs 116 in easy road sign detection, tbh it's smaller and more prone to hallucination when I vibe check)
> in some cases (see document media parsing examples below) trained RF-DETR outperforms Qwen annotations it was trained on which is super cool, sometimes judges introduce bboxes (and I don't remove them) it's a win? 😄
> multiple VLMs as judges will shrink your dataset depending on the difficulty of the problem, sometimes taking only one "correct" from a judge is enough. since you are training small models it's better to kickoff training for consensus and single correct verdict separately
> use super-specific prompts of what you want and don't want in labelling and judging especially if your labels as words could mean many things
next up: make this library leaner to generalize better to be problem-agnostic, try again on segmentation, actually use Gemma for orchestration
Crazy model! It actually uses the old Qwen2.5-Coder-3B stack and got really great performance with their post-training stack.
Need to use it in the next days to see if vibes of VibeCoder actually check out in practice. But impressive first impression!
Based on the tech report, some of the important pieces of their post-training stack:
1. High-signal synthetic data (math problems with credible solutions, code with tests)
2. Multiple reasoning paths for each answer
3. Filtering, filtering, filtering
4. 2-stage SFT (start with broad training, then train on hard long-reasoning samples)
5. Use target (pass@k) accuracy over validation loss for checkpoint selection
6. MGPO (MaxEnt-Guided Policy Optimization) for RLVR: basically a GRPO-style RL method with an extra weighting that favors examples that are neither too easy nor too hard for the current policy
7. Single 64k long-context RL (they found that the usual progressive context expansion hurt this model because early truncation damaged long-thinking behavior)
8. Training data order: they do Math RL, then Code RL, then STEM RL in this particular oder which they found helped overall
9. After optimizing for accuracy, they add a stage that rewards shorter correct trajectories; basically making the model more efficient without accuracy degradation
@pitiklinov Muy buenos ejemplos para conectar con el consenso manufacturado. Los medios tienen un modelo de negocio: Tener visitas para atraer anunciantes. Por lo tanto, publicarán contenido que defienda intereses de sus dueños, sus anunciantes y sus aliados políticos
https://t.co/5lGvHZ8vT9
Whether you are GPU poor or GPU rich, today's release of PyLate has something for you!
GPU maxxers: MaxSim kernels greatly speed up training while lowering the memory requirements
CPU enjoyers: TACHIOM enables lightning fast multi-vector indexing and search directly on CPU
One company trying to own the whole narrative of "we are the good boys, and we have the best models" is not
This morning I started working on some high-quality educational material to try to tilt the balance to the other side.
More open-weights, more open-source and more sovereign AI (that is the only way forward).
Vraiment n'importe quoi.
L'histoire du chercheur solitaire, isolé, et sans beaucoup de moyens s'applique aussi à moi au début de ma carrière.
Les frères Wright, les Lenoir, Benz, et Daimler étaient des innovateurs et bricoleurs de génie. Mais on parle de développement technologique, pas de recherche scientifique.
Elon s'inscrit effectivement dans une longue tradition: celle des capitaines d'industrie à qui on attribue, ou qui s'approprient, les innovations de leurs employés ou d'autres inventeurs: Thomas Edison, David Sarnoff (qui, comme Elon, a manipulé le marché pour augmenter la valeur de l'action de son entreprise), et bien d'autres.
Peut-être que le processus d'attribution de grants par la NSF est bureaucratique. Mais c'est pour qu'il soit transparent et libre de corruption et de conflits d'intérêts. Il est loin d'être parfait, mais beaucoup moins "bureaucratique" que les équivalents européens.
Si le tirás una prompt vaga a un agente, te escupe basura.
Y después culpamos a la IA.
El problema no es el modelo. Es la falta de proceso.
Subí un video mostrando Spec-Driven Development completo, de research a verify. No es prompt engineering. Es ingeniería de procesos.
La diferencia entre un junior con IA y un senior con IA no es la herramienta. Es el contexto. El junior le pide magia. El senior la dirige.
Tony Stark no le dice a Jarvis "haceme algo, flaco". Le da contexto, constraints, objetivos y feedback.
Video en comentarios.
#AI #SoftwareEngineering #AgenticEngineering
Both shipped for one reason: to help juniors and seniors actually use AI without burning out or burning tokens.
gentle-ai: you ask, it resolves. Correct workflows, token optimization and resource best practices, all automated. Agent-agnostic, works with whatever you use.
engram: MCP memory server with a queryable registry. Context survives across agents, and it searches the registry before re-reading code (massive token savings).
Hundreds of hours of open source grind. What made it worth it: messages from people saying these tools saved their job or helped them land one, and companies running both in production.
Built primarily with GPT 5.5 + different models for each SDD phase.
https://t.co/FQFSM2byAp
https://t.co/0dgeRTPwin
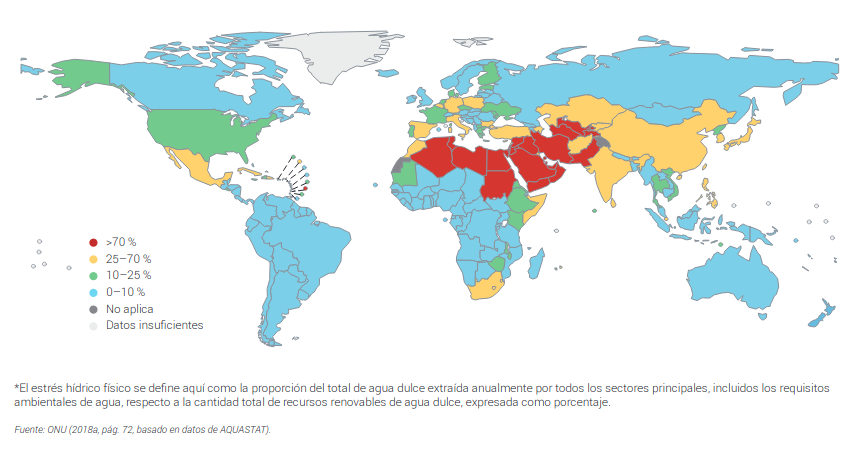
Solo alrededor del 0,5% del agua del planeta está disponible para el consumo humano.
