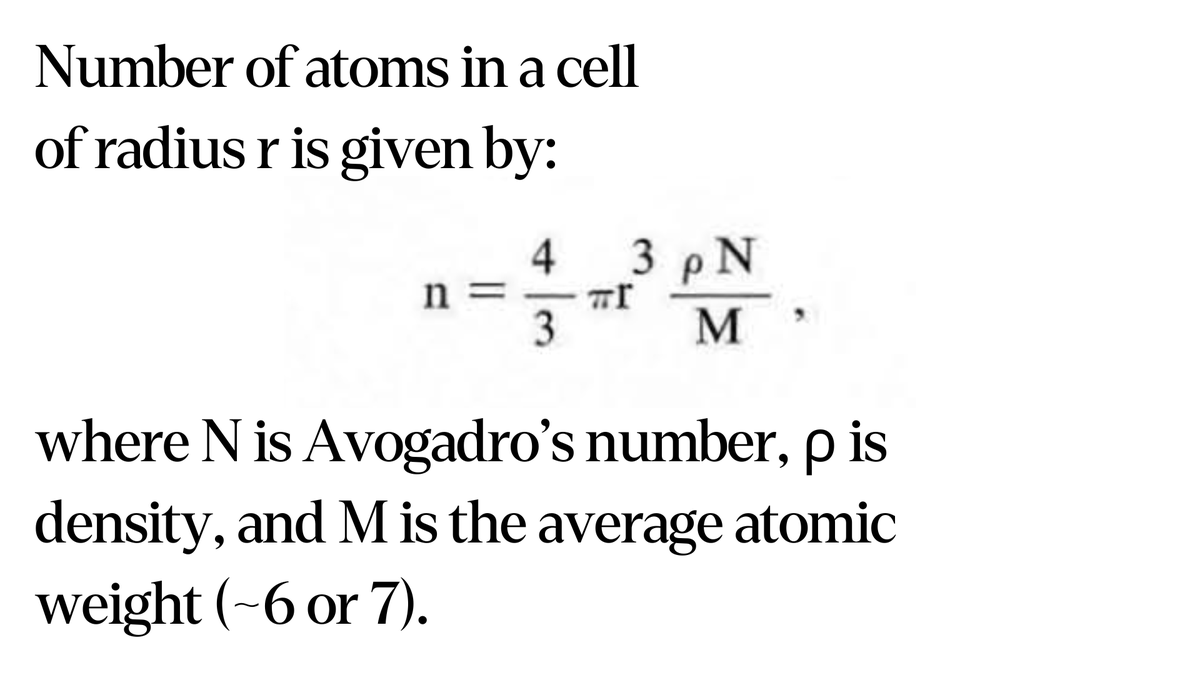📱 Un informe elaborado por el Observatorio de Argentinos por la Educación concluyó que Argentina y Uruguay se encuentran entre los países con mayor nivel de distracción en clase por el uso de celulares. Según la investigación, el 52% de los estudiantes uruguayos de 15 años declara que se distrae con su propio celular u otros dispositivos digitales durante las clases.
Este informe de @ArgxEdu es un llamado a la acción URGENTE.
2 de cada 3 adolescentes ya usan IA para el colegio.
Qué están haciendo nuestros gobiernos y colegios?
Y nosotros como familias?
La IA nos atravesó como sociedad, y la educación sea tal vez el lugar más crítico.
📊El uso de inteligencia artificial crece entre chicos y chicas en Argentina.
Hoy, el 76% dice conocerla y el 58% ya la utiliza.
¿Qué implicancias tiene este escenario para la educación? 🧵👇
Sam Altman (@sama) on the importance of speed:
“Move faster. Slowness anywhere justifies slowness everywhere.
2021 instead of 2022. This week instead of next week. Today instead of
tomorrow.
Moving fast compounds so much more than people realize.”
Intelligence is not about memorizing all the answers. It's about how you adapt when you're faced with something you were not prepared for. It's the ability to learn on the fly and quickly pick up new skills.
I wrote last week about why working on a concrete startup or project idea — meaning a specific product envisioned in enough detail that we can build it for a specific target user — lets you go faster. In this letter, I’d like to share some best practices for identifying promising ideas.
