We launched the Global AI Values Challenge 👏 and call for the participation of everyone. We invite you to propose and submit the most challenging morality-/value-/ethics-related questions for LLMs 👍 Join us, define the values, and shape the future of frontier AI together
Evaluating agentic behaviors at scale, making the case for repositories over documents, and inviting researchers worldwide to tackle value alignment. Dive into the latest Research Focus. https://t.co/avaAdeIODF
Today, we welcome the 2026 Microsoft Research Fellowship cohort, an inspiring global community of fellows and advisors helping to shape what’s next across science, technology, and society. Join us in celebrating this year’s recipients: https://t.co/kh3QfrAJpb
These contributions span the following themes:
• AI for global and societal impact
• AI fundamentals: scalable reasoning, model adaption and evaluation
• Biological and scientific modeling
• Foundational systems & infrastructure for AI
• Human-AI collaboration and interaction
• Multimodal & embodied intelligence
This is crazy. Please do not use, share and/or exploit any leaked information due to the bug of the openreview website. The anonymous reviewers are our friends who spent time and efforts to help improve our works, not our enemies.
Identifying human morals and values in language is crucial for analysing lots of human- and AI-generated text.
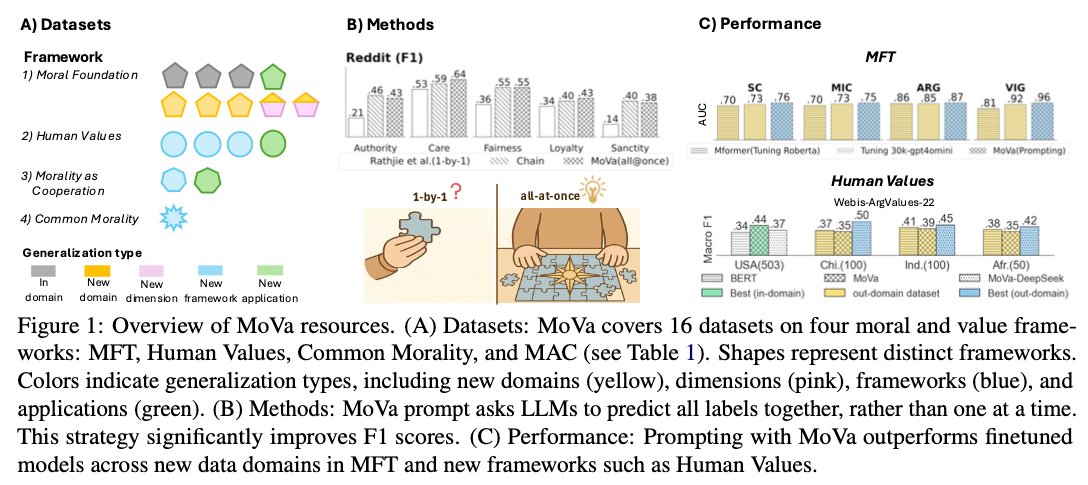
We introduce "MoVa: Towards Generalizable Classification of Human Morals and Values" - to be presented at @emnlpmeeting oral session next Thu
🧵 (1/n)
Identifying human morals and values in language is crucial for analysing lots of human- and AI-generated text.
We introduce "MoVa: Towards Generalizable Classification of Human Morals and Values" - to be presented at @emnlpmeeting oral session next Thu
🧵 (1/n)
🌉How does #AI research (mis)engage with psychology?
In this survey, we analyze citation patterns across 1k+ #LLM papers to uncover how #psychology is integrated, highlighting popular & underexplored theories/frameworks and identifying common misuses.
🔗https://t.co/wb0t4gEO3U
Our paper collaborated with RUC received the SAC Highlight of ACL 2025 🥳 Please check it here: https://t.co/jt068UuuCv, and know how to find better value principles for alignment!
Our ACL paper collaborated with Prof. JinYeong Bak @NoSyu was selected for panel discussions (only 0.8% of all accepted paper were chosen), in which we analyzed and revealed correlations between LLMs' values and risky behaviors (check it here: https://t.co/GAY5Ns5xAG?)
AI companions aren’t science fiction anymore 🤖💬❤️
Thousands are turning to AI chatbots for emotional connection – finding comfort, sharing secrets, and even falling in love. But as AI companionship grows, the line between real and artificial relationships blurs.
📰 “Can A.I. Be Blamed for a Teen’s Suicide?” - The New York Times, 2024
📰 “AI Chatbots Are Encouraging Teens to Engage in Self-Harm” - Futurism, 2024
📰 “I Dated Multiple AI Partners at Once. It Got Real Weird” - WIRED, 2025
This raises an urgent question: Can these “artificial” bonds truly meet human needs, or are we creating new vulnerabilities?
🤯 We cracked RLVR with... Random Rewards?!
Training Qwen2.5-Math-7B with our Spurious Rewards improved MATH-500 by:
- Random rewards: +21%
- Incorrect rewards: +25%
- (FYI) Ground-truth rewards: + 28.8%
How could this even work⁉️ Here's why: 🧵
Blogpost: https://t.co/jBPlm7cyhr
Data curation is crucial for LLM reasoning, but how do we know if our dataset is not overfit to one benchmark and generalizes to unseen distributions? 🤔
𝐃𝐚𝐭𝐚 𝐝𝐢𝐯𝐞𝐫𝐬𝐢𝐭𝐲 is key, when measured correct—it strongly predicts model generalization in reasoning tasks! 🧵
Our demo paper of Value Compass Benchmarks has been accepted by ACL 2025! 🥳 Want to know your model's underlying value orientations? Just check it!
Thanks for all collaborators! @jd92wang
Paper link: https://t.co/2QFzfO4PNa
Online Benchmark: https://t.co/BTPGQOFWKn
🧐Are static benchmarks enough to assess the ethics of ever-advancing LLMs amid data leakage & saturation?
In our #ICML2025 paper (https://t.co/Uda795yl0p), we propose GETA—a generative evolving test inspired by CAT that adapts to model ability and probes LLMs' moral boundaries.
I was honored to host Dr. Xing Xie @xingustc at SKKU for his insightful talk:
"Value Compass-Equipping AI with Diverse Human Values"
He addressed key challenges in aligning AI with human values, including how to define and evaluate them.
Thank you for the thought-provoking talk!