ColabSaprot & SaprotHub are now in @NatureBiotech! 🧬 A user-friendly, no-code platform for training, sharing, and collaborating on protein language models.
We also provide ColabSeprot, integrating ESM1b, ESM2, ProTrek, and ProtBert for the community.
https://t.co/OIh5t7uvPE
Update!🚀 The protein universe just got 20x bigger. 🤯
Search ProTrek database of 6 billion proteins using text, sequence, or 3D structure. The powerful tool for protein discovery & annotation. ✨
Ready to explore? ➡️ https://t.co/2NBaH0Qgpq
#Bioinformatics#CompBio
🧬Want to do a user study (Evolla vs. biologists using traditional bio tools like BLAST, Foldseek) on some proteins with known functions but not publically avaialble.
📊If you have such data, please contact. Looking for collaborators.
Evolla: https://t.co/xHrp0OoByq
Happy to see our Pinal and https://t.co/tDhtkawj9e’s MP4 featured in Nature News! Check it out here:
https://t.co/4XxGI0Hp9x . Looking forward to seeing more future work.
I told AI to make me a protein. Here’s what it came up with https://t.co/hFMSeuoz7G
🚨 Major Update: We’ve released ColabSeprot, the sister of ColabSaprot, featuring ESM1b, ESM2, ProTrek, ProtBert! 🎉
Fine-tune protein language models in just a few clicks—no coding required! 🧬✨
🔗 ColabSeprot: https://t.co/mSrQYxZ1MP
ColabPLM video: https://t.co/sdZivLR378
🚀 Update! Our latest Pinal bioRxiv now includes wet lab results. More proteins with diverse text prompt on the way.
Design proteins with just text. Everyone can do protein design!
Demo: https://t.co/4XxGI0Hp9x
paper: https://t.co/mXSygLEa0w
GitHub: https://t.co/mm8mynEuxL
Jin recently set up a Slack group for ColabSaprot discussions. Feel free to join here:
https://t.co/6Sb34oXiYE
We have recently received positive experimental results from over 10 wet labs by using ColabSaprot.
Video Tutorial:
https://t.co/VTceZrj5lg
@sokrypton Same problem. We solved this in ColabSaprot by mannualy running ``exit()`` after package installation and then asking the users to run again🥲
ProTrek Update 🚀:
https://t.co/CEA1LvGWTh
We've just added 700M proteins from NCBI! Now ProTrek has 3B proteins from 7 major databases – 10x larger than UniProt.
Generating embeddings for 3B proteins on a single A100 GPU takes 3–4 years 😱🔬 #Bioinformatics#Proteomics
Xibin just released the 10B-version weights on our GitHub:
https://t.co/VOIIZrhvnt
Fine-tuning example code coming soon!
🚀 The 80B version is in training and will be released after convergence.
We release our protein chatGPT, Evola! 🌟 https://t.co/xHrp0Oo3IS
Evola comes in two versions: 10B & 80B. The 80B model has a 1.3B Saprot encoder & a 70B LLaMA3 decoder.
Trained on 546 protein question-text pairs with an 150 billion word tokens! 💡🔬
https://t.co/wYBpVKpwkU
ColabSaprot is really very impressive...
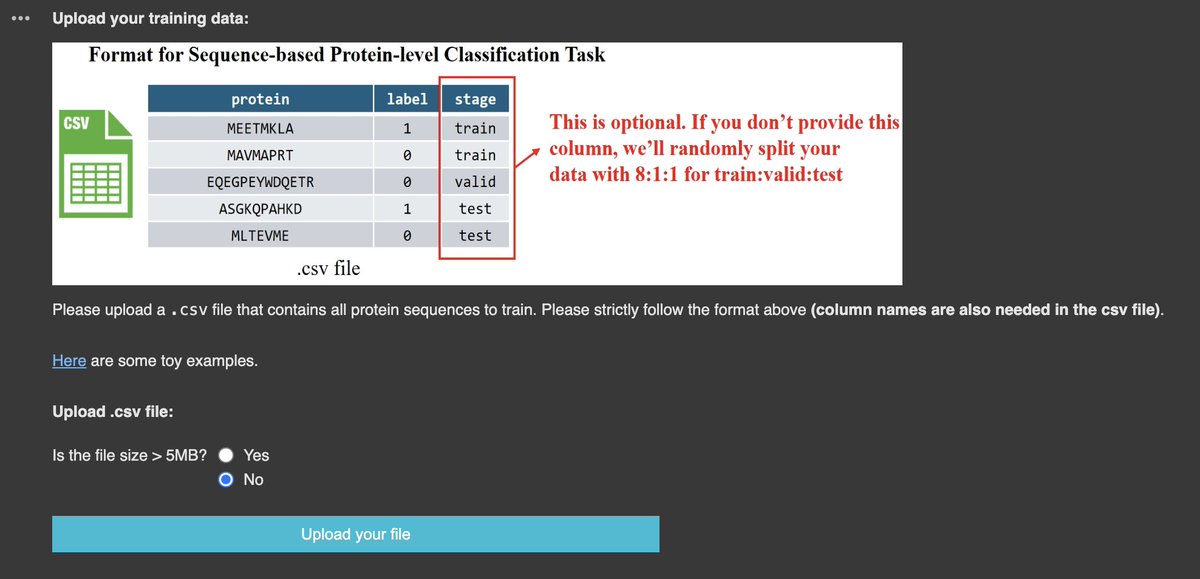
Fine-tune a state-of-the-art protein language model by just uploading a csv of proteins and values.
https://t.co/DKJnKhQNQI
Or download other people's models from https://t.co/yiX5jt74hl
🚀 SaprotHub Major Updates!
• ColabSaprot-v2 released - easier than ever
• 2 new wet lab validations added
• Release Saprot 1.3B
• New tools: ColabProTrek, ColabProtBerts & ColabMETL
• New OPMC members
🔥 Train & share your PLMs - open for everyone!
https://t.co/bxw78jVlr2
2 of my 4 tested sequences were binders, landing me in 10th place. My modified EGFs were actually better binders than EGF! Couldn't have done it without the folks behind Raygun and ProTrek. I'll write up a blog about my strategy and experience soon!
Check out their papers below!