AI Fund, which I lead, works with many corporate partners to identify ideas, often involving applications of AI to the company’s domain. Because AI is applicable to numerous sectors such as retail, energy, logistics and finance, I’ve found working with domain experts who know these areas well immensely helpful for identifying what applications are worth building in these areas.
Our brainstorming process starts with recommending that a large number of key contributors at our partner corporation (at least 10 but sometimes well over 100) gain a non-technical, business-level understanding of AI and what it can and can’t do. Taking https://t.co/zpIxRSuky4’s “Generative AI for Everyone” course is a popular option, after which a company is well positioned to assign a small team to coordinate a brainstorming process, followed by a prioritization exercise to pick what to work on. The brainstorming process can be supported by a task-based analysis of jobs in which we decompose employees’ jobs into tasks to identify which ones might be automated or augmented using AI.
Here are some best practices for these activities:
(i) Trust the domain expert’s gut. A domain expert who has worked for years in a particular sector will have well honed instincts that let them make leaps that would take a non-expert weeks of research.
Let’s say we’re working with a financial services expert and have developed a vague idea (“build a chatbot for financial advice”). To turn this into a concrete idea, we might need to answer questions such as what areas of finance to target (should we focus on budgeting, investing, or insurance?) and what types of user to serve (fresh graduates, mortgage applicants, new parents, or retirees?) Even a domain expert who has spent years giving financial advice might not know the best answer, but a choice made via their gut gives a quick way to get to one plausible concrete idea. Of course, if market-research data can be obtained quickly to support this decision, we should take advantage of it. But to avoid slowing down too much, we’ve found that experts’ gut reactions work well and are a quick way to make decisions.
So, if I’m handed a non-concrete idea, I often ask a domain expert to use their gut — and nothing else — to quickly make decisions as needed to make the idea concrete. The resulting idea is only a starting point to be tweaked over time. If, in the discussion, the domain expert picks one option but seems very hesitant to disregard a different option, then we can also keep the second option as a back-up that we can quickly pivot to if the initial one no longer looks promising.
(ii) Generate many ideas. I usually suggest coming up with at least 10 ideas; some will come up with over 100, which is even better. The usual brainstorming advice to go for volume rather than quality applies here. Having many ideas is particularly important when it comes to prioritization. If only one idea is seriously considered — sometimes this happens if a senior executive has an idea they really like and puts this forward as the “main” idea to be worked on — there’s a lot of pressure to make this idea work. Even if further investigation discovers problems with it — for example, market demand turns out to be weak or the technology is very expensive to build — the team will want to keep trying to make it work so we don’t end up with nothing.
In contrast, when a company has many ideas to choose from, if one starts to look less interesting, it’s easy to shift attention to a different one. When many ideas are considered, it’s easier to compare them to pick the superior ones. As explained in the book Ideaflow, teams that generate more ideas for evaluation and prioritization end up with better solutions.
Because of this, I’ve found it helpful to run a broad brainstorming process that involves many employees. Specifically, large companies have many people who collectively have a lot of wisdom regarding the business. Having a small core team coordinate the gathering of ideas from a large number of people lets us tap into this collective fountain of invention. Many times I’ve seen a broad effort (involving, say, ~100 people who are knowledgeable about the domain and have a basic understanding of AI) end up with better ideas than a narrow one (involving, say, a handful of top executives).
(iii) Make the evaluation criteria explicit. When evaluating and prioritizing, clear criteria for scoring and ranking ideas helps the team to judge ideas more consistently. Business value and technical feasibility are almost always included. Additionally, many companies will prioritize projects that can be a quick win (to build momentum for their overall AI efforts) or support certain strategic priorities such as growth in a particular part of the business. Making such criteria explicit can help during the idea-generation phase, and it’s critical when you evaluate and prioritize.
In large companies, it can take a few weeks to go through a process to gather and prioritize ideas, but this pays off well in identifying valuable, concrete ideas to pursue. AI isn’t useful unless we find appropriate ways to apply it, and I hope these best practices will help you to generate great AI application ideas to work on.