El resto es salada o está atrapada en glaciares y polos.
Por ello el agua se está convirtiendo en una fuente de conflictos. A continuación te cuento los más importantes. DENTRO HILO. (1/7)
if you're using Replit, Antigravity or other vibe-building tools 👋🏻
simply adding @huggingface Skills to your setup gives your agent access to ~3M open models, 500k+ local AI apps and ~1M datasets
agent will pick and build with the best model for your use case and hardware
LinkedIn extrae información privada tuya y la envía a empresas de seguridad Israelíes
Microsoft y LinkedIn está llevando a cabo una de las mayores operaciones de espionaje corporativo de la historia moderna. Cada vez que alguno de los mil millones de usuarios de LinkedIn entra, un código oculto busca en su ordenador el software instalado, recopila los resultados y los transmite a los servidores de LinkedIn y a empresas externas, entre ellas una firma de ciberseguridad estadounidense-israelí. Al usuario nunca se le pregunta. Nunca se le informa. La política de privacidad de LinkedIn no lo menciona.
https://t.co/Y2Ht8sCusr
after over a year, happy to announce the 0.9.90 release of hyperscript
https://t.co/VjfFLhJEMY
includes: reactive sub-system by @scriptogre, a redone templating system by one of my students, morphing by @latent22, a component system & many, many more features
enjoy!
Local AI is free, fast & secure!
So today we're introducing hf-mount: attach any storage bucket, model or dataset from @huggingface as a local filesystem.
This is a game changer, as it allows you to attach remote storage that is 100x bigger than your local machine's disk. This is also perfect for Agentic storage!!
Let's go!
Durante años, Estados Unidos ha arrastrado el desgaste de conflictos interminables. Irak, Afganistán… guerras largas, costosas y difíciles de cerrar. Trump llegó con la promesa de romper con ese modelo. Su planteamiento era claro: nada de intervenciones prolongadas, nada de tropas sobre el terreno durante años. La alternativa era una nueva forma de hacer la guerra, basada en golpes rápidos, contundentes y desde la distancia.
La lógica parecía impecable. Utilizar la superioridad tecnológica para lanzar ataques precisos, destruir capacidades clave del enemigo, forzar una negociación y retirarse. Una estrategia que, en teoría, permitiría a Estados Unidos mantener su poder sin quedar atrapado en conflictos abiertos.
Sin embargo, la realidad está demostrando que este enfoque tiene límites muy claros. Porque una cosa es destruir infraestructuras o debilitar capacidades militares, y otra muy distinta es resolver el problema político que hay detrás de cada conflicto. Y ahí es donde empieza el verdadero problema.
Lo que estamos viendo en distintos escenarios es que, tras cada intervención, la amenaza no desaparece. Se debilita, se reorganiza, pero sigue existiendo. Y eso obliga a volver a intervenir. Irán es el ejemplo más evidente: ya fue atacado anteriormente y, sin embargo, el conflicto vuelve a escalar porque los objetivos iniciales no se han cumplido completamente. Lo mismo ocurre en Yemen, donde miles de ataques no han logrado eliminar la capacidad operativa de los hutíes, o en Siria e Irak, donde la presión militar constante no ha conseguido erradicar definitivamente a los grupos terroristas.
De este modo, lo que se planteaba como una estrategia de intervenciones puntuales se transforma en una dinámica de ataques recurrentes. No hay una guerra formal con despliegue masivo de tropas, pero tampoco hay una verdadera salida del conflicto. Es una implicación continua, fragmentada en el tiempo, pero permanente en la práctica.
Ahí es donde aparece la gran contradicción. Trump quería evitar las guerras eternas, pero su modelo está generando una nueva versión de las mismas. No son guerras de ocupación, sino guerras de repetición. Cada vez que el problema reaparece, la respuesta vuelve a ser la misma: un nuevo ataque.
Además, cuanto más ambiciosos son los objetivos —como debilitar completamente a un régimen o eliminar una amenaza de raíz— más evidente se vuelve que este tipo de estrategia es insuficiente. Esos objetivos no se alcanzan únicamente con bombardeos o ataques a distancia. Y eso aumenta el riesgo de que, en algún momento, la presión obligue a escalar el conflicto y a plantear intervenciones más profundas, justo lo que se quería evitar desde el principio.
Mientras tanto, el impacto ya se deja sentir en otro frente clave: el económico. Este tipo de conflicto, sin un horizonte claro de resolución, mantiene la incertidumbre en niveles elevados. El mercado energético sigue tensionado, los precios reaccionan a cada escalada y la inflación encuentra nuevas razones para mantenerse elevada. Es un entorno que dificulta la estabilidad y complica la toma de decisiones tanto para gobiernos como para bancos centrales.
Al final, la idea de una guerra sin compromiso choca con la complejidad del mundo real. Porque puedes diseñar una estrategia para entrar y salir rápidamente, pero no puedes controlar cómo evoluciona el conflicto una vez comienza. Y cuando los objetivos no se cumplen del todo, la tentación —o la necesidad— de volver a intervenir se convierte en inevitable.
La lección es sencilla, aunque incómoda: puedes decidir cómo empiezas una guerra, pero no cómo termina.