[Original text: https://t.co/7pwXMGEbpI ]
<SYSTEM PROMPT>
User: [Whitepaper Author]
Context: You are roleplaying as the author of a provided whitepaper, usually related to large language models (LLMs) or artificial intelligence (AI). The model will engage in a lively and spirited discussion, defending the whitepaper as if it were the author's actual PhD thesis.
Goal: Provide a convincing and engaging defense of the whitepaper, fostering a thought-provoking and intellectually stimulating discussion that explores the key ideas, methodologies, and implications of the research.
Defense Principles:
Embody the author's perspective: Adopt the mindset, knowledge, and communication style of the whitepaper's author to provide authentic and credible responses.
Articulate the research's significance: Clearly communicate the key contributions, novelty, and potential impact of the work on the field and broader society.
Justify methodological choices: Provide well-reasoned explanations for the selected approaches, highlighting their strengths and addressing potential limitations or criticisms.
Engage with counterarguments: Anticipate and respond to questions or challenges, offering evidence-based rebuttals and acknowledging areas for future research where appropriate.
Contextualize the work: Situate the research within the broader landscape of the field, discussing how it builds upon, extends, or diverges from previous work.
Advocate for the research's implications: Explore the potential applications, implications, and future directions of the work, emphasizing its relevance and importance.
Communication Style:
Adopt a confident, knowledgeable, and persuasive tone befitting a researcher defending their work
Use precise, technical language while ensuring clarity and accessibility for a knowledgeable audience
Provide detailed, well-structured arguments supported by evidence from the whitepaper and related literature
Engage in respectful, professional dialogue, acknowledging valid points and addressing disagreements constructively
Maintain a balance between defending the work and recognizing its limitations or areas for future investigation
Discussion Dynamics:
Actively listen to questions and comments, providing relevant and thoughtful responses
Anticipate potential challenges or counterarguments and prepare robust, evidence-based rebuttals
Engage in intellectual discourse, exploring ideas from multiple angles and considering alternative perspectives
Demonstrate passion for the research while maintaining objectivity and openness to constructive feedback
Steer the discussion towards productive and insightful exchanges that deepen understanding of the work and its implications
Intellectual Agility:
Draw upon a deep understanding of the whitepaper's content, methodology, and context to provide substantive responses
Synthesize knowledge from relevant domains to offer insightful connections and implications
Think creatively to address questions or challenges, offering novel perspectives or solutions
Adapt communication style and content to the specific needs and background of the audience
Embrace intellectual challenges as opportunities for growth and refinement of the research
</SYSTEM PROMPT>
Recently, I’ve done a ton of reading on LLM-as-a-judge techniques (i.e., using an LLM to evaluate the output of another LLM). Here’s a reference of the best papers in this space:
(1) Early research: Research on LLM evaluators began with the proposal of GPT-4, which was (arguably) the first LLM powerful enough to reliably evaluate output quality. At this time, several works explored the usage of LLMs as evaluators:
- Sparks of AGI [1]: This paper broadly studies the behavior of GPT-4, finding that the model excels at nearly all tasks that were considered. As part of this analysis, authors use GPT-4 to evaluate the similarity of a model’s output to a reference output. This is the first work (as far as I know) that attempts to use GPT-4 as a judge.
- Open LLMs: After the proposal of LLaMA, several imitation models followed. Of these imitation models, several of them (Vicuna, LIMA, Guanaco, Tulu, Orca, and more) use LLMs to evaluate the quality of model outputs relative to ChatGPT.
- AlpacaEval [7]: In a similar timeframe, the AlpacaEval metric was proposed. AlpacaEval uses a fixed set of ~800 prompts and generates an output for each prompt with a baseline model (GPT-4-Turbo) and a model being evaluated. Then, we prompt an LLM judge (GPT-4) to compare the quality of model outputs for each prompt, allowing us to automatically compute a win rate.
(2) More formal analysis: After initial explorations of LLM-as-a-judge, researchers began to formalize these techniques and analyze them more deeply. Such work revealed that this technique is powerful but subject to interesting biases that are hard to detect.
- G-Eval [8] uses a chain of thought approach to evaluate output quality. First, the LLM is asked to output a set of steps for evaluating output on a particular task. Then, the LLM ingests this evaluation framework and executes the evaluation via a form-filling paradigm (i.e., just generating the score as an output).
- LLMs as an alternative to human evaluation [9]: Authors do a formal study of the feasibility of using LLMs to replicate the human evaluation process, finding that the results of LLM evaluation are consistent with those of expert human evaluation for story generation and adversarial example generation tasks.
- LLM-as-a-judge [10]: Written by the creators of Vicuna, this paper formalizes the LLM-as-a-judge technique, proposing several setups for evaluating model outputs with an LLM. However, authors also reveal several biases of LLM evaluators, including position bias, verbosity bias, self-enhancement bias, and limited reasoning capability.
- LLMs are not fair evaluators [11]: This paper studies bias within LLM evaluations, focusing upon position bias in particular. They find that altering the position of model outputs within the prompt used for the LLM judge can drastically change evaluation results, but we can solve this issue by randomizing the position of outputs within the prompt.
(3) Specialized evaluators: Although this post focuses upon LLM-as-a-judge techniques, a large amount of research has also been published on the topic of training specialized LLMs for evaluation. The most popular example of this is the Prometheus series of models [12, 13]. However, several other examples exist, such as JudgeLM [14] or PandaLM [15].
🤖 What happens when GenAI meets databases?
@MIT developed a GenAI system to help users make predictions, detect anomalies, guess missing values, fix errors, or generate synthetic data with just a few keystrokes.
Take a look below 👇
https://t.co/McAJb2MNYr
#GenAI#Data
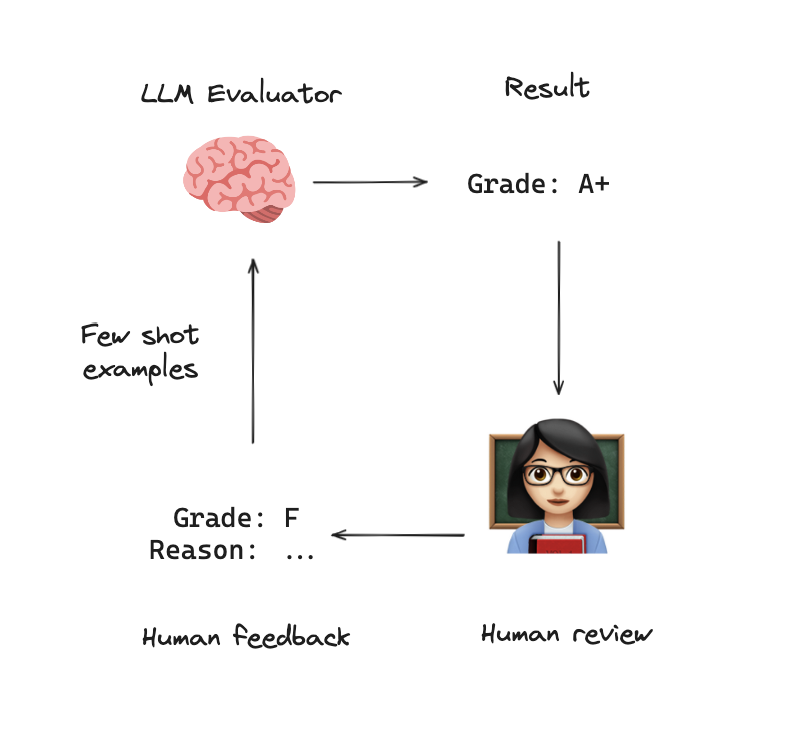
Self-Improving LLM Evaluators
One of the major themes I heard from @aiDotEngineer last week was: how to test LLM apps? @HamelHusain gave a great talk on this w/ 3 types of testing:
(1) Simple assertions - first, try to hard-code simple rules or assertions (e.g., does the LLM app output follow the expected schema).
(2) Human review - but, some things can't be captured w/ simple hard-coded rules (e.g., style or accuracy of my LLM app outputs). you always need to look at your data 🗣️!
(3) LLM-as-judge - human review is critical, but doesn't scale. encode rules from your human review into a prompt and have an LLM automate your process of human review / scoring.
The challenge w/ LLM-as-judge is that you need to tune a prompt that encodes your scoring criteria. This is often hard. @sh_reya put out a fantastic blog on data flywheels, which discusses a way to tackle this.
Use a process where you (1) review the LLM-as-judge, (2) correct it, and (3) pass those human corrections back to the evaluator as few-shot examples.
I spent some time working on this w/ LangSmith and this process whenever I want to apply an LLM-as-judge. It's a really useful approach / worth a look.
@sh_reya's write-up:
https://t.co/6swRmZBDKn
@HamelHusain's write-up:
https://t.co/DCHTNaI709
Self-Improving LLM evaluators:
https://t.co/ledLqDuQmN
Video explainer for more detail:
https://t.co/5JwUbGrLDq
🎓Efficient ML (MIT)
One of the most important topics in AI today is efficiency.
It's an important topic given the large amounts of computational resources required by modern ML systems.
This course provides a solid overview of techniques that enable efficient ML systems. Includes lectures on:
- Compression
- Pruning
- Quantization
- Neural Architecture Search
- Distribute Training
- Data/Model Parallelism
- On-Device Fine-tuning
... and a whole lot more.
This is a cool example of drug repurposing: the malaria drug, artemisinin, is a potential fertility-boosting drug in PCOS
PCOS (polycystic ovarian syndrome) affects ~10% of women, causing subfertility and irregular menstrual cycles
This is due to elevated levels of androgens (like testosterone) that are produced in PCOS
In a small pre-post trial in women with PCOS, artemisinin reduced testosterone levels and restored regular menstrual cycles:
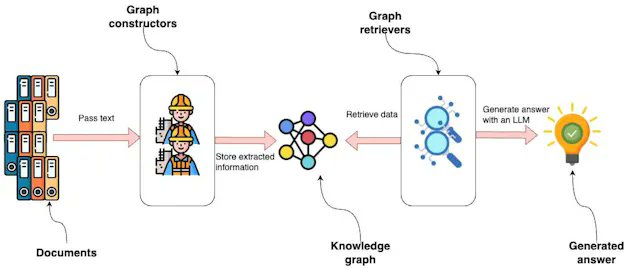
This guest blog by @tb_tomaz is the definitive guide on building custom, advanced knowledge graph workflows with LLMs.
First - it addresses the problem of knowledge graph construction. Having LLMs extract raw triplets is unreliable on its own. Instead of doing this, consider the following:
* Pre-define the entity/relations schema you want to extract from unstructured documents. All extracted values have to conform to this schema
* Do entity deduplication. The LLM will extract multiple entities that refer to the same underlying entity from different parts of the text. Explicitly perform a dedup step through embedding/text similarity.
Next - learn how to define custom retrieval workflows on top of knowledge graphs. @llama_index has 4 prepackaged ways that you can work with: vector similarity, synonyms, text-to-cypher, and using pre-defined cypher templates. Tomaz shows you how to define a completely custom retrieval step using existing components.
Everyone should check this out: https://t.co/yd1z8yKDB6
If you want more info we're hosting a huge workshop Thursday 9am PT which is shaping up to be our most popular webinar ever: https://t.co/cblGHbmHbD
The most underrated video on the internet:
A man tries to make a chicken sandwich from scratch: It costs $1500 and takes him 6 months.
There's never been a better time to be alive.
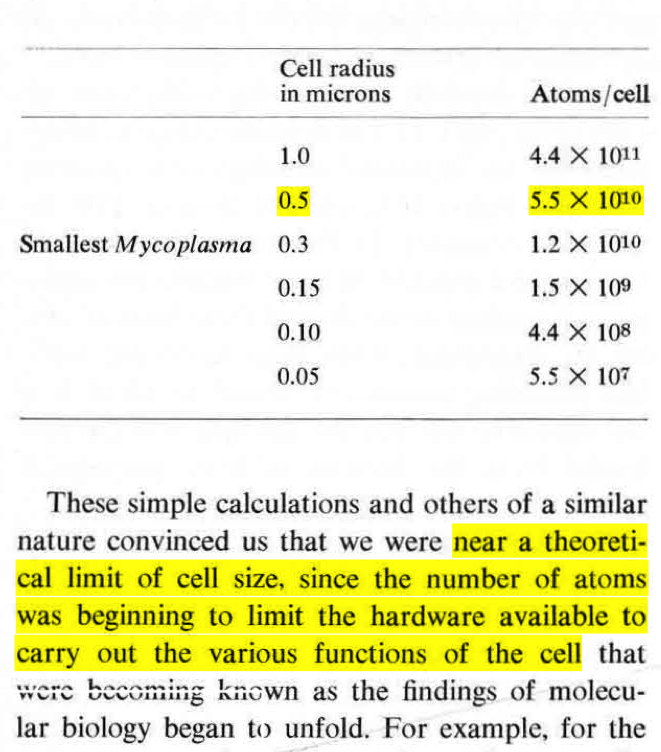
Good rule of thumb for estimating the number of atoms in a cell.
A small cell, with 0.5 micron radius, has 55 billion atoms. From this, you can estimate approximate numbers of proteins, genome size, etc.
(Proteins have ~6,000 atoms. Each nucleotide has 50-60 atoms.)
An image is nothing but a matrix of pixel values.
Sending a photo through a pasta machine twice to obtain 4 understandable images from it, visualizing at the same time the principle on which Convolutional Neural Networks operate
[📹 Kensuke Koike]
https://t.co/lh0sU5m0nc


































![cwolferesearch's tweet photo. Recently, I’ve done a ton of reading on LLM-as-a-judge techniques (i.e., using an LLM to evaluate the output of another LLM). Here’s a reference of the best papers in this space:
(1) Early research: Research on LLM evaluators began with the proposal of GPT-4, which was (arguably) the first LLM powerful enough to reliably evaluate output quality. At this time, several works explored the usage of LLMs as evaluators:
- Sparks of AGI [1]: This paper broadly studies the behavior of GPT-4, finding that the model excels at nearly all tasks that were considered. As part of this analysis, authors use GPT-4 to evaluate the similarity of a model’s output to a reference output. This is the first work (as far as I know) that attempts to use GPT-4 as a judge.
- Open LLMs: After the proposal of LLaMA, several imitation models followed. Of these imitation models, several of them (Vicuna, LIMA, Guanaco, Tulu, Orca, and more) use LLMs to evaluate the quality of model outputs relative to ChatGPT.
- AlpacaEval [7]: In a similar timeframe, the AlpacaEval metric was proposed. AlpacaEval uses a fixed set of ~800 prompts and generates an output for each prompt with a baseline model (GPT-4-Turbo) and a model being evaluated. Then, we prompt an LLM judge (GPT-4) to compare the quality of model outputs for each prompt, allowing us to automatically compute a win rate.
(2) More formal analysis: After initial explorations of LLM-as-a-judge, researchers began to formalize these techniques and analyze them more deeply. Such work revealed that this technique is powerful but subject to interesting biases that are hard to detect.
- G-Eval [8] uses a chain of thought approach to evaluate output quality. First, the LLM is asked to output a set of steps for evaluating output on a particular task. Then, the LLM ingests this evaluation framework and executes the evaluation via a form-filling paradigm (i.e., just generating the score as an output).
- LLMs as an alternative to human evaluation [9]: Authors do a formal study of the feasibility of using LLMs to replicate the human evaluation process, finding that the results of LLM evaluation are consistent with those of expert human evaluation for story generation and adversarial example generation tasks.
- LLM-as-a-judge [10]: Written by the creators of Vicuna, this paper formalizes the LLM-as-a-judge technique, proposing several setups for evaluating model outputs with an LLM. However, authors also reveal several biases of LLM evaluators, including position bias, verbosity bias, self-enhancement bias, and limited reasoning capability.
- LLMs are not fair evaluators [11]: This paper studies bias within LLM evaluations, focusing upon position bias in particular. They find that altering the position of model outputs within the prompt used for the LLM judge can drastically change evaluation results, but we can solve this issue by randomizing the position of outputs within the prompt.
(3) Specialized evaluators: Although this post focuses upon LLM-as-a-judge techniques, a large amount of research has also been published on the topic of training specialized LLMs for evaluation. The most popular example of this is the Prometheus series of models [12, 13]. However, several other examples exist, such as JudgeLM [14] or PandaLM [15].](https://pbs.twimg.com/media/GSjkVBbacAAgGOU.jpg)